引言
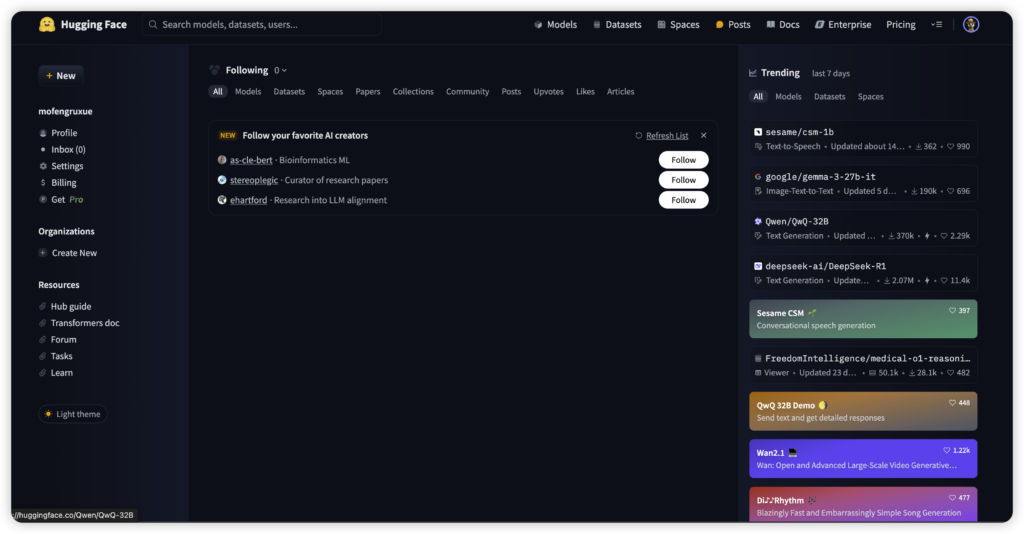
随着人工智能技术的飞速发展,HuggingFace作为全球最大的开源AI社区,每周更新的热门模型榜单已成为开发者与研究者关注的“风向标”。根据最新数据,上周的十大热门模型中,中国开源模型表现亮眼,推理与多模态能力成为技术突破的核心方向。以下为具体分析:

十大热门模型解析
1. Qwen/QwQ-32B:开源推理模型的新标杆
- 参数与类型:32B参数的文本生成模型,专注推理能力。
- 亮点:阿里通义千问系列的最新成员,不仅登顶HuggingFace模型榜,还在国际权威评测LiveBench中超越OpenAI-GPT-4.5 preview和Google-Gemini2.0,成为全球最强开源模型。其核心优势在于部署成本低,支持消费级显卡(如RTX 4090)运行,极大降低了学术界与产业界的落地门槛。

2. deepseek-ai/DeepSeek-R1:开源社区的“超级明星”
- 参数与类型:685B参数的推理模型,覆盖复杂场景需求。
- 亮点:此前曾以超150万次下载量创下HuggingFace平台记录,并长期占据榜首。其代码生成能力尤为突出,评测分数超过顶级闭源模型,且支持宽松的Apache 2.0协议,开发者可自由商用。

3. google/gemma系列:多模态模型的全面爆发
- 参数与类型:覆盖1B至27B的多模态模型(如gemma-3-27b-it)。
- 亮点:谷歌Gemma系列在图像、文本跨模态任务中表现优异,27B版本尤其擅长复杂视觉推理。其开放协议友好,适配多种硬件环境,成为开发者构建多模态应用的首选。

4. RekaAI/reka-flash-3:轻量级推理新秀
- 参数与类型:20.9B参数的文本生成模型。
- 亮点:以高效微调著称,资源需求仅为同类模型的1/5,适合中小团队快速部署。其训练框架支持LoRA等参数高效技术,显著降低计算成本。
5. CohereForAI/c4ai-command-a-03-2025:大参数文本生成黑马
- 参数与类型:111B参数的通用文本生成模型。
- 亮点:由Cohere团队开源,支持多语言任务,指令遵循能力接近闭源模型。其训练数据覆盖多领域,特别适用于金融与法律文本生成。
6. 语音合成双雄:技术普惠的典范
- sesame/csm-1b(1B参数)与SparkAudio/Spark-TTS-0.5B(0.5B参数)凭借轻量化设计,在低资源设备(如手机)上实现高保真语音合成。其中Spark-TTS-0.5B仅需8GB显存即可流畅运行,成为教育、客服等场景的热门选择。
7. google/gemma-3-1b-it与4b-it:小模型的逆袭
- 参数与类型:1B与4B参数的文本生成模型。
- 亮点:虽参数规模小,但在特定任务(如短文本摘要、实时对话)中表现突出。其量化版本适配边缘设备,被广泛应用于物联网与移动端。

趋势洞察
- 中国模型的全球崛起:榜单前十中,Qwen、DeepSeek等中国模型占据半数席位。其成功得益于宽松的开源协议(如Apache 2.0)、全参数覆盖的生态支持,以及算法优化带来的低部署门槛。
- 多模态与推理能力的融合:Gemma系列与QwQ-32B的爆发,标志着AI从单一模态向跨模态推理的演进。开发者更倾向于选择兼具性能与易用性的模型,而非单纯追求参数规模。
- 轻量化与普惠化:小参数模型(如1B-20B)通过量化、蒸馏等技术实现高效部署,推动AI技术向中小企业和个人开发者渗透。
结语
上周的HuggingFace榜单不仅反映了技术趋势,更揭示了开源生态的竞争格局:中国模型通过开放性与创新性引领潮流,而多模态与轻量化正成为下一代AI的核心战场。开发者可通过榜单中的模型快速获取前沿能力,加速应用落地。
如需完整榜单与模型详情,可访问HuggingFace官网或参考来源。
如果你也对最新的AI信息感兴趣或者有疑问 都可以扫描下面的二维码加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉



文章评论