当AI音乐的浪潮席卷全球,我们听过了无数技术上无可挑剔、却总感觉少了点“人味儿”的作品。它们能精准复刻旋律与和声,却难以捕捉一种更深邃的东西——文化的灵魂。直到2025年8月15日,昆仑万维在其“SkyWork AI技术发布周”的压轴日,为我们揭晓了Mureka V7.5,一个或许能改变这一切的模型。
它要解决的,不是AI音乐“能不能唱”的问题,而是“会不会唱”的艺术难题,尤其是在中文这个博大精深的语境里。
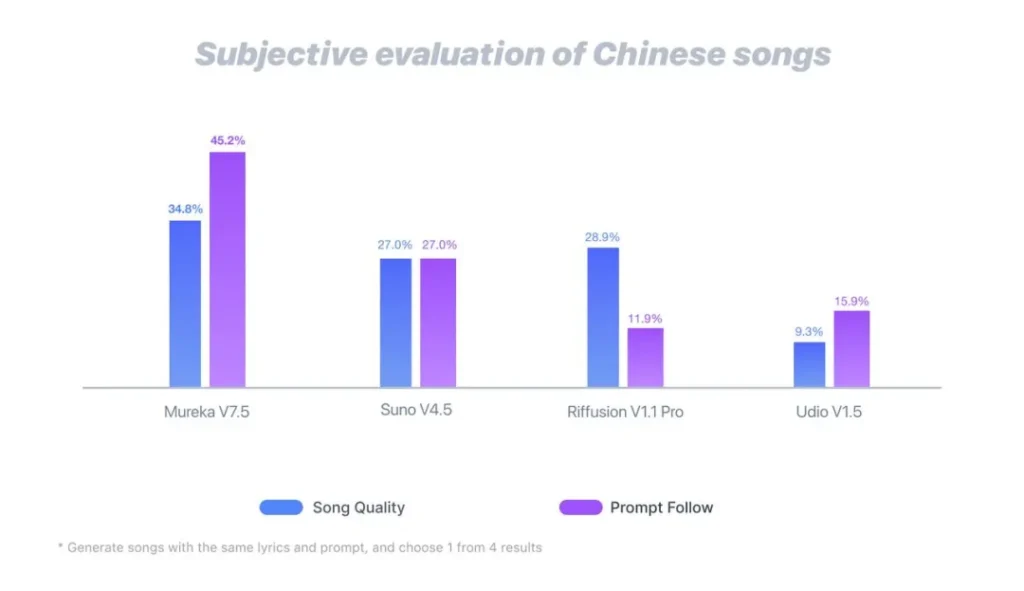
不只是“能唱”,而是“会唱”——注入灵魂的第一口气
以往的AI歌曲,特别是中文歌,常常败在两个字上:“生硬”。咬字像个初学中文的外国人,情感平得像一条直线。Mureka V7.5做的第一件事,就是彻底告别这种机械感。
想象一下,它不再是简单地将音符和歌词拼接,而是像一位资深的音乐制作人,去深度“研读”中文音乐的精髓。无论是戏曲里那九曲回肠的婉转唱腔,民谣中那娓娓道来的叙事感,还是华语流行乐里独特的节奏与顿挫,V7.5都经过了海量学习。
结果是,它生成的歌曲有了“呼吸感”。
这背后是一项巧妙的技术升级——优化的ASR(自动语音识别)。在这里,ASR不再是被动地听写,而是主动的“演唱分析师”。它会去解构真人歌手演唱时的气息控制、情感起伏和换气点,然后将这些带有生命力的细节,反馈给生成模型。
这就像教一个机器人画画,你不再只给它看成稿,而是让它观摩画家从落笔、运力到收笔的全过程。最终,AI学会的不再是模仿,而是演绎。
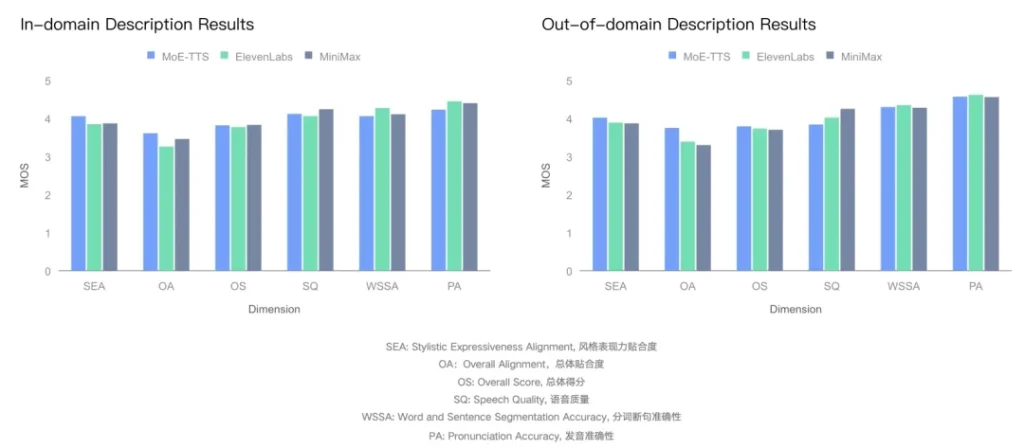
“给我一个清澈的少年音,尾韵带点磁性”——MoE-TTS的语言魔法
如果说Mureka V7.5解决了“唱”的问题,那同步发布的MoE-TTS框架,则彻底革新了“说”与“塑造声音”的方式。
过去,想让AI合成特定声音,我们得用一堆预设的、死板的标签去框定它,比如“男声-成熟-沉稳”。但如果你想要一种更微妙、更富想象力的声音呢?比如“像夏日午后透过树叶的光斑,温暖又带点慵懒”?传统模型多半会“不知所措”。
MoE-TTS(混合专家语音合成)的登场,就像是为AI配上了一个文学家的大脑。它首次将LLM(大语言模型)的文本理解能力与专门的语音模块解耦,再通过“模态路由”巧妙地结合起来。
简单来说,团队里有了分工:一个“语言专家”负责深刻理解你用自然语言描述的任何天马行空的意境,另一个“声音专家”则心无旁骛地将这种理解转化为精准的声音。两者各司其职,互不干扰。
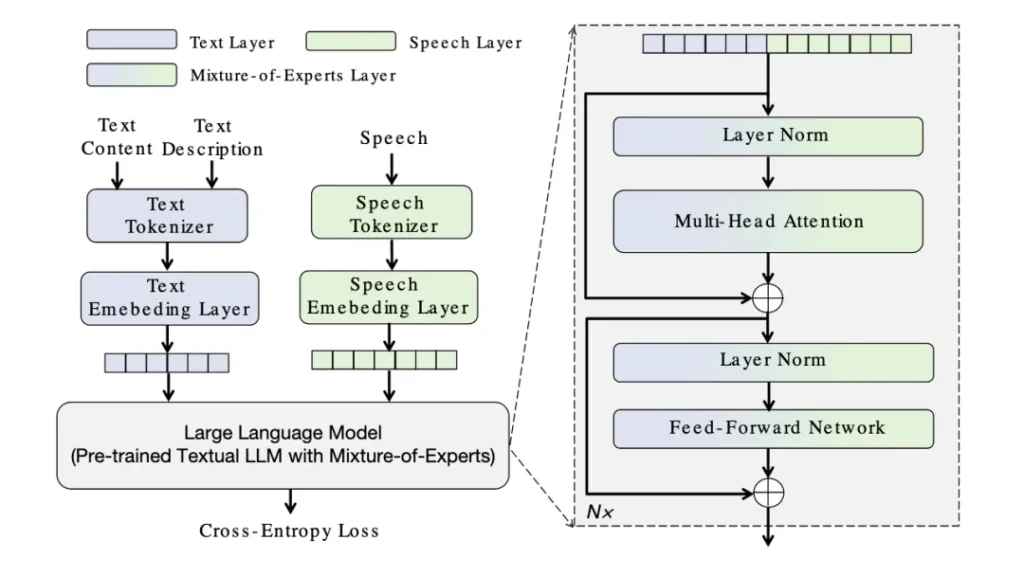
这意味着,创作者终于可以摆脱标签的束缚,用诗意的语言去“指挥”声音,无论是为虚拟偶像定制专属声线,还是为游戏角色赋予独一无二的灵魂,都变得前所未有的自由。更重要的是,昆仑万维选择将这个框架开源,这无疑是向整个行业发出了一份邀请:让我们共同迈入语音合成的“自由描述”时代。
从实验室到舞台,AI艺术的文化自觉
Mureka V7.5的发布,不仅仅是一次版本迭代。它更像是一种宣言,标志着中国的AI技术开始从追赶走向探索,从泛泛的通用能力,转向对本土文化的深度挖掘与融合。
当AI不再满足于生成一首旋律正确的歌,而是开始追求中文歌词的韵律之美、东方情感的含蓄表达时,它就不再是一个冰冷的工具,而是一个拥有了“文化自觉”的创作伙伴。
目前,Mureka V7.5已在全球官网上线。这不仅是昆仑万维的一次技术亮剑,更是送给所有创作者的一份礼物。它预示着一个新纪元的到来:未来的AI艺术,比拼的或许不再是算力,而是那份对文化与人心的深刻洞察。

如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论