在AI绘画的浪潮中,我们见证了太多奇迹:一句话生成一座赛博朋克都市,一个词绘出一片梵高星空。但在这片繁华之下,一直有个令人啼笑皆非的“老大难”问题——AI不会写字。 你让它画个“开业大吉”的招牌,它可能给你“开吉大业”;你想要一句“清风徐来”,它却生成一堆形似而非的乱码。这种“文盲”式作画,让我们在赞叹其想象力的同时,也对其基本功感到无奈。我们似乎默认了,AI的画笔,挥洒的是艺术,而非文字。 直到现在,阿里巴巴通义千问团队带着 Qwen-Image 走来,大声宣布:这个时代结束了。 不只是“能写”,而是“会写”的降…

就在昨天,AI 圈子迎来了一次不大不小的地震。当大家还在讨论下一个千亿模型将如何改变世界时,阿里通义千问悄悄扔出了一颗重磅炸弹:Qwen3-30B-A3B-Thinking-2507。 别被这串复杂的代号劝退,简单来说,这是一个你可以在自己电脑上运行,但在“思考”这件事上,足以让一些闭源巨头捏一把汗的“本地怪兽”。 硬核到离谱的推理能力 我们先不谈虚的,直接上战绩。 过去,中等尺寸的模型在专业数学和复杂逻辑上总是力不从心,这几乎成了一条铁律。但 Qwen3-30B-Thinking 打破了它。在顶级的专业数学评测 …

在AI生成内容的浪潮之巅,视频领域始终是那块最难啃的硬骨头。当许多人还在为生成画面的稳定性和真实感苦恼时,阿里通义万相Wan2.2携着一身“黑科技”悄然登场,它所做的不仅仅是迭代,更像是一场对视频创作门槛的颠覆性革命。 两位“专家”,一位导演——聊聊它的智慧核心 想象一下,拍摄一部电影,你需要一位总揽全局的导演,负责构图和故事节奏;还需要一位精益求精的摄影师,负责光影和细节质感。Wan2.2的“混合专家(MoE)”架构,正是这样做的。 这是业界首次将MoE引入视频模型。它巧妙地将模型分为“高噪声专家”和“低噪声专家…
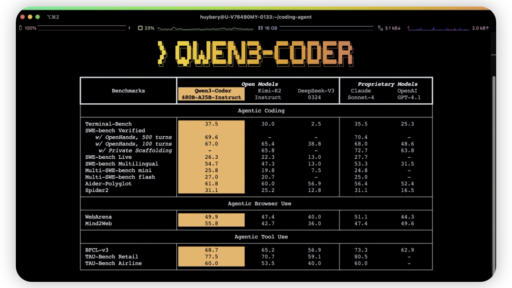
AI编码的江湖,风云再起。 当我们还在讨论各种模型谁的代码补全更丝滑时,阿里通义千问团队直接掀了桌子,扔出了一枚重磅炸弹:Qwen3-Coder-480B-A35B-Instruct。别被这长长的名字吓到,你可以简单地理解为,一个为“代理编码”(Agentic Coding)而生的开源巨兽,正向我们走来。 这头“巨兽”有多庞大? 首先,我们得聊聊它的体格,这实在令人印象深刻。 它是一个拥有4800亿总参数的混合专家(MoE)模型。这是什么概念?意味着它的知识库和潜在能力是极其浩瀚的。但更巧妙的是,它在工作时并不需要…

你是否已经厌倦了千篇一律、毫无感情的AI语音?现在,改变的时刻到了!阿里巴巴通义千问团队重磅发布了全新的语音生成模型——Qwen-TTS,它不仅能说一口流利的中英双语,更能“飚”起地道的方言,让你的AI从此有了乡音、有了情感、有了“人味儿”! 核心亮点:不止普通话,更是家乡话 Qwen-TTS 本次最令人惊艳的突破,莫过于对三种特色中文口音的精准还原: 地道京味儿(音色: Dylan): “那都不是事儿!”一口纯正的京腔,带着标志性的儿化音,无论是讲故事还是侃大山,都京味儿十足。 吴侬软语(音色: Jada): “…

最近AI圈又热闹起来了,特别是音频领域!我们都知道,语音识别(ASR)和音频理解是大模型“听世界”的关键能力,而市面上那些表现顶尖的模型,往往参数量都非常庞大,对算力要求很高,部署起来可不是件轻松的事。 但今天我们要聊的这位新玩家,绝对是个值得关注的黑马——它就是刚刚由LMMs-Lab发布的Aero-1-Audio模型! 别看它参数只有 1.5个亿 (1.5B),妥妥的轻量级选手,但它带来的技术突破和性能表现,用“小身材、大能量”来形容一点不夸张。 小巧,却有硬核实力:1.5B参数的意义 在我们习惯了动辄百亿、千亿…

全世界的AI圈子,似乎都在屏息等待。从各种小道消息到官方偶尔泄露的只言片语,过去这一个月,大家都在猜测阿里通义千问的下一代大模型——Qwen3,到底会带来怎样的惊喜。今天,靴子终于落地!Qwen3 正式发布,我只能说:这一个月,值了!它不仅仅是升级,更像是一场开源大模型的“范式革新”。 如果让我用一句话概括 Qwen3 的核心印象?那就是:思考更深,速度更快。 这听起来有点矛盾?别急,这恰恰是 Qwen3 最具颠覆性的地方。 告别“比肩”时代:它敢说自己是“全球最强开源”! 敢说自己是“全球最强开源模型”,这底气从…
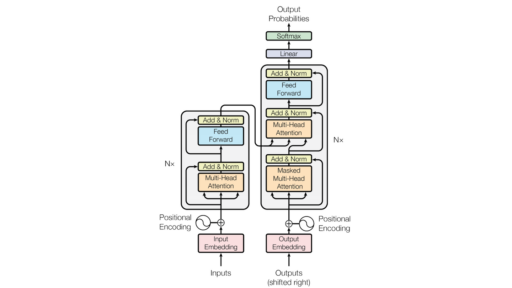
模型介绍 Qwen2.5-VL 是阿里云通义千问系列模型中的重要成员,专注于 多模态理解 领域。"VL" 代表 Vision-Language (视觉-语言),表明该模型的核心能力在于理解和处理图像信息,并结合语言进行交互。"chat" 则意味着它具备 对话能力,可以像聊天机器人一样与用户进行多轮对话,解答关于图像内容的问题,执行与图像相关的任务。"v1" 表示这是该模型的第一个公开版本,预示着阿里云在该领域持续投入和迭代的决心。 核心能力 Qwen2.5-VL 模型的核心优势在于其强大的 视觉理解和多模态交互能力…
引言 在人工智能浪潮中,大型语言模型 (LLMs) 扮演着至关重要的角色。2025 年初,Qwen2.5-max 和 DeepSeek R1 两大模型横空出世,代表了 LLM 技术的巅峰水平。本文将聚焦 Qwen2.5-max,深入剖析其特性,并对比 DeepSeek R1,详解二者的差异与应用场景,最后附上体验地址,助您选择最合适的模型。 🔥 Qwen2.5-max 模型:重磅详解 Qwen2.5-max,阿里云 Qwen 系列的最新力作,定位为大规模 MoE (Mixture-of-Experts) 模型,目标…

