在今天这个大模型参数军备竞赛几乎白热化的时代,我们似乎已经习惯了用“更大、更多、更强”来衡量进步。但当所有人都盯着千亿、万亿参数的星辰大海时,总有一些团队在默默打磨着另一条路:如何用更精巧的结构,榨干每一分算力的潜力?
最近,快手Klear团队扔出的Klear-Reasoner模型,就像是在这股“大力出奇迹”的浪潮中,注入了一股清流。它基于平平无奇的Qwen3-8B-Base,却在数学和代码这两个公认的硬骨头任务上,交出了一份令人侧目的成绩单。
这不禁让人好奇,他们到底做了什么?
核心的魔术:那个叫GPPO的“松绑”算法
如果你常在AI圈里混,对PPO(近端策略优化)这个词一定不陌生。它是强化学习里的常客,稳定、好用,但也有个出了名的“毛病”:为了训练稳定,它会用一个“夹子”(Clipping)把过于激进的更新策略给“夹”住。
这就像一个严厉但有点死板的老师。
- 当模型灵光一闪,想尝试一个天马行空的解法时(高熵token),老师会说:“不行,太冒险了,不准试。” 于是,探索的火花被无情掐灭。
- 当模型犯了个错,但这个错误其实很有启发性时(负样本),老师会说:“错了就是错了,下次注意。” 于是,从失败中学习的机会也被大大削弱。
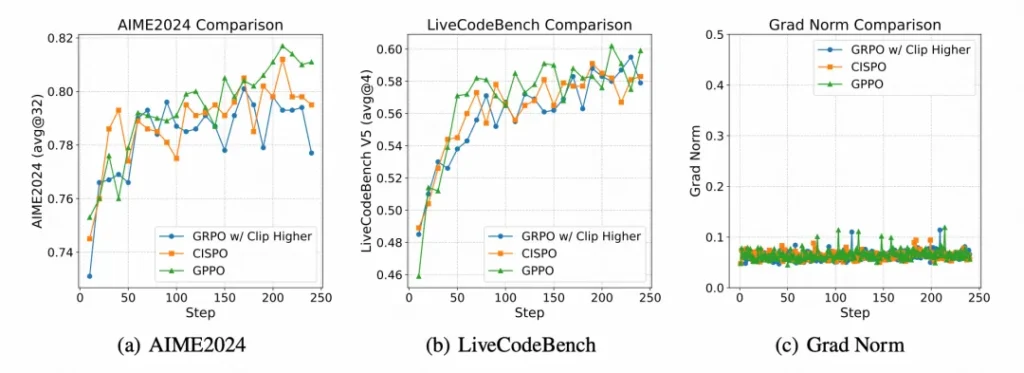
Klear-Reasoner的核心创新——GPPO(梯度保持剪切策略优化),就是来给这个死板的老师“松绑”的。
它的操作堪称神来之笔:通过stop gradient,将“裁剪”这个动作和“梯度反向传播”这两件事彻底解耦。这意味着,即便某个策略更新被“夹子”限制住了,它所包含的学习信号(梯度)依然能够回传给模型。
打个比方: 登山队(模型)在探索新路线。PPO的做法是,一旦某条路线看起来太危险,就直接剪断绳索,不让任何人过去。而GPPO则是,依然拉住绳索,但告诉队员:“这条路你们悠着点走,我们先看看情况,经验要带回来。”
这样一来,那些宝贵的探索信号和从错误中学习的信号都被保留了下来,模型既能大胆探索,又能高效修正,训练效率自然水涨船高。
训练的“炼金术”:不只靠算法
如果说GPPO是Klear-Reasoner的引擎,那它精细化的训练策略就是让这台引擎平稳跑出极限性能的燃料和调校。
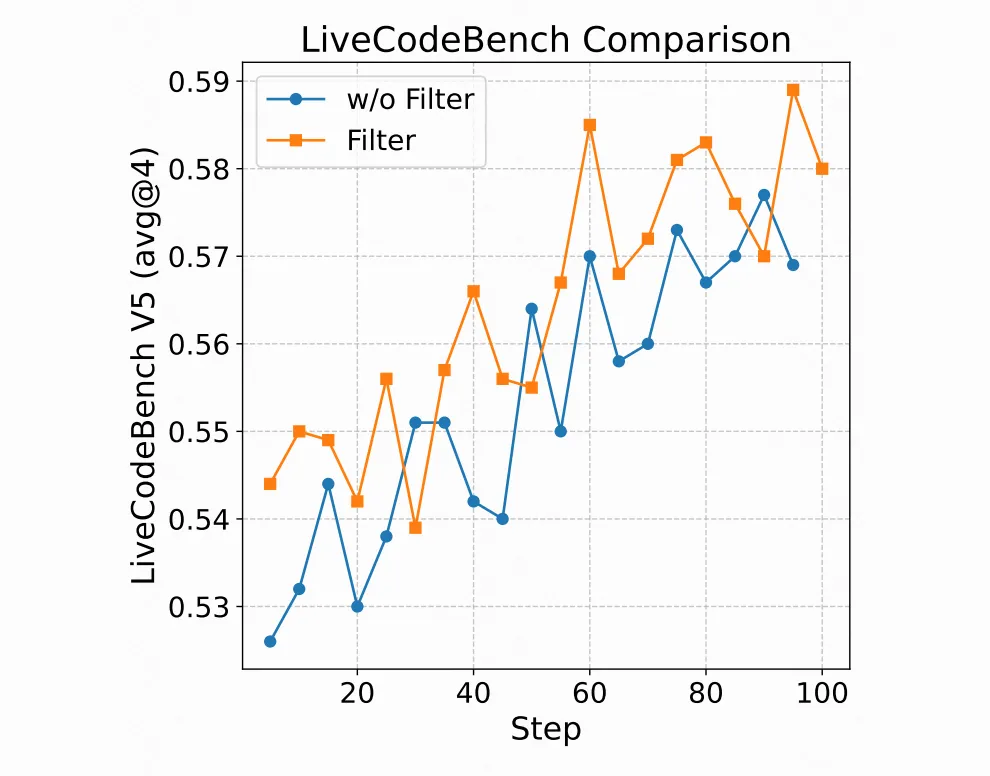
首先,是数据投喂的艺术。 团队的发现颠覆了很多人的直觉:并不是数据越多越好。他们尝试后发现,与其用十几种数据源搞个“大杂烩”,不如精选一到两个质量最高的数据源,比如OpenThoughts、NuminaMath。这再次印证了那个朴素的真理:在AI训练中,高质量的“精粮”远胜于低质量的“粗糠”。
其次,是拥抱“有益的错误”。 这一点尤其有趣。对于难题,训练数据中如果只包含完美无瑕的正确答案,模型反而学得没那么好。适当地混入一些虽然最终失败、但过程不乏闪光点的尝试,能让模型看到更多的可能性和“此路不通”的警示牌。这不就是人类学习的方式吗?
最后,是因材施教的奖励机制。 面对不同的任务,Klear-Reasoner采用了不同的“KPI”。
- 数学题:非对即错,简单直接,采用二元奖励。
- 编程题:一个功能可能只实现了一部分,但并非毫无价值。于是,团队设计了软奖励机制。比如,代码通过了16个测试用例中的4个,那就给你0.25分。这让模型在每一次部分成功中都能得到正向反馈,极大地提高了学习信号的利用率。
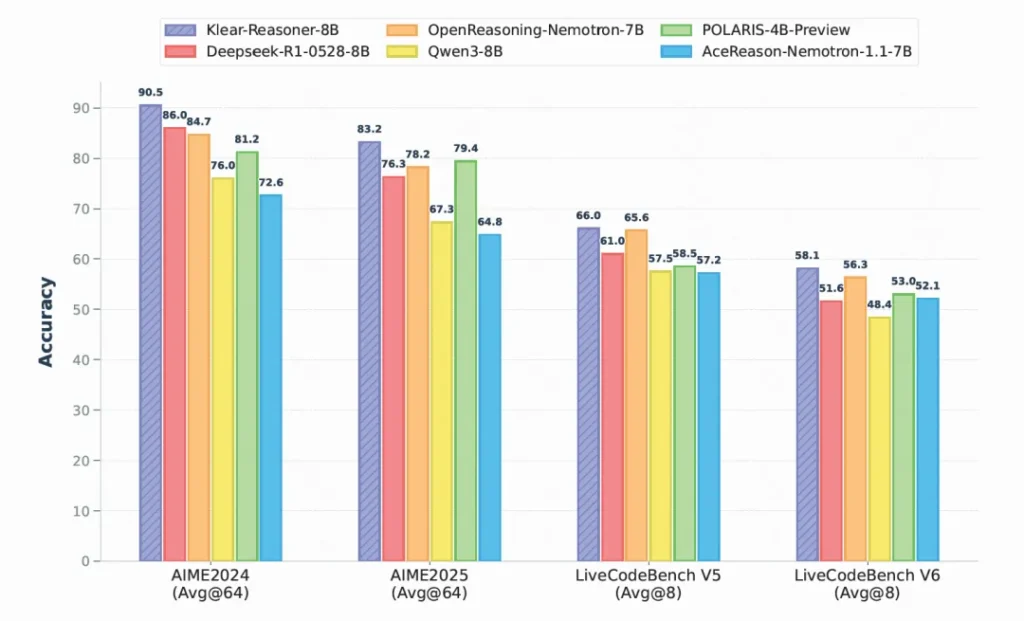
亮出肌肉:当精巧遇上硬核任务
那么,这套“GPPO引擎 + 精细化调校”的组合拳,效果究竟如何?
- 在AIME 2024数学竞赛题上,准确率达到了惊人的90.5%。
- 在LiveCodeBench V6代码推理任务上,也取得了58.1%的好成绩。
在8B这个参数级别上,这些数字足以让它傲视群雄。它证明了,通过算法和策略的深度优化,中等规模的模型完全有能力在复杂的逻辑推理任务上,达到甚至超越那些体量远大于它的对手。

最硬核的贡献:开源,毫无保留
然而,Klear-Reasoner项目最让我个人钦佩的,还不是它的性能数据,而是团队的选择:完整公开训练细节、pipeline和模型。
在这个技术壁垒高筑的时代,这种“授人以渔”的姿态弥足珍贵。它不仅仅是给社区一个强大的工具,更是提供了一套可复现、可借鉴的完整方法论。对于无数正在推理能力上苦苦挣扎的研究者和开发者来说,这无异于一份详尽的武功秘籍。
总而言之,Klear-Reasoner的故事告诉我们,模型的进化之路并非只有“暴力美学”一条。在算力与数据之外,对算法的深刻理解、对训练细节的极致打磨,同样能开辟出一条通往更高智能的优雅路径。而这,或许正是开源精神能带给这个领域最激动人心的可能性。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


