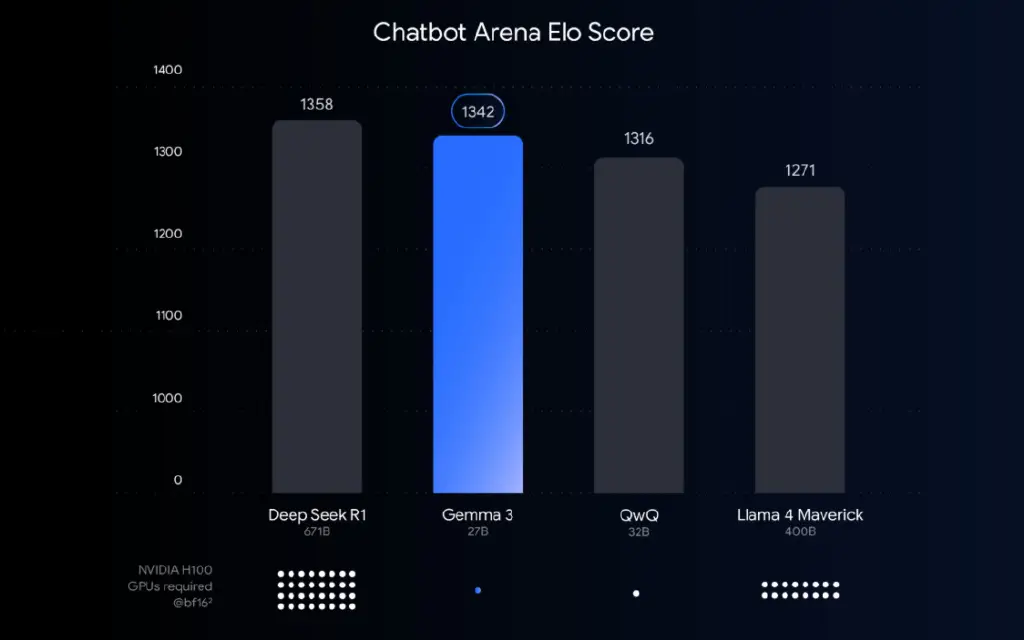
嘿,我是你们在 AI 圈的老朋友,平时总爱折腾点模型啊、硬件啊什么的。最近大模型越来越猛,但随之而来的显存需求简直让人头大,动辄几十上百 GB,咱们普通玩家的消费级显卡根本顶不住,高性能大模型似乎成了云端巨头的专属玩具。
但就在最近,Google 悄悄放出了一个大招,彻底改变了游戏规则!他们发布了 Gemma-3-27B 这个强大模型的 QAT (Quantization-Aware Training,量化感知训练) 版本。这可不是简单的量化,它背后藏着 Google 精心打磨的技术,让这个 270 亿参数的模型变得异常“亲民”。
什么是 QAT,为啥它这么神?
我们都知道,大模型通常用 BF16 (半精度浮点数) 这种格式来存参数,精度高,但也占地方。为了让模型变小,大家尝试了量化,比如把参数从 16bit 压到 8bit 甚至 4bit。但传统的“后训练量化”就像是模型训练好了,你再强行给它瘦身,过程中很容易丢失精度,导致模型变“傻”。
Google 玩的这个 QAT,厉害之处在于它在训练阶段就加入了量化模拟。想象一下,模型在训练的时候就知道自己将来要穿着 4bit 的“紧身衣”干活,所以它会学习如何在低精度下保持高性能。这种方式能最大程度地减少量化带来的精度损失。
Google 官方的数据显示,QAT 相比传统的后训练量化,能将量化后的困惑度下降减少 54%!这意味着模型在低精度下的“理解能力”保留得更好。
显存需求?直接砍到骨折!
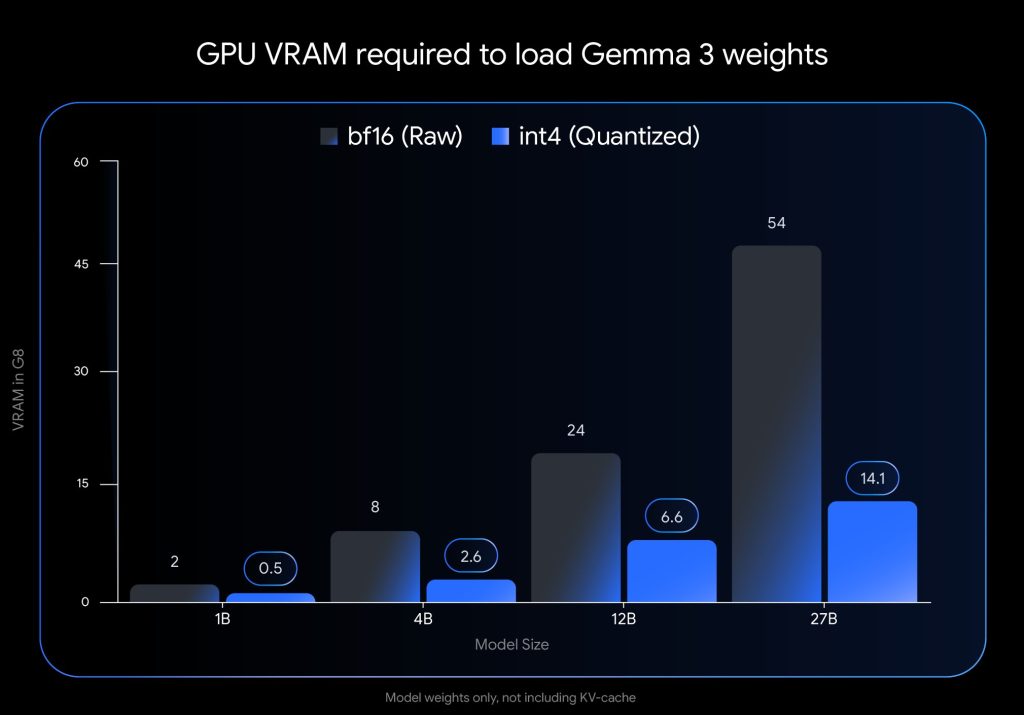
这才是 QAT 版本 Gemma-3-27B 最让人兴奋的地方!原始的 Gemma-3-27B(BF16 格式)需要惊人的 54GB 显存!这基本上只有 A100、H100 这种企业级卡才能跑得动。
但是!通过 QAT 和 4bit 量化(主要是 int4 格式,社区也提供了 Q4_0 等 GGUF 格式),它的显存需求直接降到了大约 14.1GB!
算一下?14.1GB / 54GB ≈ 0.26。没错,这意味着你现在用不到原始模型三分之一的显存,就能加载并运行一个质量和原始 BF16 版本非常接近的 27B 顶尖大模型!
这个内存优化也适用于 Gemma 的其他版本:
- 12B:从 24GB 降到 6.6GB
- 4B:从 8GB 降到 2.6GB
- 1B:从 2GB 降到 0.5GB
当然,实际运行还需要额外的显存给 KV Cache,但这个基础权重的显存需求爆炸性降低,意义太重大了!
本地部署的春天来了!
好了,重点来了!这意味着什么?这意味着高性能大模型不再是遥不可及的云端 API 或者只有实验室才能跑的大家伙了。
- 桌面玩家狂喜: 看看你手里的显卡!如果你有一张 NVIDIA RTX 3090 (24GB显存),或者 RTX 4090/4080,恭喜你,你可以非常流畅地在本地运行 Gemma-3-27B QAT 版本了!
- 笔记本用户也能玩: 即使是 RTX 4060 (8GB 显存) 这样的主流笔记本显卡,跑个 12B 版本也完全没问题。
- 边缘设备?手机? 1B 和 4B 版本更是可以在手机或者智能终端这样的边缘设备上跑起来,想象空间巨大!
怎么快速上手?工具链超全!
Google 和开源社区的联动非常给力,想体验这个模型?方式多得很:
- 懒人必备 Ollama: 如果你是命令行爱好者,或者想最快尝鲜,装个 Ollama,然后一条命令
ollama run gemma3:27b就能搞定,它会自动帮你下载和配置好 QAT 量化版本。 - 图形界面党 LM Studio: 不喜欢命令行的朋友,LM Studio 提供了友好的图形界面,搜索 Gemma-3-27B,一键下载、一键运行,超级简单。
- 苹果用户看这里 MLX: Apple Silicon (M1/M2/M3) 的用户,MLX 框架提供了高效的推理支持,充分利用苹果芯片的性能。
- CPU 也能跑: 还有强大的 llama.cpp 和 Gemma.cpp,即使你没有高性能 GPU,也可以用 CPU 来跑(虽然速度会慢一些),但兼容性极好。
模型文件在哪里找?官方提供了标准的 int4 和 Q4_0 格式,可以在 Hugging Face 或 Kaggle 上直接找到下载。社区里像 Gemmaverse 这样的地方还会有更多自定义的量化选项。
不止是文字,它还有更多可能!
Gemma-3-27B 不仅仅是个文本模型,Google 还展示了它结合多模态能力的潜力。比如,通过集成 SigLIP 这样的视觉编码器,它可以处理图像输入,甚至用于医疗影像分析、工业质检等场景。这意味着我们未来可以在本地运行具备多模态能力的强大模型!
社区反响和未来展望
这个 QAT 版本一出来,社区里简直炸锅了!不少开发者在 X (原 Twitter) 上分享自己的 RTX 4070/3090 跑 12B/27B 模型的截图,直呼“Google 这波操作太给力了,彻底给开发者减负!” 也有人开始畅想更极致的 1bit 量化。
这无疑也给国内的 AI 厂商带来了压力,轻量化和本地化是未来大模型普及的关键,大家都在加速追赶。Google 开放的策略,让更多中小开发者和研究者能够基于顶尖模型进行创新,也许会催生出全新的 AI 应用生态。
未来,我们可以期待 Gemma 系列模型在硬件适配上做得更好(比如适配更多国产芯片),以及在多模态方面带来更多惊喜(比如理解视频、跨模态生成等)。
总结:本地 AI 的新黎明
总而言之,Google 这次发布的 Gemma-3-27B QAT 版本,用量化感知训练这个技术,成功将一个旗舰级大模型的显存门槛从高高在上的 54GB 猛地拉到了消费级显卡完全够得着的 14.1GB。这意味着你不再需要昂贵的云服务器,就可以在你自己的电脑上体验到目前最先进、最强大的开源模型之一。
如果你手里有张 RTX 3090 或更强的显卡,现在就是时候去 Hugging Face 或 Kaggle 把 Gemma-3-27B QAT 版本抱回家,然后用 Ollama 或 LM Studio 跑起来了!本地 AI 的春天,真的来了!
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论