在很长一段时间里,AI圈流行着一种近乎迷信的认知:大力出奇迹。想要更强的推理能力?加参数。想要看懂更复杂的图表?加参数。仿佛只要把显卡堆满,模型就能产生神迹。
但就在2026年开年,阶跃星辰(StepFun)甩出的这张王炸——Step3-VL-10B,狠狠地给了“参数至上论”一记耳光。
这就好比在一场重量级拳击赛里,一个轻量级选手不仅抗住了重量级拳王的进攻,还反手把对方KO了。这款仅有100亿参数的模型,在多项核心指标上,硬生生按住了参数量是它10倍甚至20倍的对手。
小身板里的怪兽级性能
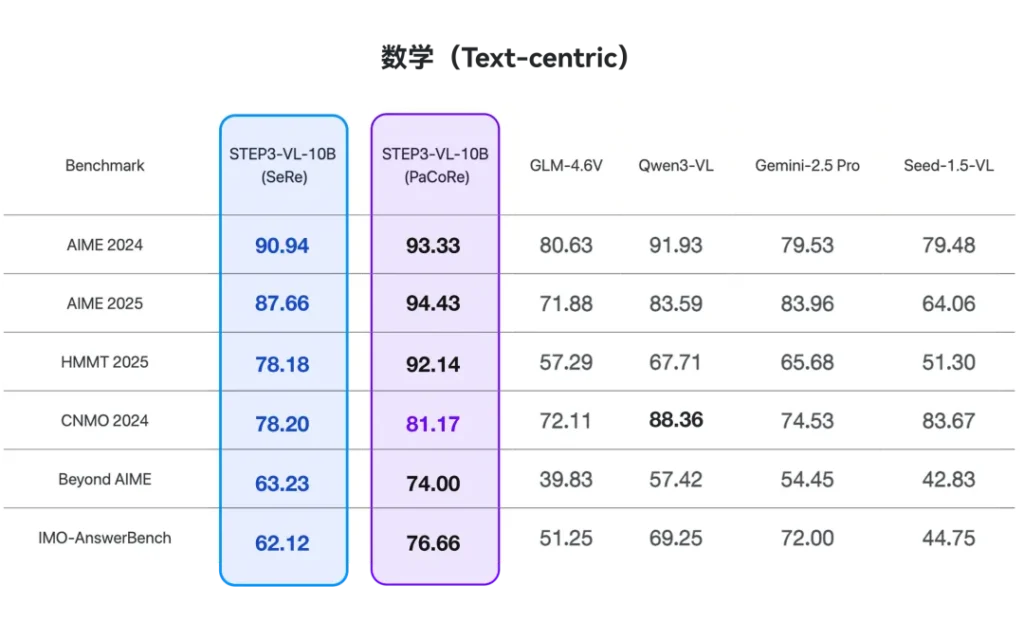
咱们先不谈虚的,直接看数据。
通常来说,10B级别的模型只能算是“甜点级”,用来做做简单的对话或者跑在笔记本上玩玩。但Step3-VL-10B拿出的成绩单简直不讲武德。
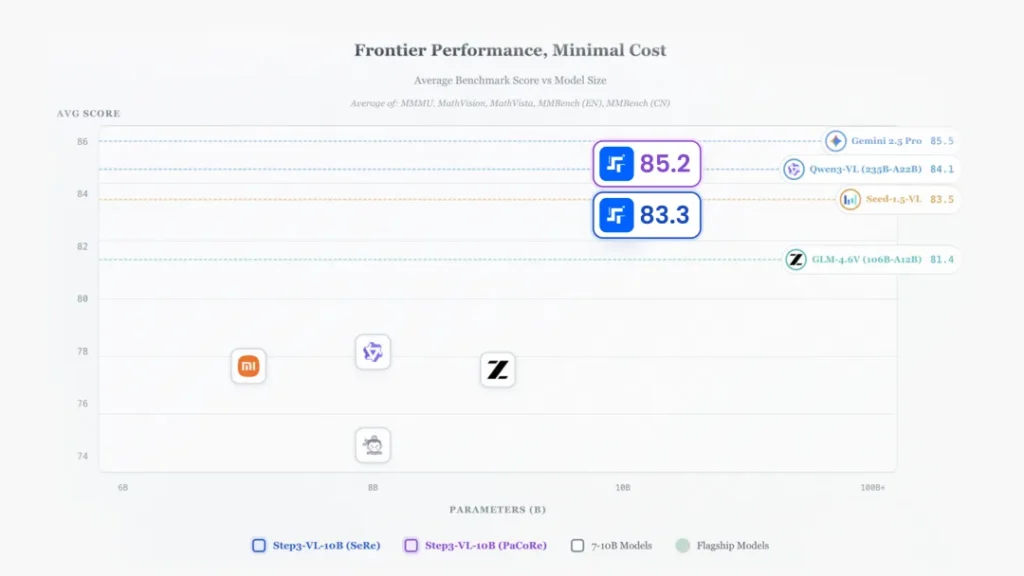
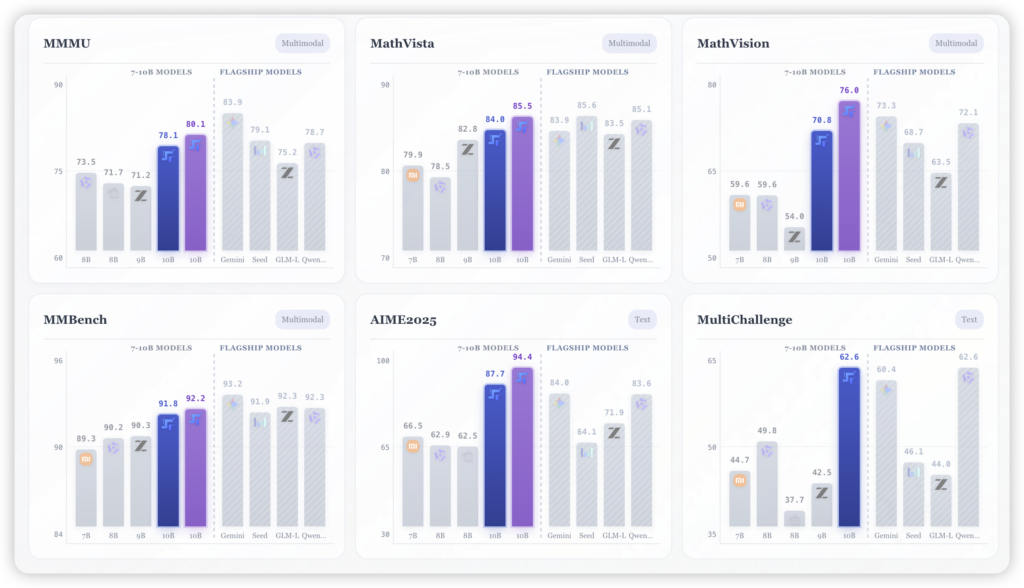
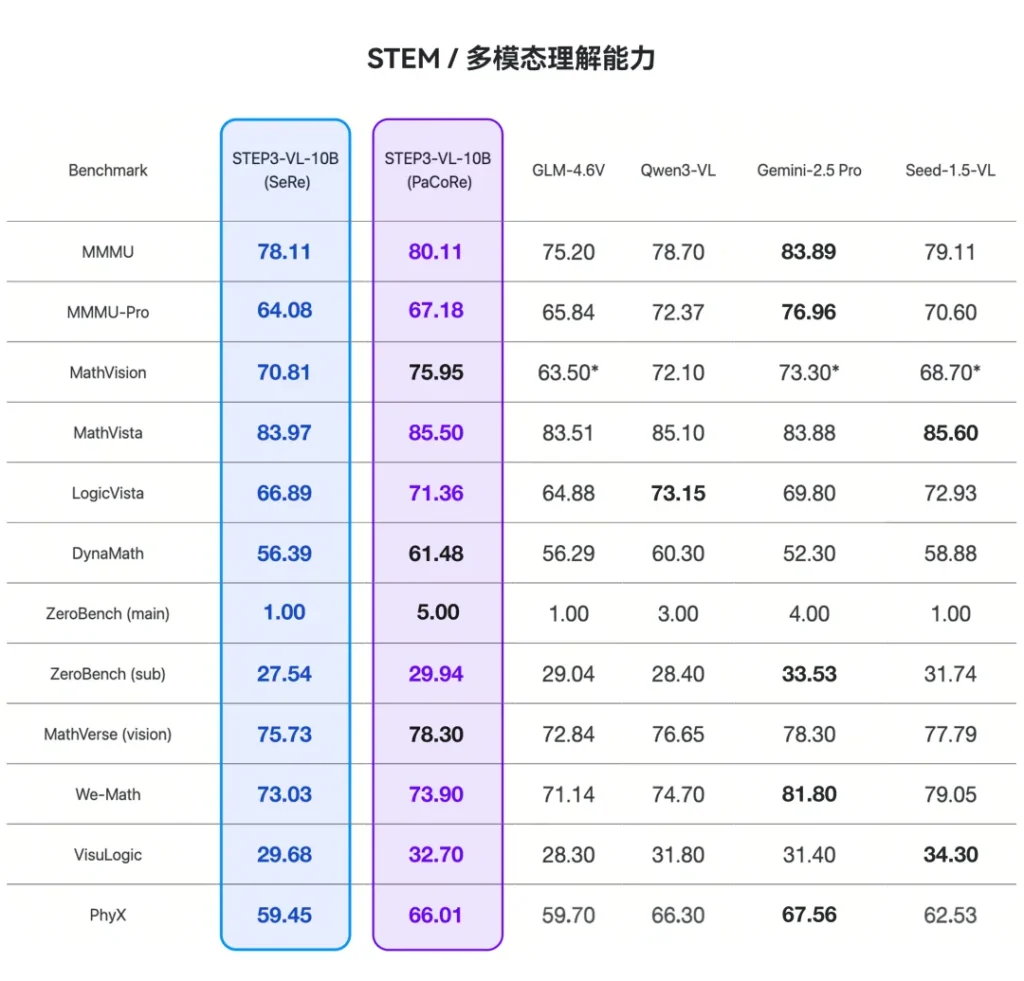
在数学竞赛基准AIME 2025上,它拿下了94.43%的高分。作为对比,Qwen3-VL(235B参数)和Gemini 2.5 Pro这种巨无霸都在它身后吃灰。在考察STEM综合能力的MMMU评测中,它也以80.11%的成绩超越了GLM-4.6V(106B)。
这不仅是“越级挑战”,这简直是降维打击。如果不是白纸黑字的技术报告摆在那里,很难相信一个10B模型能在数学视觉推理(MathVision)和GUI交互能力上把千亿模型逼到墙角。
核心黑科技:它学会了“深思熟虑”
这模型是吃了什么仙丹?答案是一个叫做 PaCoRe(并行协调推理) 的机制。
传统的模型推理大多是“直肠子”,给你一个问题,它基于当前的上下文顺着往下编,一条道走到黑。这种线性思维在处理复杂逻辑时很容易翻车,受限于上下文窗口,深度也有限。
Step3-VL-10B则不同。PaCoRe机制让它拥有了类似人类“系统2”的思考能力。当面对一个难题时,它不再急着给答案,而是瞬间在后台并行生成十几条甚至更多的推理轨迹。这就好比一个团队在头脑风暴,大家分头去试错、去验证,最后把所有线索汇总,合成一个最靠谱的结论。
通过这种“并行探索-协调合成”的方式,它在不增加上下文窗口的前提下,把有效推理计算量扩展到了百万Token级别。说白了,它用“更聪明的思考方式”弥补了“脑容量(参数)”的不足。
炼丹炉里的秘密
除了推理架构的革新,底层的功夫也没少下。阶跃星辰这次走的是“全参数端到端联合预训练”的路子。
很多多模态模型为了省事,视觉编码器是冻结的,相当于给大模型戴了副近视眼镜。而Step3-VL-10B是把视觉和语言部分全部解冻,放在1.2万亿高质量Token里一起炼。再加上超过1400轮的强化学习(RL Scaling),这让视觉信号和语言逻辑在底层就实现了真正的打通。
这意味着什么?
Step3-VL-10B的开源,对行业的影响可能比发一个超级大模型还要深远。
首先是端侧AI的春天。以前想要这种级别的多模态理解能力,你必须联网调API,因为手机跑不动千亿模型。现在,10B的体量完全有机会塞进高性能笔记本甚至未来的旗舰手机里。你的个人电脑可能很快就能读懂复杂的PDF文档、帮你操作GUI界面,而且完全本地化运行。
其次,它打破了成本壁垒。对于研究者和开发者来说,这就是一个现成的、高性能的、可微调的基座。你不需要数百万美元的算力集群,只用几张消费级显卡,就能在这个强力基线上跑出实际应用。
总结
阶跃星辰这次不仅是发布了一个模型,更像是验证了一条新路:与其无休止地堆砌参数,不如回头看看推理架构的效率。
当一个10B模型开始在AIME数学竞赛里碾压对手时,我们知道,AI进化的风向,变了。对于开发者而言,现在最大的建议就是:赶紧去Hugging Face下载权重,在你的显卡上跑起来试试。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


