在人工智能浩瀚的星河中,Transformer模型以其革命性的全注意力机制,一度被奉为处理序列数据的圭臬。它那无所不包的全局视野,让机器首次真正理解了上下文的深邃关联。然而,这份“全能”的背后,却也藏着一个难以回避的“甜蜜负担”:随着输入序列的无限增长,其二次方的计算复杂度与内存消耗,像一道无形的壁垒,将AI模型的长文本理解能力牢牢锁在了某个阈值内。
直到近日,月之暗面(Moonshot AI)的一声号角,打破了这份沉寂。他们带着全新的Kimi Linear混合线性注意力架构,如同一位身手矫健的新星,踏入了竞技场。Kimi Linear不只是对传统机制的修修补补,它更像是一场深思熟虑的革命,首次在多种实际场景下,正面超越了传统Transformer的全注意力机制。这无疑宣告了一个新时代的到来:长文本处理,正迎来它的“记忆大师”。
核心创新:当“细致入微”遇到“平衡之道”
Kimi Linear的魔力,并非空中楼阁,而是建立在数个精巧的核心创新之上:
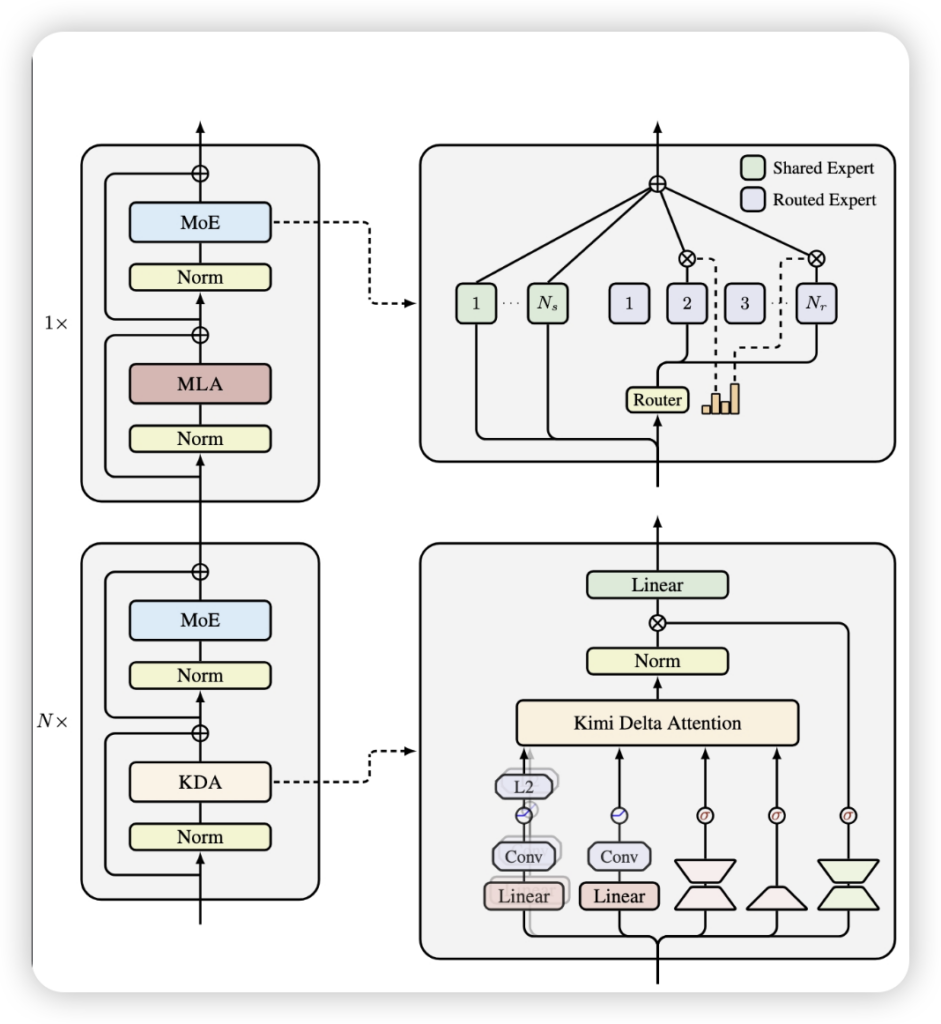
首先,是其灵魂所在——Kimi Delta Attention (KDA)。你可以想象它是一位极其挑剔的图书馆管理员,面对浩如烟海的信息,它不再是简单地选择记住一整本书或完全遗忘,而是能精细到每一个句子、每一个词语,为其设置独立的“遗忘率”。这项源于Gated DeltaNet的改进,引入了通道级对角门控机制,赋予模型对记忆前所未有的细粒度控制力。这意味着,模型能更智慧地取舍,高效地利用有限的计算资源,让每一寸“记忆”都物尽其用。
其次,Kimi Linear深谙“孤木难成林”的道理,它并非一味地追求线性,而是采取了一种3:1的混合架构。这意味着,每运行3层高效的KDA线性注意力层,便会穿插一层传统的全局全注意力层(MLA)。这就像一支高效的探险队:KDA层是冲锋在前的轻骑兵,迅速处理局部信息,大幅提升了效率;而MLA层则是团队中的智者,定期提供全局视角,确保模型不会在局部细节中迷失方向,从而在性能与效率之间找到完美的平衡点。
最后,月之暗面深知,再好的设计也需硬件的支撑。KDA模块通过定制的Diagonal-Plus-LowRank (DPLR) 矩阵和创新的分块并行算法,从底层优化了计算逻辑。再加上内核融合等一系列“硬核”优化,使得它在GPU上的运行效率比以往方案提升了惊人的100%。这不只是换了个更快的引擎,更是对整套动力系统的彻底革新。

性能飞跃:告别“慢时代”,迎接“百万级”速度
理论的突破最终要用数据说话,Kimi Linear的成绩单,无疑是这场革命最有力的注脚:
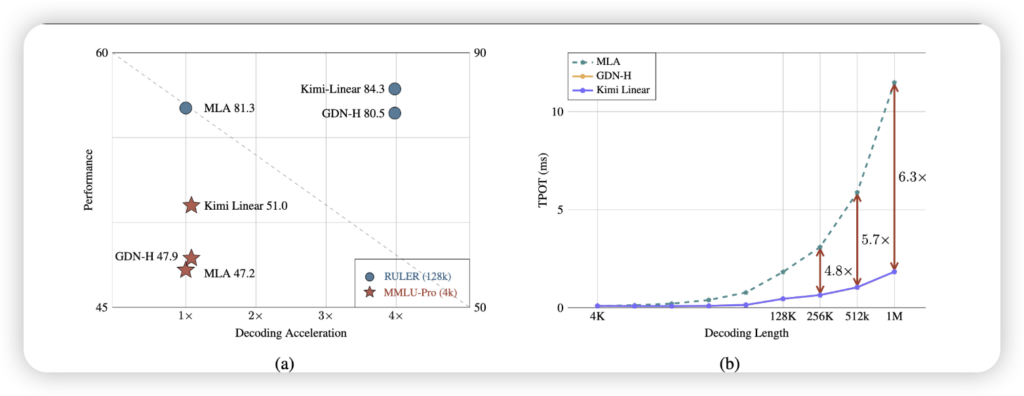
在模型性能上,无论是在评估通用知识的MMLU、考验推理能力的BBH、面向中文任务的CEval/CMMLU,还是数学领域的AIME,Kimi Linear都表现出全面超越同规模传统全注意力模型的实力。这表明,效率的提升并非牺牲了模型的“智慧”,反而让它更加卓越。
而最令人振奋的,莫过于其在长文本处理上的效率表现。当需要处理100万token的超长上下文时,Kimi Linear的解码吞吐量达到了传统全注意力模型的6倍!这意味着,原本需要漫长等待才能处理的浩瀚文本,现在可以瞬间得到响应。即使是512k长度的序列,速度也提升了2.3倍。想象一下,一整本小说的解析,不再需要漫长的加载,而是眨眼之间完成。
同时,它对资源的节约也同样显著:KV缓存占用降低了75%,这直接意味着在处理长文本时,显存的压力大幅缓解,部署成本也随之骤降。对于训练者而言,这更是一大福音——训练阶段每输出一个token的时间(TPOT)相比传统MLA架构加速了约6.3倍,让模型迭代的速度也迈入了一个新纪元。

行业影响:长文本AI的“范式转移”
Kimi Linear的问世,恰逢其时。此前,有友商在尝试线性注意力后,选择回归全注意力,并公开阐述了线性注意力在工程落地上的挑战。而Kimi Linear的成功开源,无疑是对这种路线可行性的一次强有力证明。它不仅展示了AI底层技术路线的多元化探索,更在长文本处理这一核心瓶颈上,为整个行业点亮了一盏明灯。
月之暗面已经慷慨地将这项创新全面开源:你可以在GitHub上找到它的技术报告与代码,在Hugging Face上获取模型权重,甚至它已获得vLLM推理框架的官方支持,大大降低了开发者尝鲜和部署的门槛。
Kimi Linear的出现,不只是一次技术的迭代,它更像是一次宣言:AI的长文本理解不再需要束手束脚,百万级上下文的时代已然来临。这位新晋的“记忆大师”,正以其独特的方式,重新定义AI的潜能,为未来的智能体(Agent LLM)和更复杂的AI应用,奠定了坚实的基础。我们有理由相信,随着Kimi Linear的普及,AI与长文本的交互将变得更加流畅、高效,开启更广阔的应用场景。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


