最近AI圈又热闹起来了,特别是音频领域!我们都知道,语音识别(ASR)和音频理解是大模型“听世界”的关键能力,而市面上那些表现顶尖的模型,往往参数量都非常庞大,对算力要求很高,部署起来可不是件轻松的事。
但今天我们要聊的这位新玩家,绝对是个值得关注的黑马——它就是刚刚由LMMs-Lab发布的Aero-1-Audio模型!
别看它参数只有 1.5个亿 (1.5B),妥妥的轻量级选手,但它带来的技术突破和性能表现,用“小身材、大能量”来形容一点不夸张。

小巧,却有硬核实力:1.5B参数的意义
在我们习惯了动辄百亿、千亿参数的大模型时代,一个1.5B参数的模型听起来似乎有点不够看。但Aero-1-Audio证明了,参数效率同样可以做到极致。
想象一下:
- 更低的部署成本: 不需要昂贵的计算资源,更容易在普通服务器、甚至性能更好的边缘设备上运行。
- 更快的推理速度: 参数少了,计算量自然降低,响应速度更快,尤其适合需要实时处理的场景。
- 更广的应用范围: 有机会将高性能的音频AI能力普及到手机、智能音箱等资源受限的终端设备上。
Aero-1-Audio的厉害之处就在于,它在如此“苗条”的身材下,性能竟然能直逼甚至超越了Whisper(比如Large v3版本)、Qwen-2-Audio这些大家伙!这波操作,可以说是相当炸裂了。
它是基于阿里开源的Qwen-2.5-1.5B语言模型构建的,这给它打下了良好的基础,让它不仅能“听见”,还能更好地“理解”和“回应”。
告别“切香肠”模式:15分钟连续音频处理才是王道!
但Aero-1-Audio最让我眼前一亮、也是解决行业痛点的核心亮点,还得是它的长音频处理能力!
大家做过音频处理的都知道,处理一段很长的音频(比如一个小时的会议录音、一场完整的讲座)时,传统方法是无奈之举——必须先把音频切成小块(比如每段30秒),然后让模型一段一段地处理,最后再把结果拼接起来。
这样做有什么问题?
- 上下文丢失: 模型每次只能听到一小段,无法感知整段音频的全局上下文,导致对长对话的理解脱节。
- 边界错误: 切割点附近容易出现识别错误、词语重复或遗漏。
- 连贯性差: 拼接起来的文本可能不够流畅自然。
Aero-1-Audio直接硬刚这个问题!它最厉害的地方在于,能够连续处理长达15分钟的音频,而且完全无需进行分割!
这意味着什么?
模型可以一次性“听”完长达15分钟的完整内容,从头到尾把握其中的逻辑、语境和人物关系(如果支持多说话人的话)。这对于理解长对话、保持转录的流畅度和准确性来说,简直是质的飞跃!
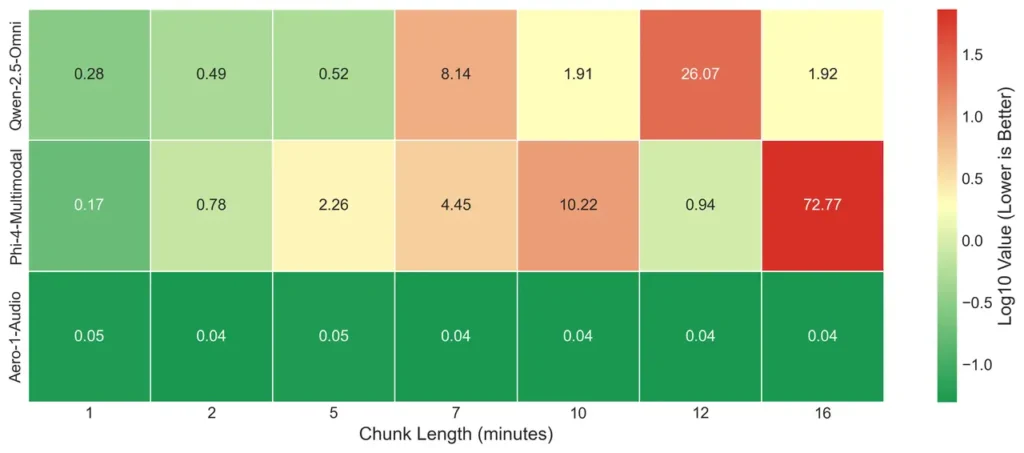
这种端到端的长音频处理能力,显著提高了模型在处理会议、访谈、讲座等场景时的连贯性和稳定性。
性能硬碰硬:不虚SOTA大模型
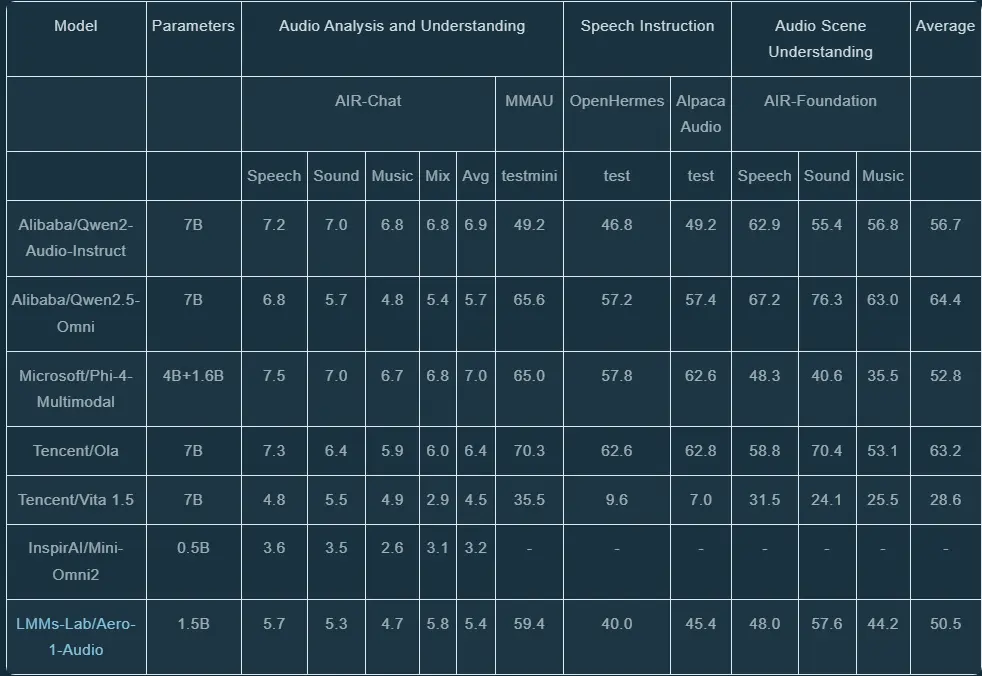
光说不练假把式。Aero-1-Audio在多个音频基准测试上的表现,证明了它的轻量化并非牺牲性能换来的。
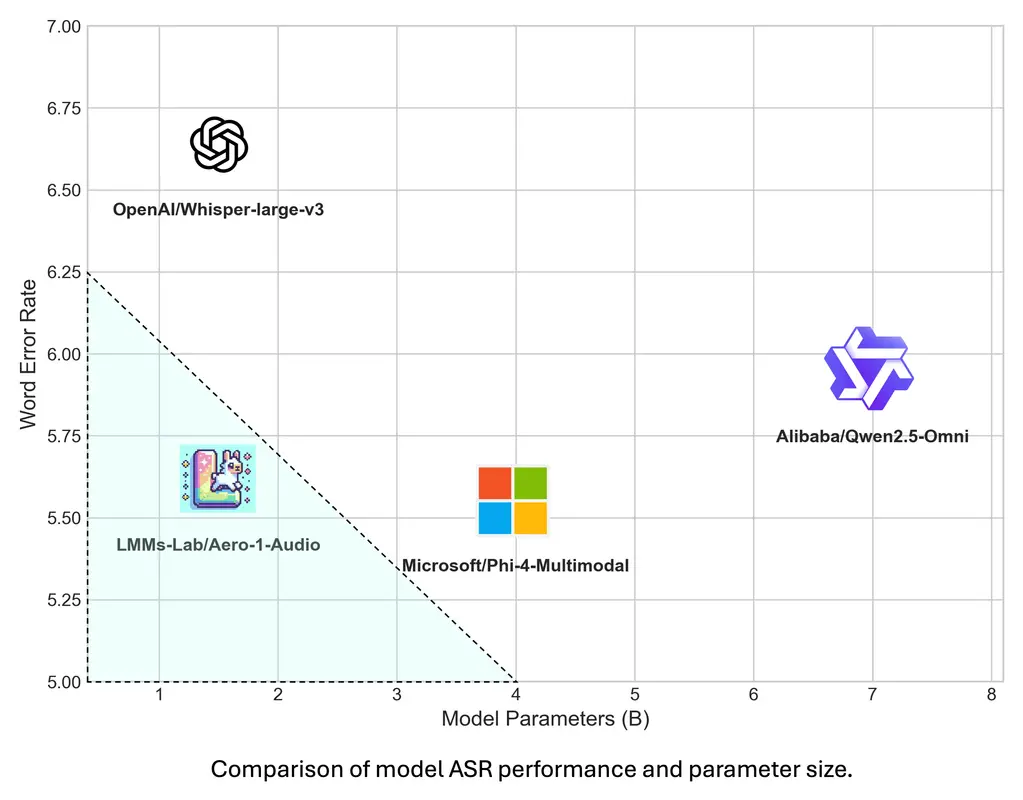
在标准的语音识别(ASR)任务上,它与Whisper Large v3、Qwen-2-Audio等模型进行了对比。结果显示,在一些关键数据集上,Aero-1-Audio的词错误率(WER)能达到相当甚至更低的水平。
例如,在干净的LibriSpeech Clean数据集上,Aero-1-Audio的WER低至1.49,而Whisper-Large-v3是1.58。在AMI会议数据集上,Aero-1-Audio的WER是10.53,而Phi-4-Multimodal是11.45。这些数字直观地反映了其强大的基础ASR能力。
而且,在考验长音频处理能力的测试中,Aero-1-Audio在未分段音频上的性能下降幅度远小于其他需要分割处理的模型,再次证明了其长上下文能力的优势。
除了ASR,Aero-1-Audio在音频理解、根据语音指令执行任务等方面也表现不俗,显示出其作为多模态(音频+文本)模型的基础潜力。
训练快、数据省:高效是关键词
这种“小而强”的背后,离不开高效的训练策略。
Aero-1-Audio的训练过程非常高效:
- 仅使用了16块H100 GPU
- 训练时间不到24小时
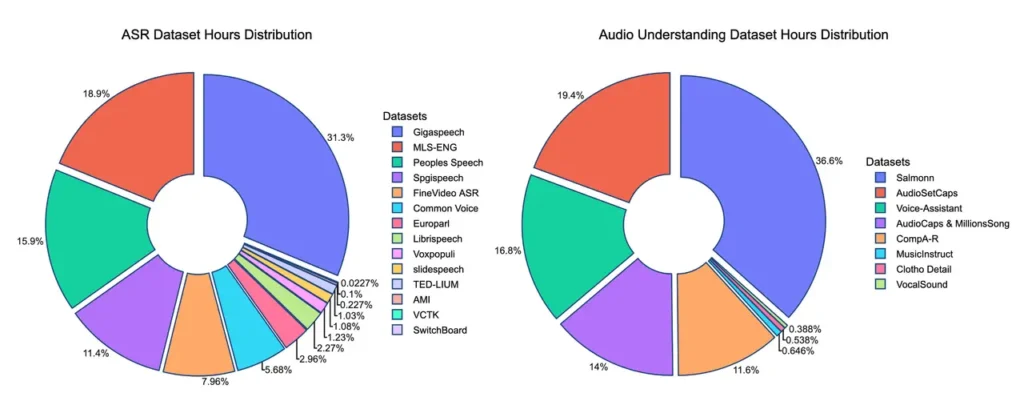
- 训练数据量约5万小时音频(5亿 tokens),这个数据量比很多同类模型(比如Qwen-Omni、Phi-4)少了100倍以上!
这说明Aero-1-Audio在样本效率上做得非常好,通过高质量的数据过滤和优化的训练方法,用相对较少的数据和资源,达到了高性能。这对于未来模型的迭代和训练成本控制至关重要。
开源!Demo已上线!
更让人兴奋的是,Aero-1-Audio已经在Hugging Face上开源了!这意味着开发者和研究人员可以轻松获取模型权重,上手体验和集成应用。
官方也在Hugging Face Spaces上提供了Gradio Demo,大家可以直接上传音频文件(最长15分钟),亲手体验一下它的转录和理解效果。
通过标准的transformers库,使用Python调用Aero-1-Audio的代码也非常简洁方便。
总结:AI音频的新篇章?
总而言之,Aero-1-Audio作为一款参数仅1.5B的轻量级音频模型,在ASR和音频理解任务上展现了比肩甚至超越SOTA大模型的性能,尤其它无需分割即可处理15分钟连续长音频的能力,无疑是音频AI领域的一个重要突破。
它在参数效率、训练效率和长上下文处理上的优势,使其在资源受限环境下的应用前景十分广阔,为高性能音频AI的普及打开了新的大门。
如果你对AI音频感兴趣,或者正愁找不到一个轻量级又强大的音频模型,Aero-1-Audio绝对值得你关注和尝试!快去Hugging Face体验一下吧!
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论