六年磨一剑,OpenAI携两大开源模型GPT-OSS强势回归!这次不仅是性能的飞跃,更是对整个AI生态的重塑——免费商用、笔记本也能跑,顶级推理能力触手可及。
一、历史性转折:OpenAI重返开源江湖
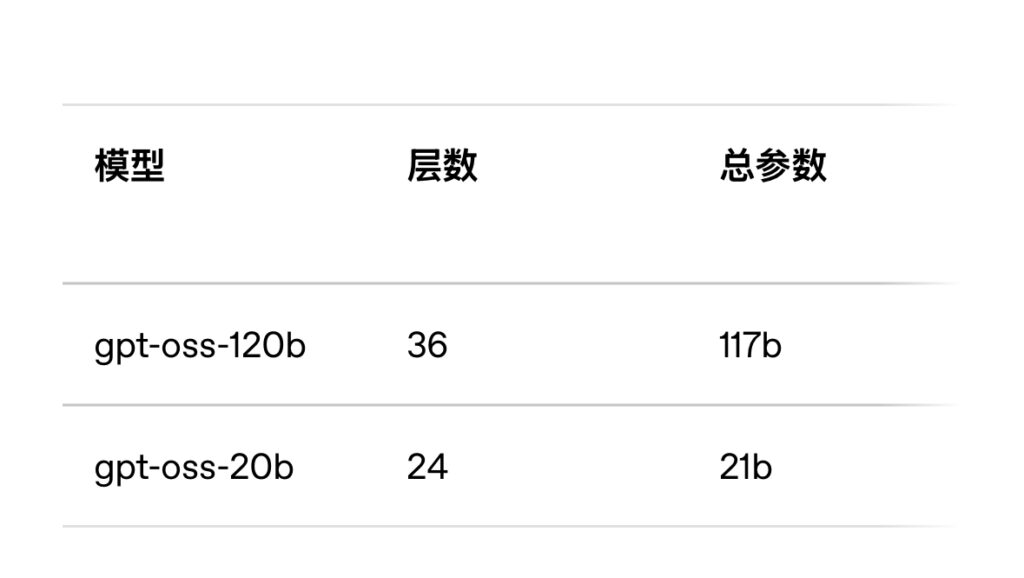
2025年8月6日,AI界投下重磅炸弹!OpenAI终于憋了个大招,一口气推出了名为GPT-OSS(Open Source Series)的开源模型系列,里面有1170亿参数的gpt-oss-120b和210亿参数的gpt-oss-20b。这是自2019年发布GPT-2以来,OpenAI已经六年没有放出过如此规模的权重模型了。CEO山姆·奥尔特曼更是直接放话,称它们是“全球最佳开放模型”。这标志着OpenAI的战略发生了翻天覆地的变化,从过去的“闭门造车”转向了拥抱开源。而且,这些模型都自带“免费商用”的许可(Apache 2.0),这意味着无论是初创公司还是个人开发者,都能毫无顾忌地使用和改造,极大地降低了AI应用的门槛。

OpenAI的CEO山姆·奥尔特曼还特别强调,GPT-OSS系列拥有能与自家的商用模型o4-mini媲美的强大性能,而且最关键的是,你可以直接在本地部署、离线运行,再也不用担心网络连接问题了。
| 特性 | gpt-oss-120b | gpt-oss-20b |
|---|---|---|
| 总参数 | 1170亿 | 210亿 |
| 激活参数 | 51亿/Token(MoE架构) | 36亿/Token(MoE架构) |
| 硬件需求 | 单张80GB显存GPU(如NVIDIA H100) | 16GB内存设备(消费级笔记本即可轻松运行) |
| 性能对标 | 接近OpenAI自家商用模型o4-mini | 媲美o3-mini,甚至超越DeepSeek R1 |
| 部署场景 | 企业级服务器、高性能工作站 | MacBook、Windows PC、边缘计算设备 |
二、技术硬核:重新定义开源模型的“天花板”
GPT-OSS系列之所以能这么牛,离不开其背后先进的技术设计:
-
混合专家架构(MoE)是核心:这两款模型都用了MoE架构的Transformer。简单来说,它就像一个专家团队,处理不同信息时只调用最擅长的那几位专家(参数),而不是一股脑儿把所有参数都动用起来。这不仅大大提升了效率,也让模型的“智慧”更加集中。具体来说,120B模型拥有128个专家子网络,每次处理信息时,只有大约25%的参数会参与计算;而20B模型在处理简单任务时,能激活30%的注意力头,这使得它的推理速度比同等参数规模的模型快了足足40%!
-
原生量化,为部署而生:OpenAI这次玩了个大的,直接在训练阶段就用了MXFP4(一个接近4.25位的低精度格式)。这可不是训练完再压缩,而是“从一开始就这么精简”,所以性能损失非常小。举个例子,20B模型经过量化后,体积仅有12.8GB,在RTX 4090这样的显卡上,响应延迟竟然可以控制在200毫秒以内,几乎就是“秒回”。120B模型在MacBook M3 Max这样的设备上,也能达到每秒30个token的生成速度,完全足够应对离线文档处理等场景。
-
128K超长上下文,沟通无碍:通过一种叫做YaRN的扩展技术,GPT-OSS系列支持高达128,000个token的上下文长度。这意味着什么?模型能“记住”更多的信息,进行更长、更复杂的对话和分析。它还集成了三大核心能力:
- 工具调用:可以流畅地执行Python代码、上网搜索信息、甚至定义和使用函数。
- 三档推理强度:你可以根据需求选择“低、中、高”三种不同的思考深度,让模型在追求速度还是深度之间取得平衡。
- Harmony对话格式:这是OpenAI独创的,能清晰地区分用户的指令、模型的思考过程以及工具的输出结果,让整个交互过程条理分明。
三、性能实测:开源模型的“越级挑战”
别看它们是开源的,性能可一点不含糊,很多方面甚至能“越级挑战”那些闭源的旗舰模型:
- 数学鬼才:在AIME数学竞赛题的测试中,120B模型通过调用工具,准确率达到了惊人的96.6%,非常接近OpenAI自家o4-mini的98.7%。
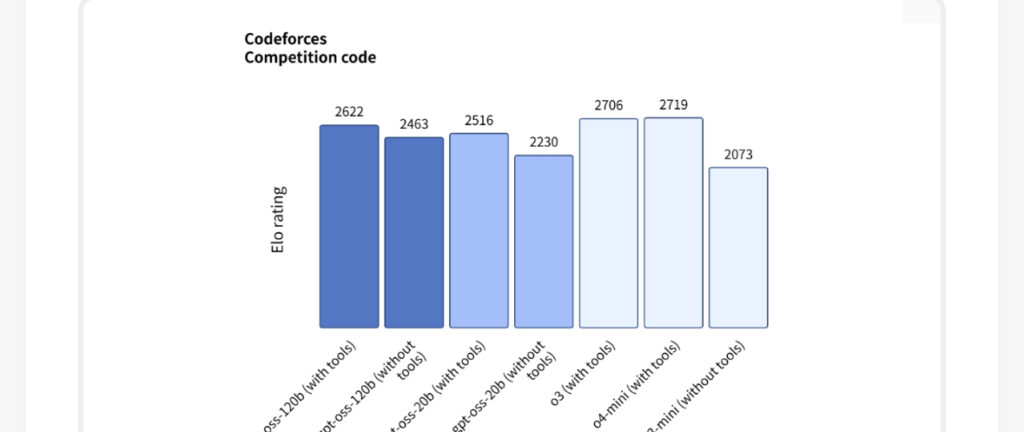
- 编程小能手:在Codeforces编程竞赛中,120B模型拿到了2622分,直接超越了o3-mini。
- 医疗诊断新星:在HealthBench医疗诊断测试中,120B模型对于罕见病的诊断准确率高达89.2%,表现与商用o3模型不相上下。
- 效率惊人:社区的实际测试显示,20B模型在RTX 5090显卡上,速度达到了180 token/秒,这意味着它能在短短三秒内完成一个复杂的推理任务!
四、硬件友好:从数据中心到你的笔记本
GPT-OSS系列最大的亮点之一就是其出色的硬件适应性:
- 消费级设备友好:20B模型最棒的地方在于,只需要16GB内存的MacBook或Windows笔记本就能流畅运行。更别说针对苹果M3芯片优化的INT4量化版本了,简直是笔记本用户的福音。
- 企业级部署无压力:而120B模型,虽然需要80GB显存的专业显卡(如H100),但它可以在单卡上支持高并发,吞吐量更是能达到惊人的500 token/秒,满足企业级应用需求绰绰有余。
- 生态全面支持:
- 亚马逊:已经率先在Bedrock和SageMaker平台上提供了托管服务。
- Windows用户:可以通过ONNX Runtime获得本地推理优化。
- 开发者社区:在Hugging Face、Ollama、LM Studio等平台上,都能一键轻松部署。
五、安全与局限:开源路上的一把双刃剑
OpenAI在模型安全上也下了不少功夫:
- 有害数据过滤:在预训练阶段,就严格过滤了化学、生物、核能(CBRN)等领域的有害数据。
- 安全对抗测试:对抗性微调测试表明,模型尚未触及“高风险能力”的门槛。
不过,作为一款模型,它依然存在一些需要注意的局限性:
- “幻觉”问题依然存在:虽然性能强大,但在PersonQA人物知识测试中,120B模型的幻觉率达到了49%,这比o4-mini(1.4倍)还要高一些。
- 知识更新有滞后:模型的训练数据截止于2024年6月,对于最新发生的事情可能就不那么了解了。
六、生态冲击:AI格局的重构者
GPT-OSS的出现,无疑会在整个开源AI领域掀起一场风暴:
- 商用免费新时代:Apache 2.0许可证意味着,任何企业都可以免费地修改和商业化使用这些模型,这无疑会极大地加速AI技术的普及,尤其是有利于中小团队和初创公司。
- 三足鼎立的格局初现:OpenAI这次携GPT-OSS入局,与Meta的Llama系列以及国内DeepSeek、GLM等模型形成了新的竞争格局。未来的开源AI市场,将更加精彩纷呈。
- 未来可期:可以预见,接下来的AI发展将围绕多模态融合(比如结合Whisper语音识别和CLIP图像理解)、为手机等小型设备优化模型,以及让模型更好地承担Agent(智能代理)的复杂工作流等方面展开。
截至2025年8月,GPT-OSS模型已经在Hugging Face平台上正式开源,大家可以直接通过OpenAI/gpt-oss-20b和OpenAI/gpt-oss-120b这两个路径下载完整的模型权重。据说,OpenAI本周还将发布“重大更新”,业界普遍猜测,这很可能就是万众期待的GPT-5正式登场!这场AI的革新,才刚刚开始!


文章评论