嘿,各位AI圈的老铁们,最近是不是又被各种模型刷屏了?不得不说,现在这大模型迭代速度,简直比翻书还快!今天,咱们就来聊聊一个重磅选手——腾讯混元家的新成员:T1 和 Turbo S 模型。别小看它们,这次腾讯可是掏出了“秘密武器”——混合Mamba架构,直指传统Transformer的痛点,这波操作,有点意思!
告别傻等,拥抱“快慢脑”:混合Mamba是个啥?
咱们先来解密这个听起来很酷的“混合Mamba架构”(Hybrid-Mamba-Transformer)。简单来说,以前的AI模型(主要是Transformer)处理信息,有点像只有一个超强大但有时会“思考人生”的大脑,处理啥任务都得全功率运转,遇到长篇大论或者简单问题时,要么慢要么耗能高。
腾讯这次聪明了,给混元装上了“快慢双脑”:
- 快脑 (Mamba通道):专门处理像查天气、简单搜索这类“小事快办”的任务。利用Mamba架构的线性复杂度(可以理解为更省力),唰唰唰地就能给出回应。据说首字时延直接砍掉44%,低至200毫秒,那感觉,就像有个反应超快的助手。
- 慢脑 (Transformer通道):保留了Transformer这位“老将”的深度思考能力,专门啃硬骨头,比如写代码、搞复杂的逻辑推理。通过一个“动态路由”机制,模型自己判断任务难度,把复杂的活儿交给慢脑精雕细琢。
这种“快慢结合”的设计,直接绕开了传统Transformer算力消耗大、处理长文本吃力的老问题。工业界首次把Mamba这么大规模、无损地用到超大模型上,腾讯这步棋,走得挺大胆,也挺妙!
长文不再愁,效率狂飙3倍!
以前让大模型读个万字长文,经常读着读着就“忘了前面说的啥”,也就是所谓的“上下文丢失”。这次混元T1和Turbo S凭借混合Mamba架构,在这方面简直是“开挂”:
- 超长记忆力:一口气能处理128K tokens的上下文,相当于轻松拿捏十万字的小说或报告,精准定位信息,长距离依赖问题大大缓解。
- 解码速度飙升:长序列处理效率直接提升3倍!这意味着,无论是分析法律文件,还是生成长篇报告,等待时间都大大缩短。
想象一下,让AI帮你分析一份冗长的合同,几秒钟就能抓住关键条款,这效率,爱了爱了!
又快又省!推理能耗、成本双双下降
性能上去了,花费会不会也跟着涨?腾讯这次给出的答案是:NO!
- 更省显存:Turbo S模型通过技术优化(比如FlashAttention-3、动态量化),显存占用降低了30%。门槛低了,更多人能玩得起了。
- 更低成本:推理成本大幅优化,Turbo S的API定价,输入0.8元/百万tokens,输出2元/百万tokens,比上一代便宜了好几倍!T1稍微贵点,但依然很有竞争力(输入1元,输出4元)。这对于需要大规模部署的企业来说,绝对是实打实的利好。
这波操作,不仅让开发者开心,也让AI技术的普及又往前迈了一大步。
“秒回”体验,实时交互玩家的福音
对于智能客服、在线助手这类需要“秒回”的应用场景,Turbo S简直是量身定做:
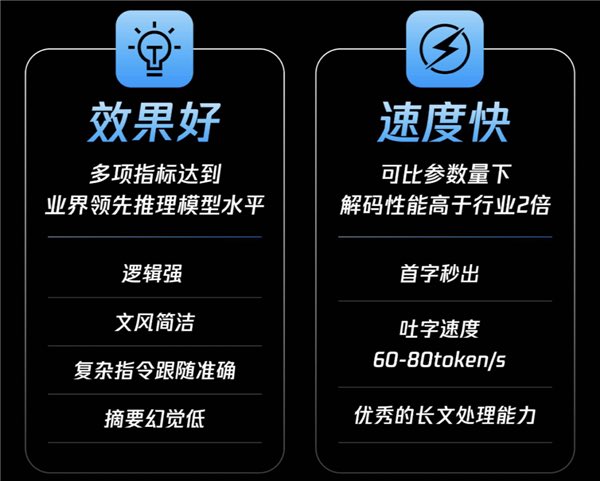
- 响应神速:首字时延降低44%,吐字速度最高能到80 tokens/s,几乎是话音刚落,答案就来了,体验直接拉满。
- 应用广泛:无论是智能客服的快速问答、内容创作的灵感激发、代码生成的实时建议,还是数据分析、智能搜索,都能提供既快又准的反馈。
不止快,更要强:T1的深度思考力
如果说Turbo S是“快枪手”,那T1就是在此基础上的“重炮手”。它继承了Turbo S的速度优势,并通过大规模强化学习和针对数理逻辑、代码等领域的专项训练,把“深度思考”能力拉满了。
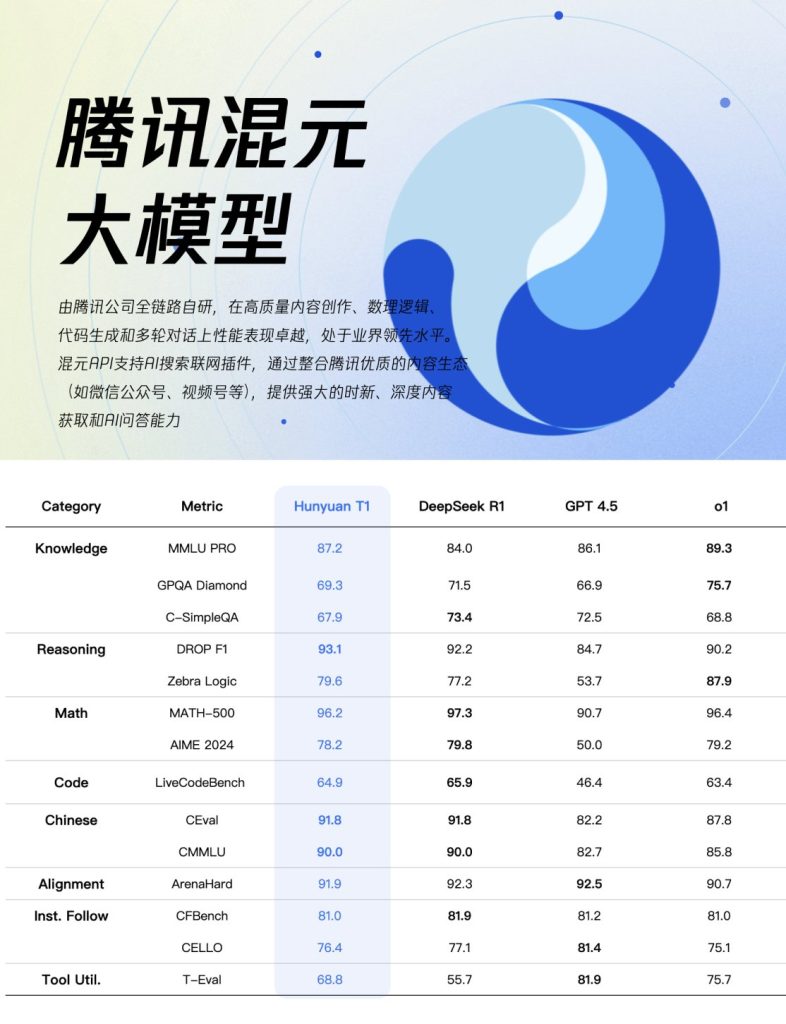
在MMLU-PRO这种考验综合能力的硬核测试上,T1得分87.2,直追业界顶尖水平。这意味着在需要复杂推理、解决难题的场景下,T1更能打。
小结:腾讯混元这波“Mamba舞”,跳得怎么样?
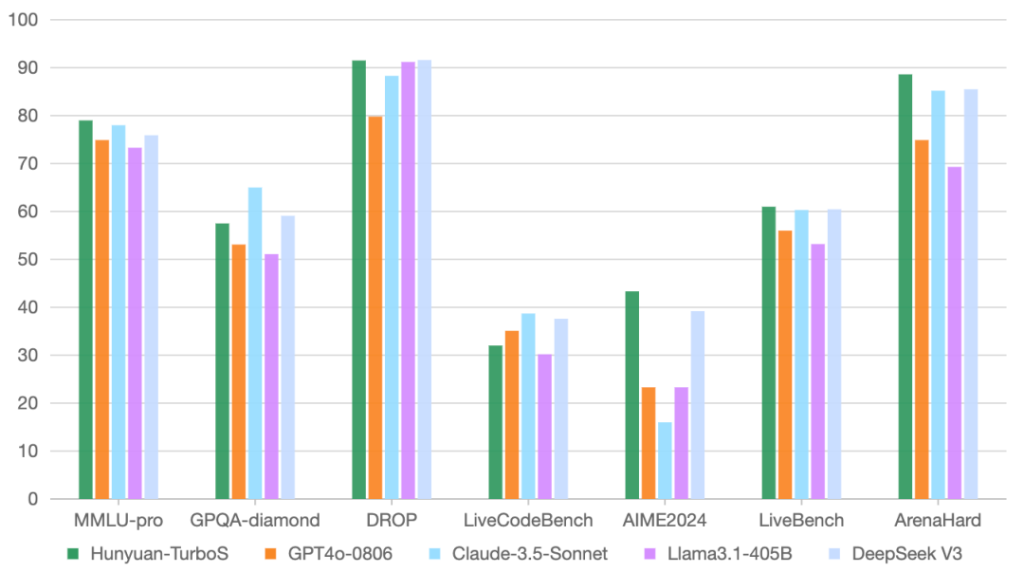
总的来说,腾讯混元T1和Turbo S凭借创新的混合Mamba架构,确实在AI大模型的“效率”和“深度”之间找到了一个非常巧妙的平衡点。
- 解决了痛点:有效缓解了Transformer的算力瓶颈和长序列处理难题。
- 提升了体验:带来了更快的响应速度和更低的使用成本。
- 拓展了边界:让AI在实时交互、长文本处理等领域的应用更加得心应手。
当然,AI江湖风起云涌,各路豪强都在不断亮剑。腾讯混元这次的“快慢剑法”能不能在激烈的竞争中杀出重围,持续领先,我们拭目以待。但毫无疑问,这种架构上的探索和优化,为整个行业提供了一个非常有价值的新思路。
那么问题来了,你觉得这种“快慢脑”设计,会成为未来大模型的主流吗?评论区聊聊你的看法!
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论