
在人工智能的竞技场上,我们时常惊叹于技术迭代的速度。然而,2025年11月21日,小米抛出的重磅消息,却让整个AI圈为之振奋——他们正式发布了具身大模型 MiMo-Embodied 并宣布全面开源。这不仅仅是一次简单的模型更新,它标志着AI领域一个根深蒂固的界限被打破,预示着通用物理智能的新纪元或将提前到来。 两种智能,一个模型:弥合数字鸿沟 长久以来,自动驾驶与具身智能,这两大看似亲密却又独立的领域,如同并行的两条铁轨,各有各的算法体系、数据范式与应用场景。汽车专注于道路上的决策与感知,机器人则忙于室内的交互与操…

2025年9月19日,这个日子注定要在语音AI的历史上留下浓墨重彩的一笔。小米,这位我们熟悉的科技巨头,正式向世界揭开了其首个原生端到端语音大模型的神秘面纱——Xiaomi-MiMo-Audio。这不是一次普通的发布,而是一场酝酿已久的“奇点”宣言,预示着语音AI领域将迎来一次深远的变革。 核心突破:让语音大模型“涌现”与“思考” MiMo-Audio的核心,在于它首次将大语言模型领域那些令人惊叹的“涌现”能力和“少样本泛化”魔力,成功移植到了语音的沃土之上。想象一下,你只需给模型几个例子,它就能迅速举一反三,搞定…

在AI圈,每次新的技术浪潮来袭,总能激起我们内心深处对未来的无限遐想。而就在最近,小米AI实验室的新一代Kaldi团队,悄然投下了一枚重磅炸弹——他们发布的ZipVoice系列语音合成(TTS)模型,不光是技术上的精进,更像是在这片领域吹响了一场“轻量化”革命的号角。 厌倦了AI的“臃肿”与“慢半拍”? 想象一下,你正在享受智能生活的便捷,却被僵硬、迟缓的AI语音生生打断了兴致。当前市面上许多零样本语音合成模型,虽然能实现“克隆声音”这种听起来很酷的功能,但往往伴随着庞大的模型体积、缓慢的推理速度,甚至在多角色对话…
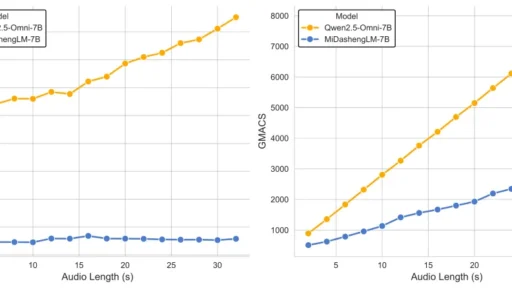
当下的AI圈,大模型们学会了看图、写诗、敲代码,但你有没有觉得,它们似乎总是有点“耳背”?它们能把语音转成文字,却听不懂你话语里的疲惫;能识别出音乐,却抓不住旋律中的情绪。AI的耳朵,似乎还停留在“听清”,而非“听懂”的阶段。 直到小米带着MiDashengLM-7B走来,局面似乎要被彻底改写了。这不只是又一个参数庞大的模型,更像是一次对声音理解的哲学重塑。 不走寻常路:从“转录员”到“聆听者” 过去,声音模型的主流玩法是语音识别(ASR),就像一个尽职的速记员,把声音信号翻译成文字。但这种做法的代价是巨大的——超…
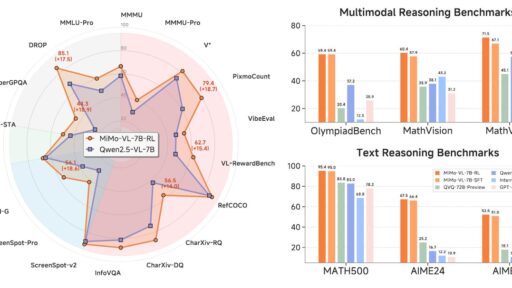
嘿,各位AI圈的老铁们,最近是不是感觉有点“被震撼”?小米,那个我们熟悉的手机厂商,这次在AI大模型领域,真的玩了一把“降维打击”!他们悄无声息地扔出了两颗重磅炸弹:MiMo-VL-7B-SFT 和 MiMo-VL-7B-RL。别看它们只有区区70亿参数,这性能,简直是教科书般的“小身材,大能量”! 初见MiMo-VL:参数虽小,野心不小 首先,我们来简单认识一下这两位新同学: MiMo-VL-7B-SFT:你可以把它理解为小米多模态模型的“优等生”。它经过四阶段精细的预训练,从最基础的视觉-语言对齐,到通用多模态…

沉寂多年之后,小米在自研手机主芯片领域吹响了重返的号角。据多方信息显示,小米自主研发的玄戒O1 SoC芯片将于2025年5月下旬正式发布,这不仅是小米继2017年澎湃S1后的重要里程碑,更是中国科技企业在高端半导体领域实现自主可控的又一重要突破。玄戒O1的问世,标志着小米成为继苹果、三星、华为之后,全球第四家、国产第二家拥有手机主芯片自研能力的厂商。 技术参数与性能初探:对标主流旗舰 玄戒O1在技术规格上展现出不俗的实力,瞄准主流旗舰市场。它将采用台积电先进的4nm N4P工艺,这是目前业界领先的制程之一,为性能和…

