各位技术同好,代码农夫,模型“炼丹师”们,请放下手中的 profiler,暂停你的
pip install。今天,我们来聊一个让开源社区心跳加速的新玩意儿——字节跳动Seed团队扔出的重磅炸弹:Seed-OSS-36B。别急着说:“哦,又一个三百亿参数的模型,审美疲劳了。” 如果你只看到参数,那可就错过了这场好戏最精彩的部分。这不仅仅是一次肌肉秀,更像是一场精妙的工程魔法。
一、512K原生上下文:这不是“扩建房”,这是“摩天大楼”地基
我们先来聊聊那个最唬人的数字:512K tokens的原生上下文窗口。
这到底是个什么概念?512K tokens,大约是1600页的文本量。这意味着你可以把一整部《哈利·波特与魔法石》扔给它,然后问它:“多比第一次出现时说了什么?”——它真的能“记得”。
更关键的词是“原生”。
在过去,很多模型为了实现长上下文,用的是类似“位置插值”(Positional Interpolation)这样的“装修”技巧。这就像给一栋小房子强行加盖楼层,虽然看起来高了,但地基不稳,住户(信息)一多,中间楼层的就容易被遗忘,出现“大海捞针”捞不着的情况。
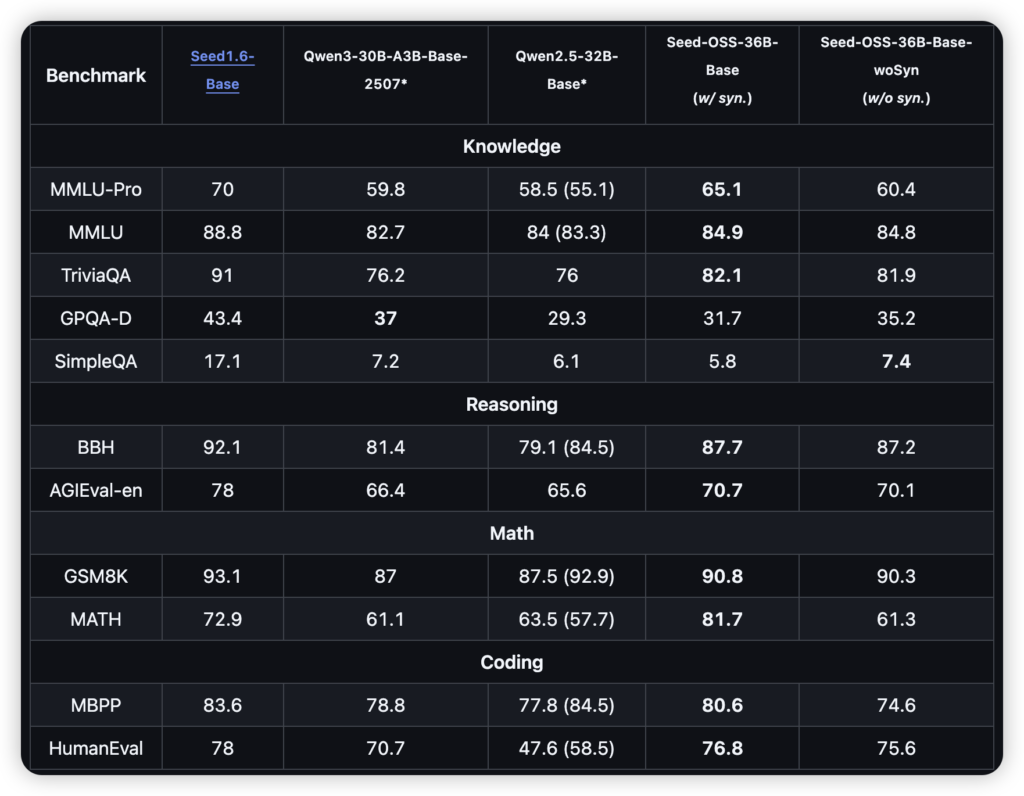
而Seed-OSS-36B不同,它在预训练阶段就是含着“512K”这把金汤匙出生的。它的架构,从旋转位置编码(RoPE)到分组查询注意力(GQA),都是为了支撑起这座“摩天大楼”而设计的。这保证了它在处理横跨数百页的依赖关系时,依然能保持清醒的头脑。
不信?看看RULER(128K)这个长文理解力测试,94.6分的成绩,基本就是告诉其他模型:“在座的各位,在‘长跑’这个项目上,我不是针对谁。”对于需要分析整个代码库、啃完一份几百页法律合同或者财报的开发者来说,这简直是天降神器。
二、创新的“思考预算”:给你的AI装上一个“法力条”
如果说512K上下文是它深不见底的“内存”,那么“思考预算”(Thinking Budget)机制就是它那块可自定义的“CPU”。这是我个人认为Seed-OSS-36B最酷、最“极客范”的设计。
我们平时跟大模型交互,最头疼的就是它要么“想太多”导致响应慢,要么“想太少”导致答案肤浅。我们无法控制它的推理过程,只能听天由命。
字节的工程师们给了我们一个开关。
你可以像游戏里分配技能点一样,给模型设定一个token数量的“思考预算”。比如,你问一个简单事实:“地球的周长是多少?” 你可以给它一个很低的预算,比如thinking_budget=512,它会快速给你答案。
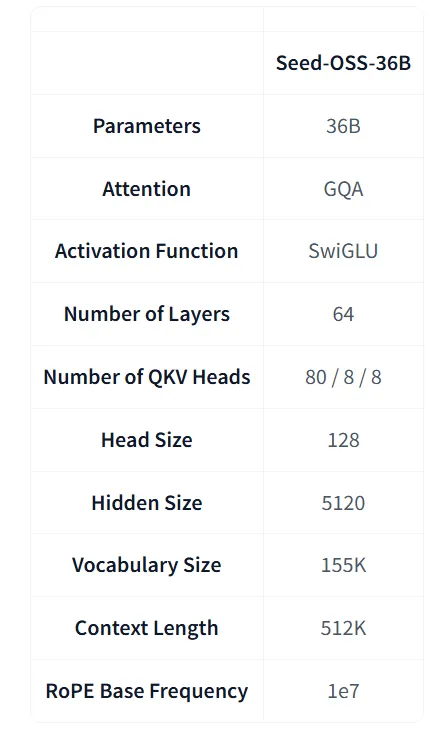
但如果你要它证明一个复杂的数学定理,或者规划一个多步骤的智能体任务,你可以大方地给它一个thinking_budget=2048甚至更高。模型会在推理过程中告诉你它的“法力”消耗情况,让你能一窥它的“思考”轨迹。
这简直是把黑箱撕开了一道口子!它把推理的深度和成本选择权,交还到了我们开发者手里。这对于构建那些既要效率又要深度的Agent应用,意义非凡。你可以动态调整预算,让智能体在简单任务上“敏捷冲刺”,在复杂任务上“深度思考”。
三、藏在数字下的工程美学:36B参数与12T数据的“神仙配比”
现在,让我们聊回参数。360亿稠密参数,在一个动辄混合专家(MoE)架构的时代,坚持做“大力出奇迹”的稠密模型,本身就是一种自信。
但真正让我脱帽致敬的,是它的训练效率。
它只用了12万亿(12T)tokens的训练数据。在同等规模的模型俱乐部里,很多成员的“食量”都在15T以上。用更少的数据,在多个核心基准测试上取得SOTA或接近SOTA的成绩,这意味着什么?
这意味着更高质量的数据清洗、更优化的训练策略,以及更精妙的模型架构设计。从SwiGLU激活函数到RMSNorm归一化,这些看似“标配”的技术选型,在Seed-OSS-36B身上组合出了超乎寻常的化学反应。
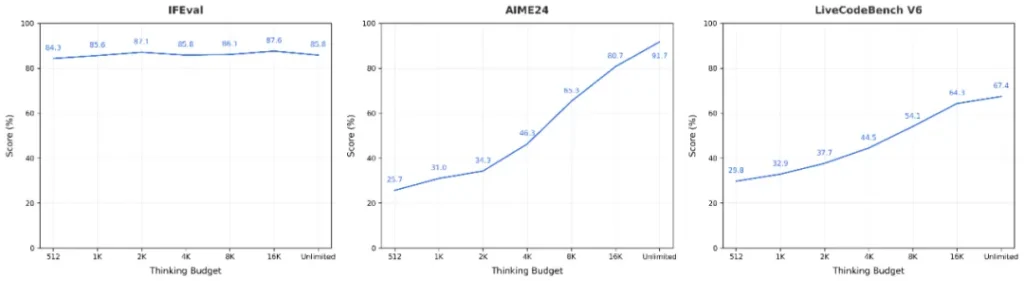
看看它在AIME24数学推理上高达91.7的得分,以及在LiveCodeBench上67.4的亮眼表现,就知道这360亿参数的每一分“体重”,都长在了刀刃上。它不是一个臃肿的胖子,而是一个精悍的拳击手。
开发者,该你上场了
字节这次做得非常地道,不仅开源了模型,还提供了含与不含合成数据的两个Base版本,方便学术界进行更纯粹的研究。Apache-2.0许可证意味着你可以毫无顾虑地用于商业项目。
Hugging Face上已经有了完整的模型和代码,4-bit和8-bit量化版本也已备好,大大降低了我们“把玩”的门槛(当然,20GB+的显存还是需要的)。
总而言之,Seed-OSS-36B给我的感觉,就像一部被精心调校过的性能车。它不仅有强大的马力(性能参数),更重要的是它给了驾驶者(开发者)前所未有的操控感(思考预算)和持久的耐力(超长上下文)。
好了,不说了,我要去git clone了。这个周末,有的玩了。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


