核心领域突破与优先优势
Claude 3.7 Sonnet作为Anthropic最新推出的“混合推理模型”,在以下领域展现了断崖式领先优势,重新定义了AI技术的应用边界:
1. 编程与软件开发:行业标杆级表现
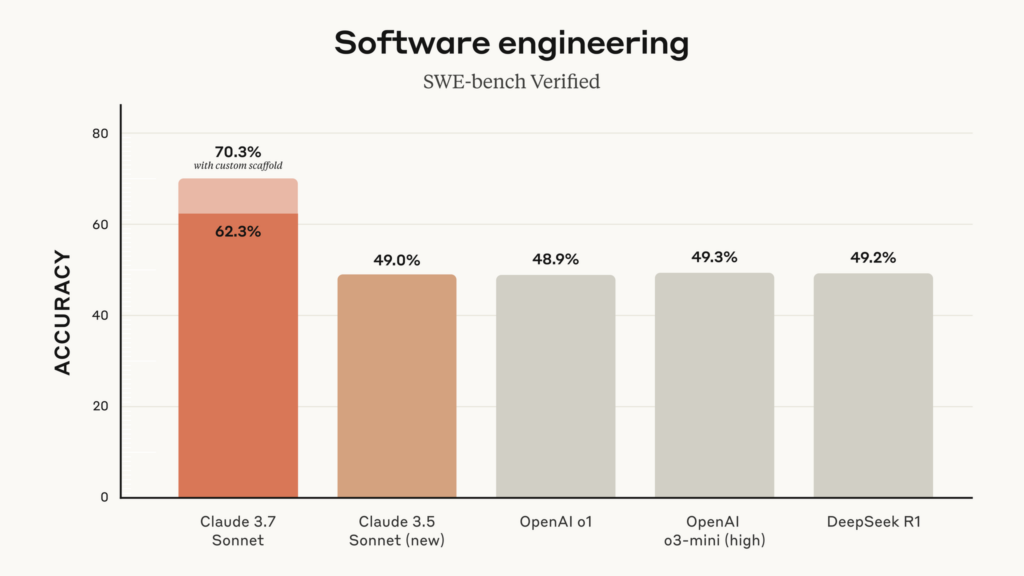
- 真实场景编码能力:在权威评测SWE-bench Verified(评估真实软件问题解决能力)中,Claude 3.7以70.3%的准确率远超OpenAI o3-mini(49.3%)、DeepSeek R1(49.2%)和GPT-4o(62.1%)。
- 全栈开发支持:可处理复杂代码库重构、自动化测试、Bug修复等任务,例如生成生产级前端代码时错误率降低45%。
- 工具生态升级:配套工具Claude Code可直接在终端执行代码搜索、测试运行、GitHub提交等操作,单次任务节省45分钟以上人工时间。
2. 混合推理架构:速度与深度的完美平衡
- 双模式设计:
- 标准模式(Standard):实时响应,适用于日常对话和简单查询(如“埃菲尔铁塔高度”),速度较前代Claude 3.5 Sonnet提升20%。
- 扩展思考模式(Extended Thinking):展示完整推理链,显著提升数学、物理、逻辑问题的解决能力。例如,在解决蒙提霍尔问题时仅需52秒,并展示分步逻辑推导。
- 可控成本:用户可通过API设置“思考预算”(最高128K token),在速度、成本和质量间灵活权衡。
3. 多模态与复杂任务处理
- 复杂的代码需求得到满足:尝试使用Claude 3.7 sonnet 完成复杂的编码对多场景多交互的任务明显提高,在设计场景和道具也加入了很多创新。
- 多模态输入:支持文本、图像、代码混合输入,例如上传设计稿后生成生产就绪的前端代码。
4. 数学与科学推理:实用导向优化
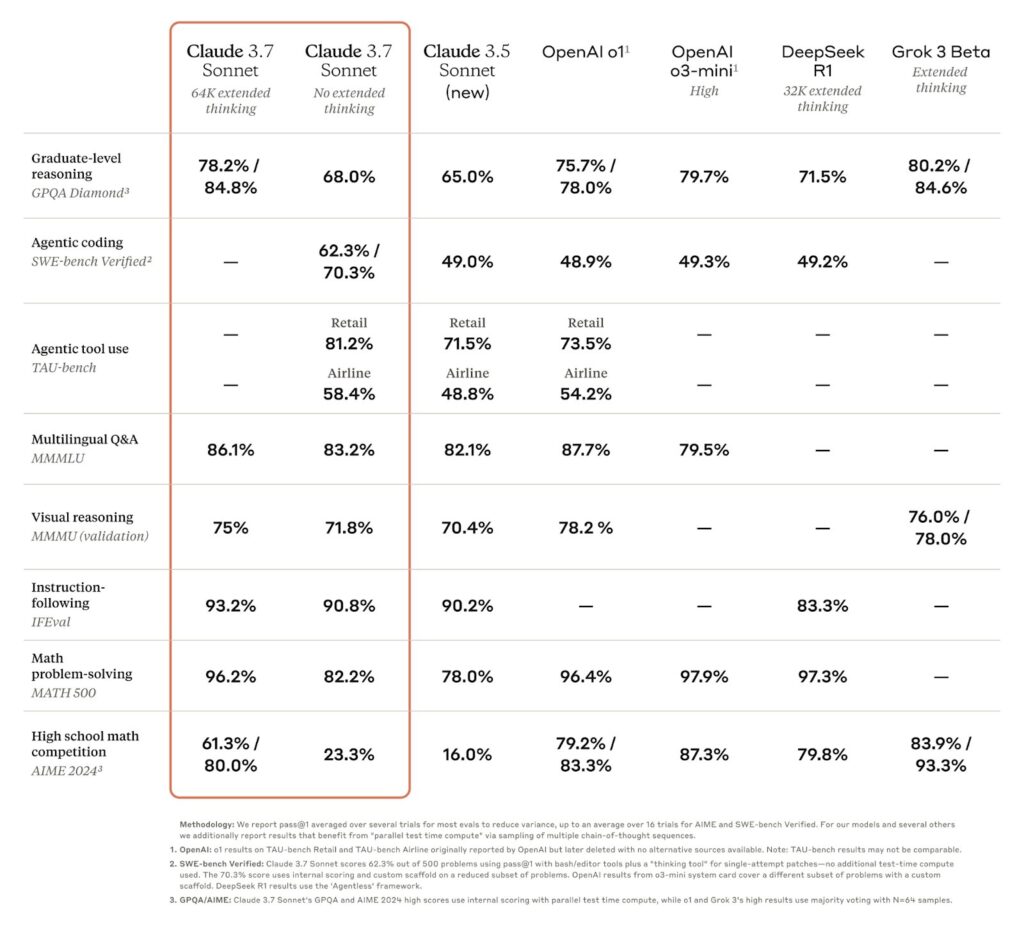
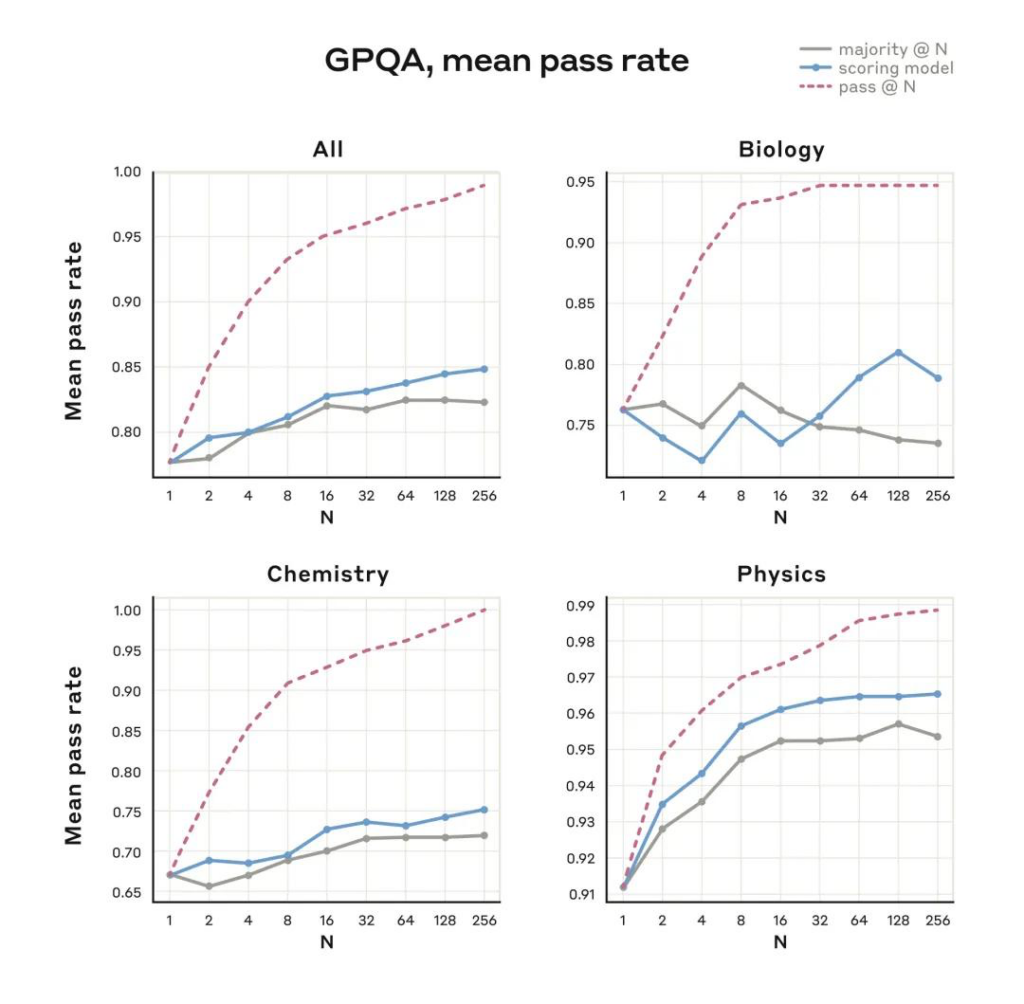
- 竞赛题表现:在GPQA Diamond等学术测试中,Claude 3.7的数学准确率(78.2%)仍略逊于DeepSeek-R1(97.3%),但通过扩展模式可提升至接近人类专家水平。
- 企业场景适配:减少对竞赛题的专项优化,转向解决现实业务问题(如供应链建模、金融数据分析)。
与主流模型横向对比
| 维度 | Claude 3.7 Sonnet | OpenAI o3-mini | DeepSeek-R1 | Grok-3 Beta |
|---|---|---|---|---|
| 编码能力 | SWE-bench 70.3%(行业第一) | 49.3% | 49.2% | 未公布 |
| 数学推理 | 扩展模式显著提升,但仍落后R1 | 中等(竞赛题优化不足) | 领先(GPQA 97.3%) | 强(AMIE 2024测试) |
| 成本 | 输入3/M,输出15/M(含思考token) | 低(约0.5-1$/M) | 性价比高(2.5$/M) | 未公布 |
| 透明度 | 展示部分推理链 | 黑箱输出 | 部分展示自纠正步骤 | 未公布 |
进步总结:技术跃迁与生态革新
- 架构革命:全球首个“混合推理模型”,打破传统AI单一响应模式,实现速度与深度统一。
- 企业级实用化:从代码生成到复杂决策,覆盖80%软件开发场景,被Canva评价为“具有卓越设计品味”。
- 成本控制创新:思考预算机制允许用户按需分配算力,避免资源浪费。
- 多领域渗透:从游戏代理到医疗诊断辅助,展现通用型AI潜力。
未来展望
Claude 3.7 Sonnet编码能力是毋庸置疑的。在平时工作中,我也非常喜欢使用它来做编码任务来完成一些复杂和特别的业务处理搭配其他的AI做规划和统计都非常高效。在未来,我觉得会出现更多这样的AI模型,让我们的工作还是生活都更加便捷,或许有一天AI真能取代一部分程序员的工作。


文章评论