在开源语音识别领域,OpenAI的Whisper系列曾经是绕不开的大山。但就在2026年1月,阿里云通义千问团队甩出了一张王炸——Qwen3-ASR系列。这不仅仅是一次常规的版本更新,更像是一场针对真实应用场景的精准降维打击。
如果你是一名开发者,或者对语音技术稍有关注,你可能会问:这套模型凭什么挑战现有的秩序?答案藏在它的细节里。
听得懂方言,才算真听懂
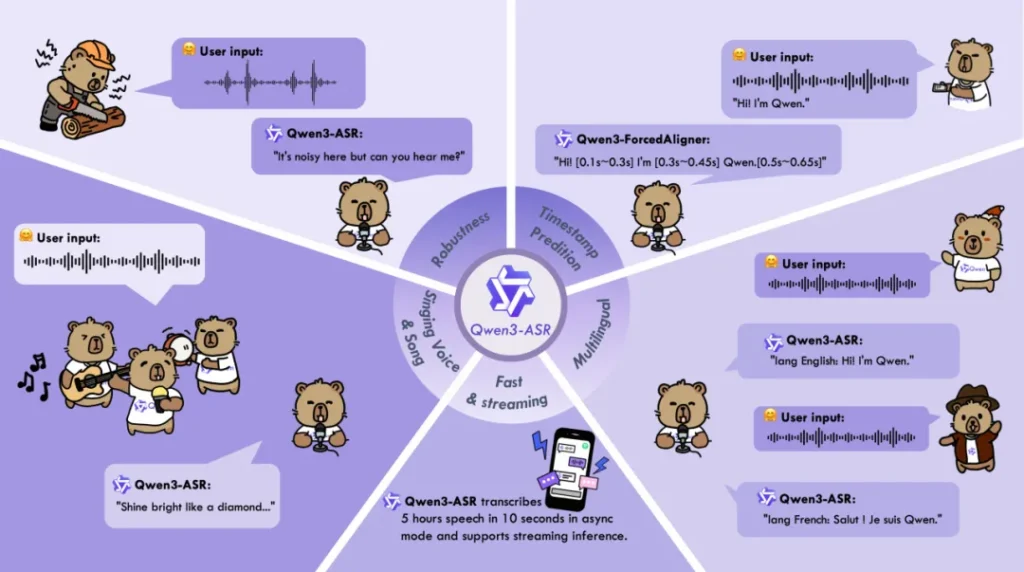
以往的ASR模型,处理标准普通话或广播级英语通常不在话下,但一旦遇到口音浓重的方言,往往就会闹笑话。Qwen3-ASR最让我惊喜的,是它那股接地气的劲儿。
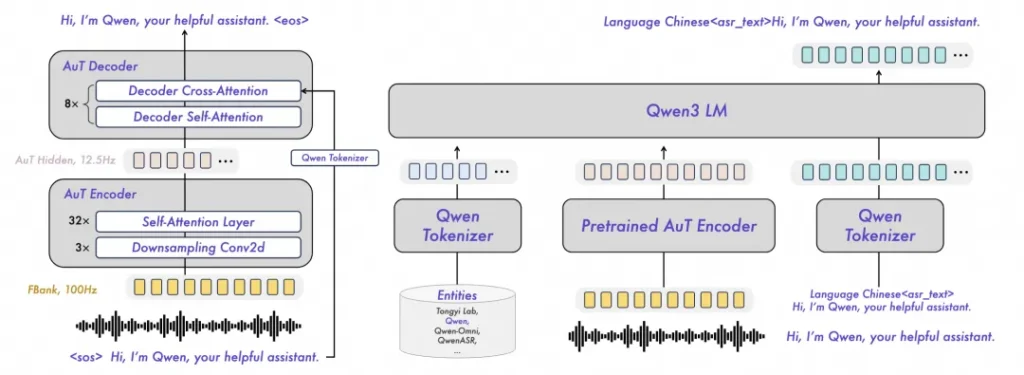
它不仅支持52种语言,更硬核的是它针对22种中文方言进行了深度优化。不管你是讲粤语、闽南话,还是四川话、东北话,甚至带口音的英语(比如印度口音或英式口音),Qwen3-ASR-1.7B都能照单全收。在实测数据中,它的方言识别错误率相比商业API降低了约20%。这意味着,那个需要用户字正腔圆说话的时代,可能要过去了。
在KTV和工地都能干活的AI
真实世界不是录音棚,背景里总是有各种噪音。Qwen3-ASR在鲁棒性上下了狠功夫。
有两个场景特别值得一提。第一是噪杂环境,哪怕是在地铁、工地这种高噪背景下,它依然能稳住识别率。第二是歌声识别,这通常是ASR的噩梦,因为背景音乐会严重干扰人声提取。但Qwen3-ASR却能做到带BGM的整首歌曲转写,中英文歌词的词错误率被压到了15%以下。对于做字幕组或音乐类应用的朋友来说,这绝对是个福音。
快,极其的快
对于工程落地来说,精度是上限,效率是底线。通义团队这次很聪明地把模型分成了两个梯队。
除了追求极致精度的1.7B版本,还有一个0.6B的轻量化版本,它是专门为生产环境准备的。在128并发的异步推理下,这个小家伙能跑出2000倍的吞吐加速。换句话说,处理5个小时的音频,它只需要10秒钟。这种效率对于需要实时处理海量数据的客服质检或直播字幕场景来说,极具诱惑力。
不只是识别,还有精准的时间尺
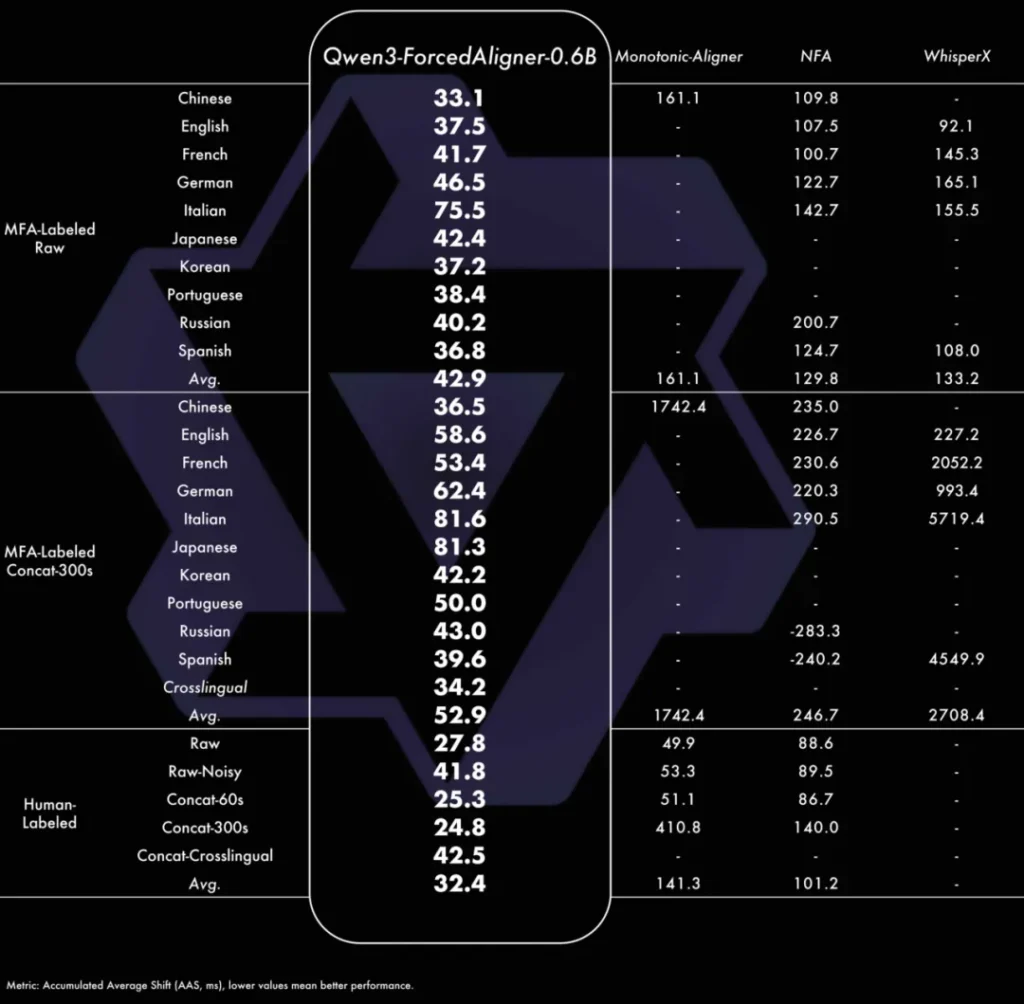
除了识别模型,这次开源包里还附带了一个彩蛋:Qwen3-ForcedAligner。
这是一个专门用于强制对齐的0.6B模型。它的任务不是生成文本,而是把文本和音频的时间轴精准对应起来。它的时间戳预测精度直接超越了WhisperX等传统方案。对于视频创作者来说,这意味着自动生成的字幕不再是大概对齐,而是能精确到字、词级别,后期校对的工作量将大幅减少。
写在最后
Qwen3-ASR系列的出现,补齐了开源社区在多方言和复杂声学场景下的短板。更重要的是,通义团队非常大方地采用了Apache 2.0协议,代码、权重、推理框架全套开源。
无论是想在本地部署一个能听懂家乡话的语音助手,还是想构建一个工业级的高并发转写服务,Qwen3-ASR都提供了一个现成且强大的选项。语音识别的下半场,随着Qwen3的入局,变得越来越有看头了。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站

