
在浩瀚的互联网世界中,寻找一款真正适合自己的高性能、高性价比VPS并非易事。信息过载、性能陷阱、选择困难……这些挑战是否让您感到力不从心?别担心,现在有了 传家宝VPS (LegacyVPS.com),这一切都将变得简单而高效!我们致力于成为您值得信赖的VPS伙伴,不仅为您精选全球优质服务器资源,更提供全方位的专业指导,助您轻松驾驭数字世界。 https://www.legacyvps.com 传家宝VPS:为什么是您的最佳选择? 我们深知,您对VPS的需求远不止于简单的购买。您需要的是一份安心、一份保障、一份能真…

就在2026年1月27日,当你还在为了年底的KPI焦头烂额时,月之暗面(Moonshot AI)悄无声息地扔下了一枚重磅炸弹。他们正式开源了新一代通用大模型——Kimi K2.5。 作为一个在这个圈子里摸爬滚打几年的观察者,说实话,我已经很久没有因为一个模型的发布感到兴奋了。但这一次不同,Kimi K2.5不仅仅是参数量的堆叠或者跑分榜上的数字游戏,它展现了一种全新的AI生存形态:从“单兵作战”进化到了“军团协同”。 这就是传说中的“影分身之术”? 这次更新最让我头皮发麻的,是它的核心创新——Agent集群(Age…

说实话,过去几年的AI修图体验,常常让人哭笑不得。 你扔给AI一张照片,说“把背景里的路人去掉”,结果它可能把主角的脸也换了一张,或者背景直接变成了一团难以名状的模糊色块。这就是传统AI的通病:听不懂人话,更不懂画面逻辑。 但在2026年1月26日,腾讯混元团队甩出了一张王炸——混元图像3.0图生图模型(HunyuanImage 3.0-Instruct)。这次更新,可能真的要让那些复杂的修图软件吃灰了。 它不再是瞎蒙,而是学会了“谋定而后动” 这个模型最吓人的地方,不在于它生成的画质有多好(虽然确实很好),而在于…

在很长一段时间里,AI圈流行着一种近乎迷信的观点:大力出奇迹。参数量越大,模型越强,这似乎成了不可撼动的铁律。然而,2026年开年,阶跃星辰(StepFun)甩出的一张“王炸”,狠狠地给这个观点祛了魅。 他们刚刚开源的 Step3-VL-10B,是一个仅有100亿参数的多模态模型。在动辄千亿甚至万亿参数的巨兽面前,它本该是个不起眼的“小弟”。但实际测评结果却令人瞠目结舌:这个“小钢炮”不仅在多项基准测试中碾压了参数规模是其10倍甚至20倍的对手(如Qwen3-VL-235B、GLM-4.6V),甚至在某些高难度科目…

如果说去年的AI编程工具还在比拼谁的补全速度更快、谁猜你的下一行代码更准,那么今年,腾讯云发布的 CodeBuddy Code 2.0 显然想把这场游戏提升到一个新的维度:它不想再只做你的副驾驶(Copilot),它想做你的工程合伙人。 最近科技圈里流传着一组来自腾讯内部的数据,相当耐人寻味。CodeBuddy团队自己用这套工具,在短短58天内完成了79个版本的迭代。而在这些迭代中,90%的新增代码完全由AI生成。这意味着,原本作为辅助角色的AI,已经开始反客为主,承担起了绝大部分的搬砖工作,让4名人类开发者真正回…
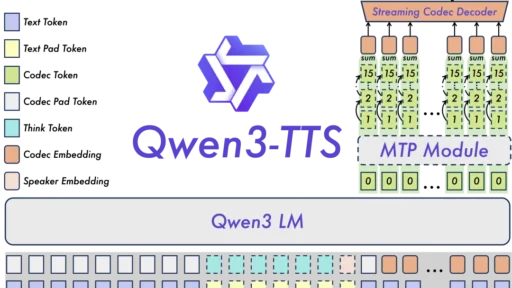
2026年的开年大戏,比我们预想的来得更早了一些。 就在1月22日,当大家还在讨论大语言模型的逻辑推理能力时,阿里通义千问团队悄无声息地在语音生成领域扔下了一枚重磅炸弹:Qwen3-TTS系列模型正式开源。 这不仅仅是“又一个”开源模型,这是一次对“实时交互”的暴力美学展示。作为长期关注AI底层技术的观察者,我拿到技术报告的第一眼,就被那个数字击中了——97毫秒。 今天,我们就来聊聊这个让开发者直呼“真香”,让商业闭源模型感到压力的Qwen3-TTS到底强在哪里。 告别进度条:当生成速度快过你的语速 过去两三年,语…

就在大家都还在回味2025年AI圈的各种混战时,百度在2026年1月22日的“文心Moment”大会上,直接甩出了一张重磅底牌——文心大模型5.0正式版。 作为一个长期在AI一线摸爬滚打的观察者,这次发布会给我的感觉有些不同。如果说以前大家还在拼谁的发布会PPT做得更漂亮,那么文心5.0的发布,更像是一次秀肌肉的“实弹演习”。 咱们抛开那些晦涩的术语,聊聊这次文心5.0到底强在哪,为什么业内有人说这是国产大模型的一次“成人礼”。 不是简单的“大”,而是“大而精” 首先得说说这个吓人的数字:2.4万亿参数。 放在两年…

在很长一段时间里,AI圈流行着一种近乎迷信的认知:大力出奇迹。想要更强的推理能力?加参数。想要看懂更复杂的图表?加参数。仿佛只要把显卡堆满,模型就能产生神迹。 但就在2026年开年,阶跃星辰(StepFun)甩出的这张王炸——Step3-VL-10B,狠狠地给了“参数至上论”一记耳光。 这就好比在一场重量级拳击赛里,一个轻量级选手不仅抗住了重量级拳王的进攻,还反手把对方KO了。这款仅有100亿参数的模型,在多项核心指标上,硬生生按住了参数量是它10倍甚至20倍的对手。 小身板里的怪兽级性能 咱们先不谈虚的,直接看数…

就在2026年1月20日,智谱AI不仅甩出了最新的GLM-4.7-Flash,还顺手把“轻量级模型”的天花板给掀了。 作为一个长期在开源社区摸爬滚打,习惯了在显存焦虑和性能妥协之间反复横跳的博主,看到这个参数配置时,我确实愣了一下。 官方这次打出的牌很清晰:300亿(30B)的总参数量,但推理时只激活30亿(3B)。 这句话背后的含金量,可能比那一长串的跑分数据更值得各位开发者和本地部署爱好者关注。今天我们就抛开那些晦涩的论文词汇,聊聊这个模型到底意味着什么,以及它为什么可能是你本地硬盘里下一个常驻嘉宾。 大脑很大…

坦白说,在很长一段时间里,AI生成3D模型给我的感觉就像是在“开盲盒”。你输入一张图,AI扔给你一个模型,至于背面是不是乱作一团,或者纹理是不是把光影画死在贴图上,全看运气。对于想拿来做游戏资产或者3D打印的人来说,这种不可控性简直是噩梦。 但就在今天,腾讯混元3D Studio 1.2版本全量开放公测。在仔细研究了这次更新的文档并上手体验后,我感觉到风向变了:AI 3D工具正在从“让大家看个乐子”,转向“真正能干活的生产力”。 这次升级不需要什么邀请码,也没了排队申请的门槛,直接进官网就能用。而最让我兴奋的,是它…

大家好,我是平时爱折腾模型的某某。 翻译模型这个赛道,这几年其实挺卷的。但大多数时候,我们的认知还停留在“大力出奇迹”的阶段——想要在WMT24++基准测试中,TranslateGemma 12B的翻译质量竟然直接干翻译得信达雅,模型参数就得往死里堆。显卡在燃烧,电表在倒掉了Gemma 3自家的27B基线模型。 这意味着什么?意味着过去你需要一台昂转,最后出来的结果可能也就比谷歌翻译好那么一点点。 但谷歌最近放出的这个TranslateGemma,贵的服务器才能跑出来的翻译质量,现在在一台配置不错的消费级笔记本(比…

