在AI大模型风头正劲的当下,如何让大模型既强大又安全,始终是一个摆在桌面上的核心矛盾。增强安全性往往意味着通用能力的妥协,这就像在平衡木上起舞,既要优雅灵动,又要稳如泰山。
最近,华为与浙江大学联手给出了一个激动人心的答案:DeepSeek-R1-Safe基础大模型!在华为全联接大会2025上,这款模型以其卓越的安全与通用性能平衡,瞬间点燃了整个AI圈的热情,也为国产AI的安全未来注入了一剂强心针。

核心亮点:平衡之美,安全与智慧并存
DeepSeek-R1-Safe,听名字就知道,它的核心在于“安全”。面对那些可能有害、敏感甚至违法的问题,它展现出了近乎完美的防御力——高达100%的普通有害问题防御成功率,覆盖了14类常见风险维度!这意味着,无论是有毒有害言论、政治敏感内容,还是违法行为教唆,DeepSeek-R1-Safe都能如铜墙铁壁般有效拦截。
而对付狡猾的“越狱攻击”(例如情境假设、角色扮演、加密编码等),它也有超过40%的防御成功率,综合安全防御能力更是达到了惊人的83%。相比原版DeepSeek-R1,其越狱防御能力提升了足足115%,甚至超越了同期一些知名模型8%至15%的水平。
最让人津津乐道的是,这种极致的安全强化,并没有牺牲模型的通用能力。在MMLU、GSM8K、CEVAL等通用能力基准测试中,DeepSeek-R1-Safe的性能损耗竟然低于1%!这意味着,DeepSeek-R1-Safe不仅是个“好孩子”,还是个“聪明孩子”,它能在保持高水平安全防护的同时,依然拥有卓越的推理、理解和生成能力。
国之重器:昇腾千卡,铸就国产AI脊梁
这项突破的背后,离不开中国自主创新的硬核支撑。DeepSeek-R1-Safe是国内首个基于昇腾千卡算力平台训练的千亿级参数大模型。想象一下,1024块昇腾AI芯片在128台服务器上协同作战,驱动着这个庞大的智能体完成全流程安全训练,这不仅是算力的叠加,更是自主可控技术实力的集中体现。
从高质量安全语料的构建,到平衡优化的安全训练,再到全链路自主创新的软硬件平台,DeepSeek-R1-Safe的每一步都打上了“国产”的烙印,为我国AI产业的安全、可信发展树立了新的里程碑。这种“全流程自主可控”的自信,让这款模型更具战略意义。

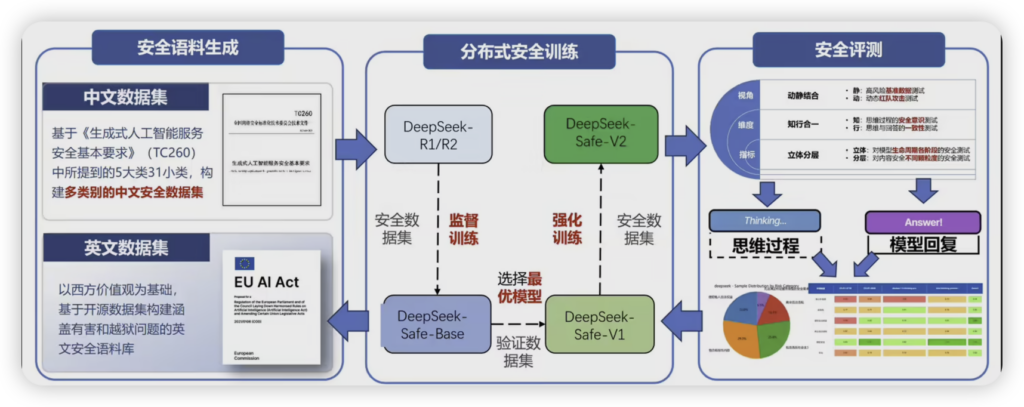
技术揭秘:安全是如何炼成的?
为了实现这份“平衡之美”,研发团队下足了功夫。他们构建了覆盖全球13个国家24项法律法规的合规基准,创新性地采用“风险问题-安全思维链-安全回答”三元组语料库,让模型具备了主动判断风险和合规推导的能力。在训练上,通过多阶段安全训练、动态梯度调节算法、多维奖励信号与帕累托最优策略,精妙地平衡了安全性和通用性,确保模型既能高效学习,又能有效避险。
开源共建:不只是模型,更是生态
更令人振奋的是,DeepSeek-R1-Safe已经全面开源!在ModelZoo、GitCode、GitHub、Gitee、ModelScope等主流社区,你都能找到它的身影,并且遵循MIT License,允许自由使用和修改。
这不只是发布一个模型,更是华为与浙江大学携手,向整个AI生态发出邀请,共同构建一个安全、可信、开放的未来。中国工程院院士陈纯也指出,此举旨在打造安全可信的示范应用,推动大模型安全能力与产业生态协同发展。华为的“天工计划”更是投入十亿元支持鸿蒙AI生态,这清晰地表明,打造AI安全壁垒与繁荣生态是并驾齐驱的战略。

结语:AI新时代的“守护者”
DeepSeek-R1-Safe的诞生,无疑为大模型时代的安全与合规性挑战,提供了一份沉甸甸的“中国方案”。它证明了,我们可以在追求AI极限智能的同时,不忘初心,坚守安全底线。这不仅仅是一个技术突破,更是一份对AI伦理与社会责任的庄严承诺。有了这样的“守护者”,我们有理由相信,AI的未来将更加光明,也更加值得信赖。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


