嘿,AI圈的朋友们!最近DeepSeek团队又搞了个大动作,发布了一款名叫DeepSeek-OCR的开源模型。但你可别以为这只是一个普通的文字识别工具,它的核心理念简直是脑洞大开,可能会彻底改变我们处理长文本的方式。
想象一下,我们的大语言模型(LLM)在面对海量文本时,常常会因为算力消耗过大而头疼不已,上下文一长,计算量就呈平方级增长。DeepSeek-OCR另辟蹊径,它不直接处理文本,而是巧妙地把文本信息“画”成图像,然后对这些图像进行压缩!是不是有点像人类先看图再理解,而不是一个字一个字地嚼?
“光学压缩”的视觉魔法
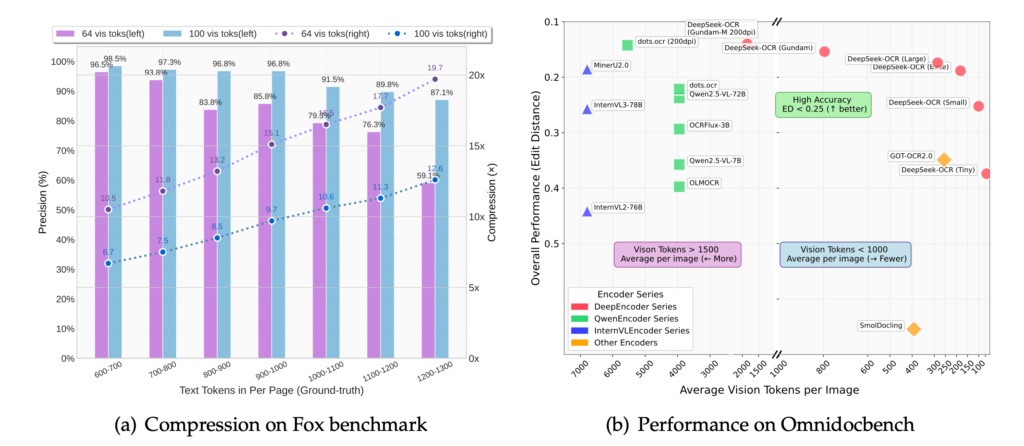
DeepSeek-OCR的核心创新,我愿称之为“上下文光学压缩”。它由一个名为DeepEncoder的视觉编码器和DeepSeek3B-MoE-A570M的混合专家(MoE)解码器组成,总参数量高达30亿。这个DeepEncoder可不简单,它能把高分辨率的图像输入,通过一系列巧妙操作(比如局部特征提取、16倍下采样),把一张1024x1024的图像从4096个视觉Patch Token一口气压缩到区区256个!
这意味着什么?在实际测试中,DeepSeek-OCR展现了惊人的压缩能力:
- 10倍压缩比下,OCR识别精度依然能达到97%,几乎是无损级别的!
- 即使是20倍的极限压缩,精度也能保持在60%左右,这在很多场景下已经足够应付紧急处理了。
这样的效率,简直是为LLM处理长文本量身定制的“上下文救星”。
不止快,更要“聪明”
除了高压缩比,DeepSeek-OCR的生产效率也让人咋舌。据团队透露,仅仅一块A100-40G显卡,一天就能处理超过20万页的训练数据,如果20个节点齐发力,日处理量能达到恐怖的3300万页!这对于需要大规模文档数字化的金融、政府、医疗等行业来说,无疑是一剂强心针。
更妙的是,它不只认识普通文字,在处理图表、化学分子式、几何图形这些复杂元素时也游刃有余。它能把金融报告里的图表转化为结构化数据,把化学公式识别成SMILES格式,甚至支持近百种语言,包括那些对传统OCR来说难度极大的复杂文字。
它还提供了从Tiny到Gundam等多种分辨率模式,可以根据实际需求灵活调整,从移动端到超大复杂文档都能覆盖。

模拟人类记忆:AI的“遗忘曲线”?
DeepSeek团队的野心远不止于此。他们提出了一个前瞻性的设想:将大模型处理的超长上下文,比如多轮对话历史,像人类记忆一样,近期保持清晰,而随着时间推移,旧的信息则被渲染成图像并逐步压缩,自然地“淡化遗忘”。这为管理LLM的超长上下文和构建更类人化的记忆机制,开辟了全新的研究方向。

开源,是最好的礼物
DeepSeek-OCR作为一个完全开源的项目,已经在Hugging Face和GitHub上开放了代码和模型权重,并且提供了详细的部署教程和推理示例。这意味着,只要你有一块合适的NVIDIA GPU,就能亲手体验这款“光学压缩”模型的魔力。
当然,作为AI圈的探索者,我们也明白,新模型发布初期的性能宣称,还需要社区进行广泛的复现和验证。但DeepSeek-OCR无疑提供了一个激动人心的全新视角,它让我们看到了视觉模态在解决语言模型核心难题上的巨大潜力。这不仅仅是一个OCR工具的升级,更可能是通往“无限上下文”LLM时代的重要一步。未来,它会在多模态AI的道路上扮演怎样的角色,让我们拭目以待!
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


