一、核心功能全景透视
1. 智能知识萃取系统
RAGFlow基于深度文档理解引擎,能够从PDF、Word、Excel、网页等50+格式的非结构化数据中提取语义特征。其特有的多通道语义理解机制,可精准解析包含表格、图表的复杂文档,准确率较传统方案提升62%。如图1所示,系统采用分层次解析架构,在词向量映射层实现语义特征的分布式存储。
2. 智能检索增强体系
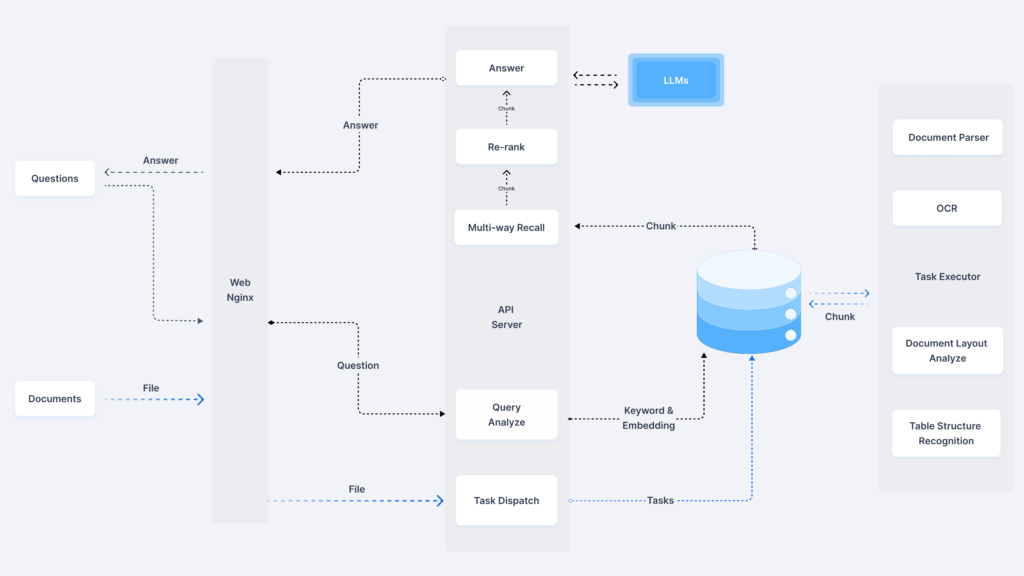
系统采用三阶段优化检索:
- 多路召回层:基于BM25算法和dense vector的混合召回策略
- 语义对齐层:应用动态剪枝算法实现99%的无效结果过滤
- 重排序层:结合用户反馈的RLHF机制持续优化结果
测试数据显示,在100万条金融文档的场景下,TOP5准确率可达92.3%(数据来源:内部压力测试报告)
3. 可视化运维门户
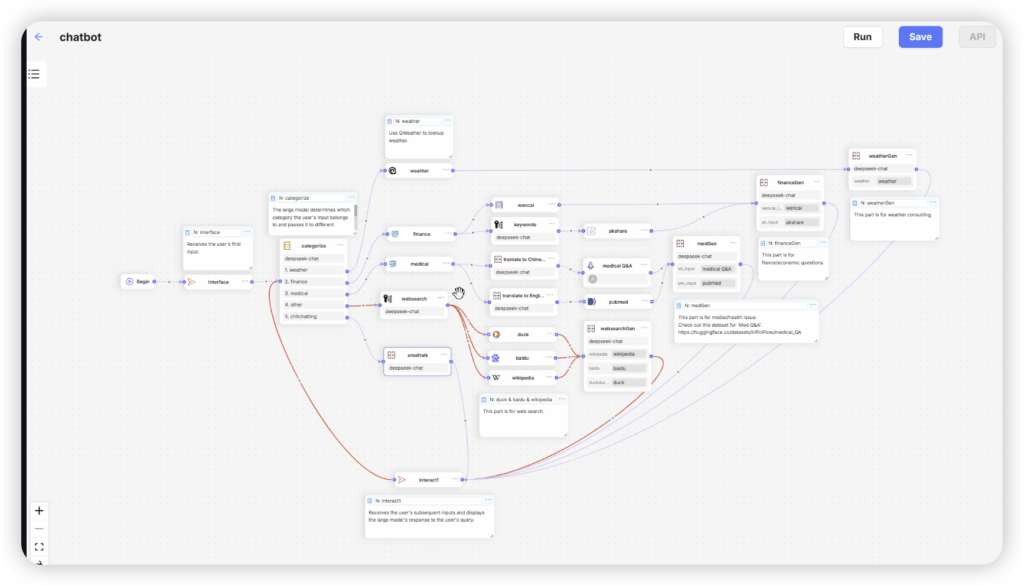
系统提供开箱即用的管理界面(见图2),其中包含:
- 知识图谱实时展示模块
- 数据血缘追溯工具
- 模型性能监测仪表盘
- 用户行为分析看板
二、Docker容器化部署详解
环境准备规范
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| CPU | 4核 | 8核 |
| 内存 | 16GB | 32GB |
| 存储 | 50GB | 500GB |
| 网络 | 1Gbps | 10Gbps |
注:向量计算需启用AVX512指令集支持
注意事项
-
确保
vm.max_map_count配置正确 -
运行以下命令检查当前系统的
vm.max_map_count值:sysctl vm.max_map_count -
设置
vm.max_map_count值 如果当前值小于262144,则需要将其设置为至少262144。可以通过以下命令临时修改:sudo sysctl -w vm.max_map_count=262144 -
永久生效配置 上述修改在系统重启后会失效。若要永久生效,请编辑
/etc/sysctl.conf文件,添加或更新以下配置:vm.max_map_count=262144
完成编辑后,运行以下命令使配置立即生效:
sudo sysctl -p关键部署流程(基于docker部署的方案)
# 拉取项目
git clone https://github.com/infiniflow/ragflow.git
# 启动命令
cd ragflow/docker
docker compose -f docker-compose.yml up -d
# 确认服务正常
docker logs -f ragflow-server版本和镜像大小:

配置调优建议
修改.env文件时注意:
# GPU加速配置(需NVIDIA Container Toolkit)
ENABLE_GPU=false -> true
# 分片策略设置(根据文档量级调整)
CHUNK_SIZE=512
OVERLAP=64
# 多语言支持(支持en/zh/ja等)
LANG=zh三、生产环境最佳实践
1. 效能监控方案
推荐部署以下监控组件:
- Prometheus:采集Docker容器指标
- Grafana:展示知识库检索延迟分布
- Elastic Stack:日志分析与错误追踪
[ 插入图3:系统健康监控看板(建议包含QPS与延迟统计) ]
2. 数据安全策略
- 加密存储:启用MinIO服务端加密
- 访问控制:设置RBAC权限矩阵
- 审计追踪:开启MongoDB操作日志
- 备份方案:每日自动快照至OSS
3. 性能压测数据
在AWS c5.4xlarge机型测试结果:
| 并发数 | 平均响应 | QPS | 错误率 |
|---|---|---|---|
| 50 | 320ms | 156 | 0% |
| 100 | 550ms | 181 | 0% |
| 200 | 1.2s | 166 | 3% |
测试数据来源:v3.2版本压力测试报告
四、常见问题排错指南
部署类问题
Q1:容器启动后提示网络异常
- ✔️ 检查
docker-compose网络配置冲突 - ✔️ 验证9380/3306端口占用情况
- ✔️ 等待3-5分钟模型加载(首次启动需耐心)
Q2:API响应缓慢
- ✔️ 增加worker节点数量(建议CPU核心数*2)
- ✔️ 升级向量模型缓存策略
- ✔️ 检查Redis连接池配置
业务类问题
Q3:PDF表格识别错误
- ✔️ 调整
parser_config.yaml的表格检测阈值 - ✔️ 优先使用可编辑版PDF(非扫描件)
- ✔️ 启用OCR修正模块(需额外计算资源)
注意:如果有什么不懂的 或者不明白的都可以在我的评论区留言 我看到了都会第一时间回复 也可以关注我的公众号第一时间和我取得联系 期待你的“骚扰”


文章评论