2026年的开年大戏,比我们预想的来得更早了一些。
就在1月22日,当大家还在讨论大语言模型的逻辑推理能力时,阿里通义千问团队悄无声息地在语音生成领域扔下了一枚重磅炸弹:Qwen3-TTS系列模型正式开源。
这不仅仅是“又一个”开源模型,这是一次对“实时交互”的暴力美学展示。作为长期关注AI底层技术的观察者,我拿到技术报告的第一眼,就被那个数字击中了——97毫秒。
今天,我们就来聊聊这个让开发者直呼“真香”,让商业闭源模型感到压力的Qwen3-TTS到底强在哪里。
告别进度条:当生成速度快过你的语速
过去两三年,语音合成(TTS)最大的痛点是什么?是延迟。
你对着AI助手说了一句话,屏幕转圈圈,三秒后它才慢条斯理地开口。这种割裂感,是阻碍AI像真人一样交流的最大那堵墙。
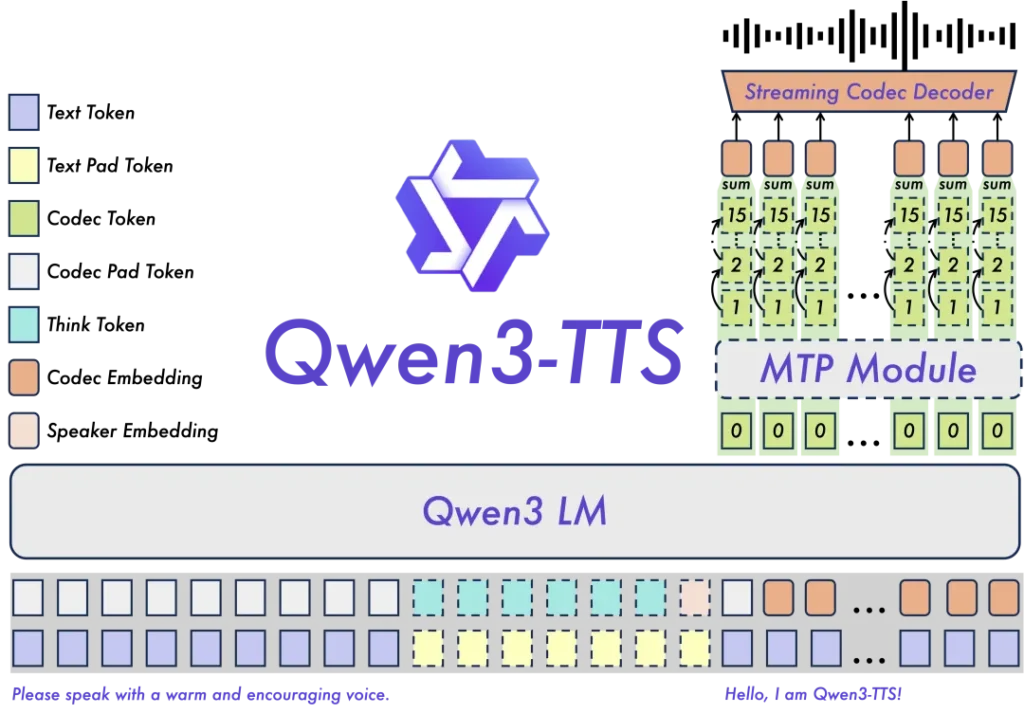
Qwen3-TTS最核心的突破,在于它自研的“Dual-Track双轨混合流式生成”架构。通俗点说,以前的模型是“想好整句话再开口”,而Qwen3-TTS是“边想边说”。配合极其高效的12.5Hz多码本语音编码器,这个模型实现了只要你输入第一个字,音频数据包几乎同时也准备好了。
97毫秒的端到端延迟是什么概念?人类眨眼一次大约需要300毫秒。也就是说,在你还没眨完眼的瞬间,声音已经出来了。这意味着在直播、实时同传、甚至不仅是客服,而是真正拟人化的AI伴侣场景中,机器的反应速度终于追上了人类的生理直觉。
上帝视角:捏出你想要的声音
除了快,Qwen3-TTS还解决了一个“像不像”的问题。
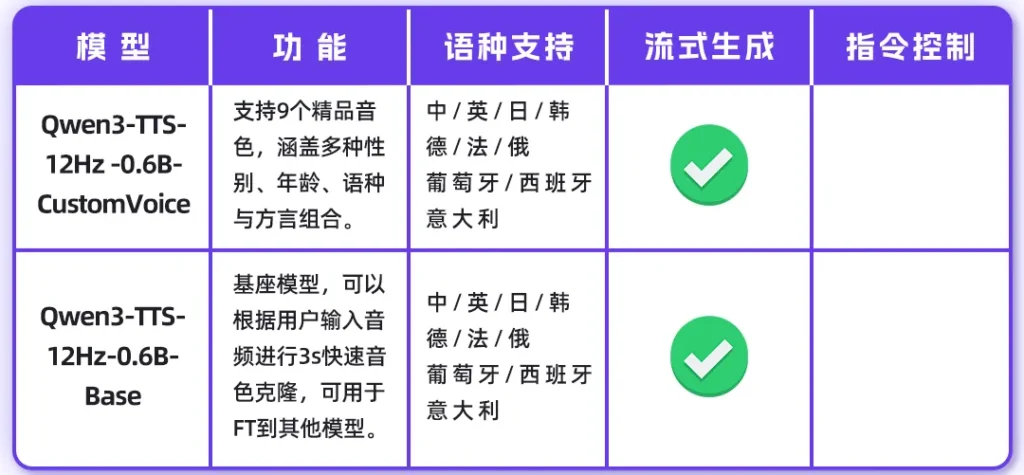
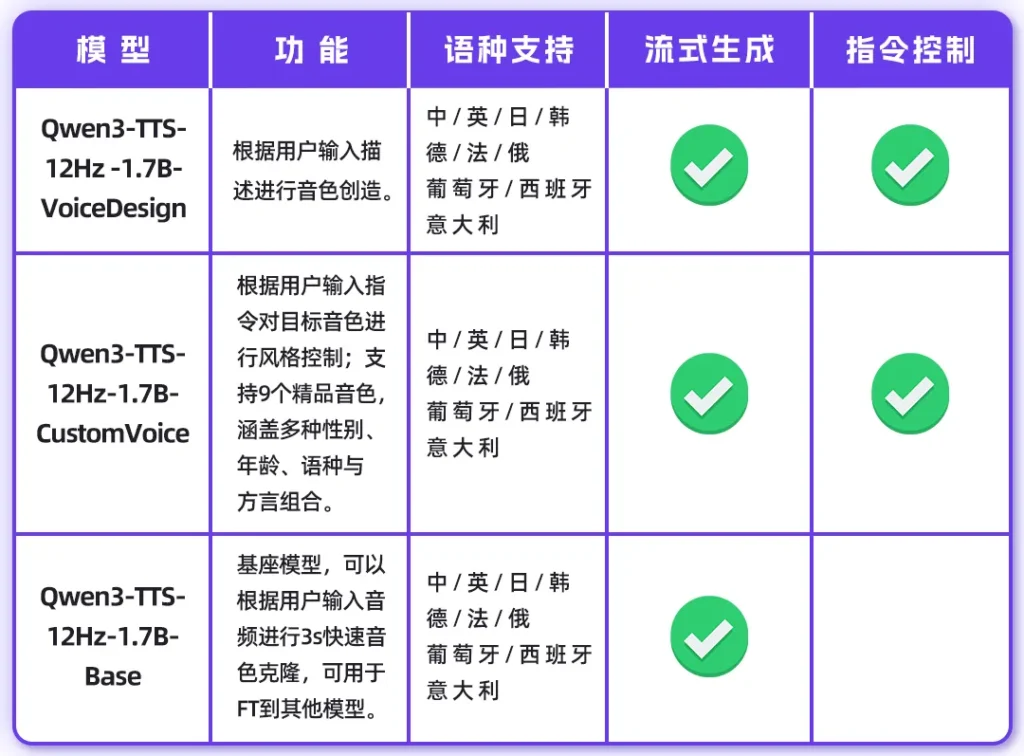
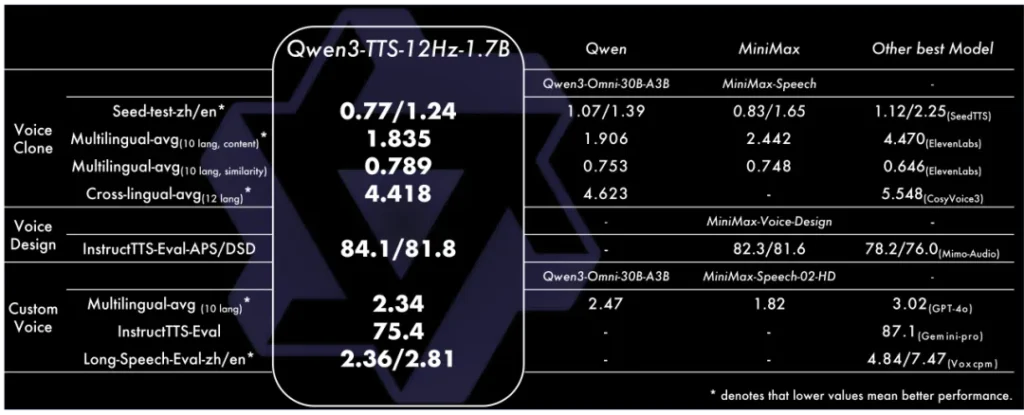
这次开源提供了两个参数量级:0.6B和1.7B。其中1.7B版本不仅是性能怪兽,更是一个声音设计师。
以前我们要定制音色,往往需要录制几小时的干音,各种清洗数据,流程繁琐。现在,Qwen3-TTS把这个门槛降到了地板上。
音色克隆:只需要3秒。是的,你没看错,一段3秒的参考音频,它就能精准捕捉到音色特征。而且不仅是复制声音,它还能跨语言。你给它一段中文录音,它能用同样的音色说出流利的法语或俄语。
音色创造:这才是最好玩的地方。如果你连参考音频都没有,完全没问题。你可以像写小说一样用自然语言描述:“一个清澈的年轻女声,语气里带着一点欢快和调皮。”模型就能根据这段Prompt,凭空“捏”出一个符合要求的声音。这种基于指令的控制能力,直接把导演的活儿交给了用户。
十国语言,方言也不在话下
在全球化支持上,通义千问这次也是诚意满满。模型原生支持中文、英语、日语、韩语、德语、法语、俄语、葡萄牙语、西班牙语、意大利语这10种主流语言。
更有趣的是,它懂方言。四川话的麻辣、粤语的抑扬顿挫,它都能拿捏。在长文本测试中,即便是合成10分钟的长语音,中英文的词错率也控制在了2%左右的极低水平,这意味着它完全具备了制作有声书、长视频配音的生产力水准。
开源的诚意:Apache 2.0
最后,不得不提的是这次的开源策略。
没有遮遮掩掩,没有仅供研究。Qwen3-TTS直接采用了Apache 2.0协议,这意味着不管是个人开发者想做个好玩的Demo,还是初创公司想把它集成到商业产品里,大门都是敞开的。
如果你追求极致效果,选1.7B模型;如果你资源有限,需要在边缘设备上跑,0.6B模型就是为你准备的。代码、权重、文档,全部在GitHub、Hugging Face和ModelScope上整整齐齐地摆好了。
总的来说,Qwen3-TTS的出现,标志着高质量语音生成技术不再是少数大厂的专利。从今天开始,任何一个普通开发者,都有能力构建出那个《Her》电影里一样,反应敏捷、声音动听的AI伙伴。
语音交互的“iPhone时刻”,或许真的就在2026年的这个一月,悄然开始了。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


