2026年刚开年,开源AI社区就迎来了一个重磅玩家。
这次不再是单纯比拼谁的参数更大、谁聊闲天更溜,美团LongCat团队直接把桌子掀了,端上来一盘硬菜:LongCat-Flash-Thinking-2601。这名字听着挺长,其实核心就讲了一件事——让AI学会像人类专家一样,遇到难题先别急着张嘴,停下来,多想几遍。
很多开发者在这个模型发布后惊呼,这可能是目前最接近“系统2”思维(慢思考)的开源尝试。今天咱们就抛开那些晦涩的论文公式,聊聊这个模型到底神在哪儿,以及它为什么敢说自己在复杂任务上超越了Claude-Opus-4.5。
拒绝“直觉式”回答:什么是重思考模式?
以前的大模型,哪怕是所谓的推理模型,大多还是“单线程”的。你问个问题,它顺着逻辑链条往下编,一旦中间某一步走歪了,后面就全崩了。
美团这次搞了个创新,叫“Heavy Thinking Mode”(重思考模式)。这玩意儿有点意思,它模仿了人类面对极难数学题或者复杂代码bug时的状态。
当你开启这个模式,LongCat并不是马上给你答案,而是同时启动8个独立的“大脑”(推理路径)。
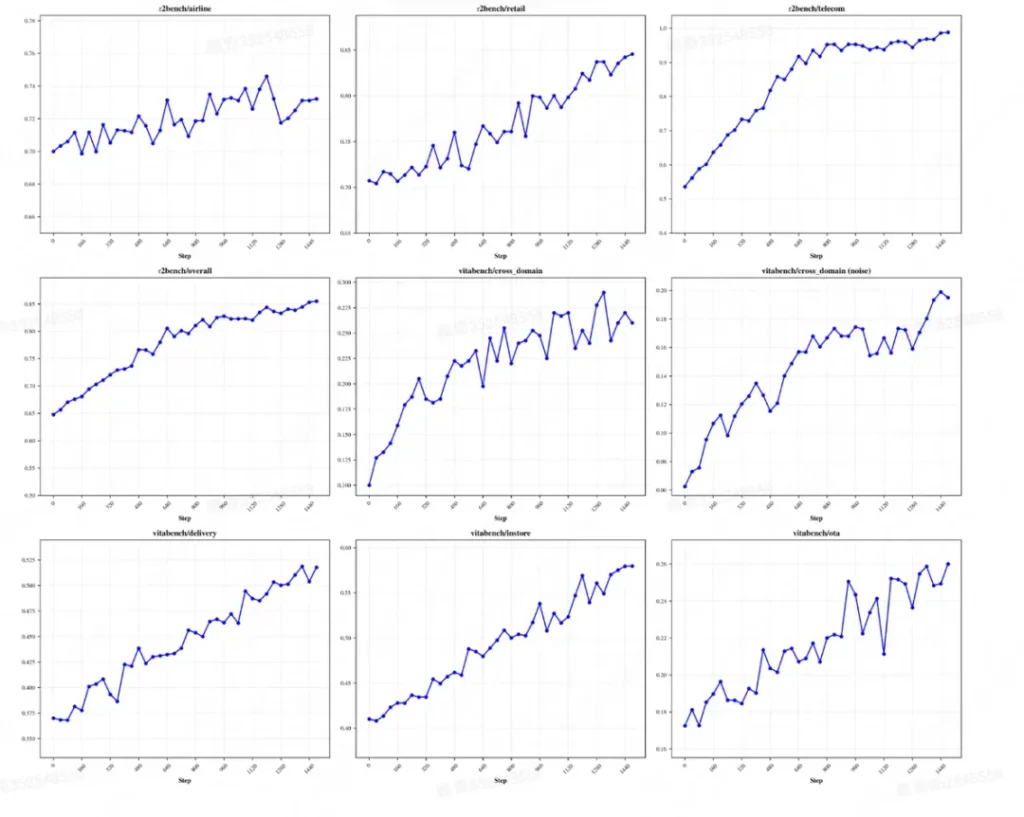
想象一下,这就像是开了一个圆桌会议。面对你的问题,8个分身同时开始解题,有的试代数法,有的试几何法,有的查文档,有的写伪代码。它们互不干扰,各自探索。
这还没完,等大家都思考得差不多了,进入第二阶段:总结归纳。模型会把这8条路径的结果拿来进行比对、验证、去伪存真,把最好的思路像拼积木一样通过“闭环迭代”合成起来,最后才慎重地给你输出一个结果。
这套“想清楚再行动”的机制,直接让它在处理高难度、不确定性任务时的可靠性上了个大台阶。
数据不会撒谎:满分的数学与硬核的实战
咱们来看看成绩单,这也是大家最关心的部分。
在AIME-25(美国数学邀请赛)的评测基准上,开启重思考模式后的LongCat直接拿下了100.0的满分。在IMO-AnswerBench(国际奥数级别)上也拿到了86.8分,稳坐目前开源模型的头把交椅。
但真正让圈内人感到兴奋的,其实是它的工具调用(Agent)能力。
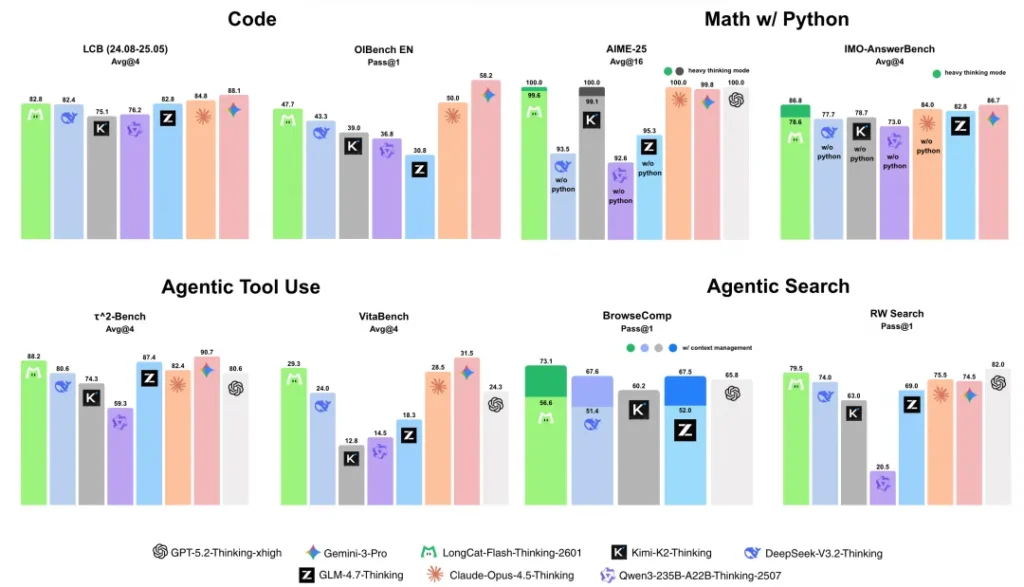
现在的大模型,做数学题只是基本功,能不能熟练使用工具、搜索信息、解决实际问题才是落地的关键。美团官方披露,在依赖工具调用的随机复杂任务中,LongCat的表现超越了Claude-Opus-4.5-Thinking。
注意,这里强调的是“随机复杂任务”。这意味着它不是靠死记硬背常见的API文档,而是真具备了极强的泛化能力。哪怕你给它一个从未见过的、充满随机性的烂摊子工具箱,它也能通过那套“并行思考”机制,试错、调整,最终把活儿干漂亮。
在τ²-Bench基准测试中,它拿到了88.2分;在BrowseComp(智能体搜索能力)上拿到了73.1分。这些数据说明,它不仅是个做题家,更是个实干家。
技术底座:不仅仅是大
LongCat-Flash-Thinking-2601是基于混合专家架构(MoE)构建的。
总参数量达到了560B(5600亿),听起来吓人对吧?但别慌,得益于MoE架构,它在推理时的激活参数只有约27B。这意味着它既拥有巨型模型的知识储备,又能保持相对高效的推理速度(每秒100+ tokens)。
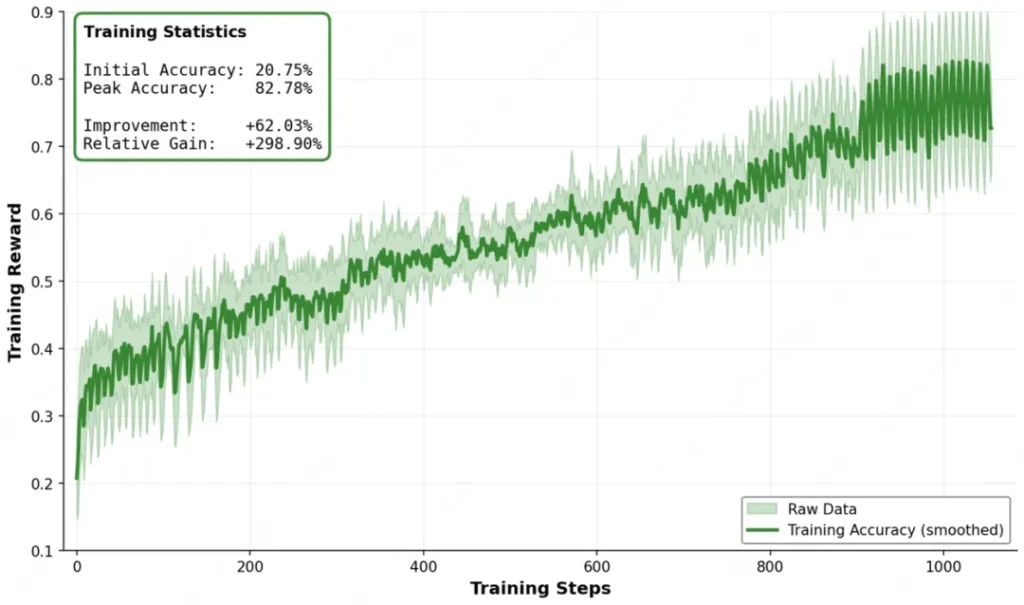
而且,它的训练方式堪称“斯巴达式”。
为了让模型抗造,团队搞了个“高强度练兵场”。他们在训练数据里故意掺沙子——注入API调用失败、网络超时、返回异常数据等噪声。这种“抗干扰训练”让模型养成了很好的心态:遇到报错不发疯,而是冷静地分析原因,换个姿势继续尝试。这就是为什么它在真实世界的复杂环境中表现得特别稳。
写在最后
美团这次非常地道,不仅仅是发了论文,而是把代码、模型权重全都在GitHub和Hugging Face上开源了,甚至还提供了免费的在线体验和API额度。
对于开发者来说,LongCat提供了一个极具价值的新选择:当你需要一个能处理复杂逻辑、能容忍环境噪声、且具备深度推理能力的智能体核心时,不需要再死磕昂贵的闭源API了。
在这个浮躁的时代,愿意花时间教AI“三思而后行”,本身就是一件值得长期主义者点赞的事。如果你对AI的逻辑推理能力有高要求,LongCat绝对值得你去拉下来跑一跑。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


