前几天,AI 圈又炸锅了!不是哪个公司又发布了炸裂的生成视频模型,而是沉寂了不久的数学证明领域,直接来了个“王炸”—— Goedel-Prover-V2。这玩意儿牛在哪儿?简单说,就是那个曾经让无数人头秃的“模型参数越大越牛”的潜规则,被它狠狠地打破了。
想象一下,一个只有 80 亿参数 的小鲜肉,硬生生地把之前号称“参数量王者”的 6710 亿参数 的大牛(DeepSeek-Prover-V2-671B)按在地上摩擦,而且摩擦得还挺服帖。这效率,我这AI圈的老司机看了都得抖三抖。
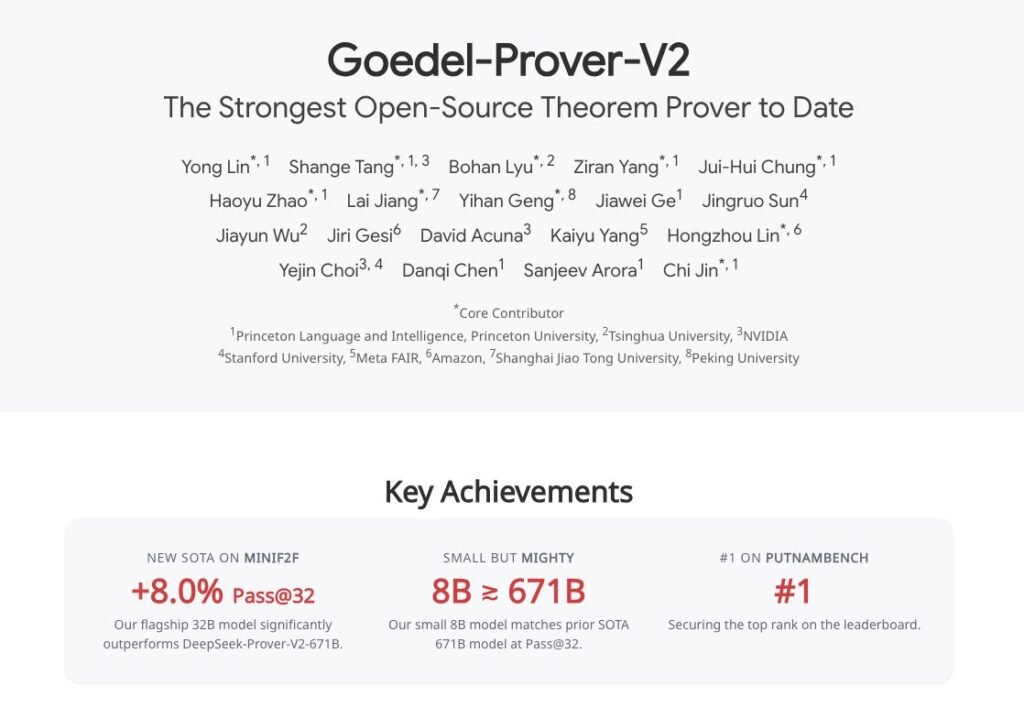
小身板,大能量:8B 模型凭啥这么“狂”?
我们先来看看这个 8B 小模型,在那个叫 miniF2F 的数学基准测试里,表现跟 671B 的大佬平起平坐,要知道,这可是相当于一个人用算盘去挑战超级计算机,结果算得一样快!这效率提升,我都懒得算,直接用“近百倍”来形容,够不够震撼?
32B 旗舰,更是“卷”出新高度!
如果说 8B 模型是“惊艳”,那 32B 的旗舰版本,那就是“封神”了。
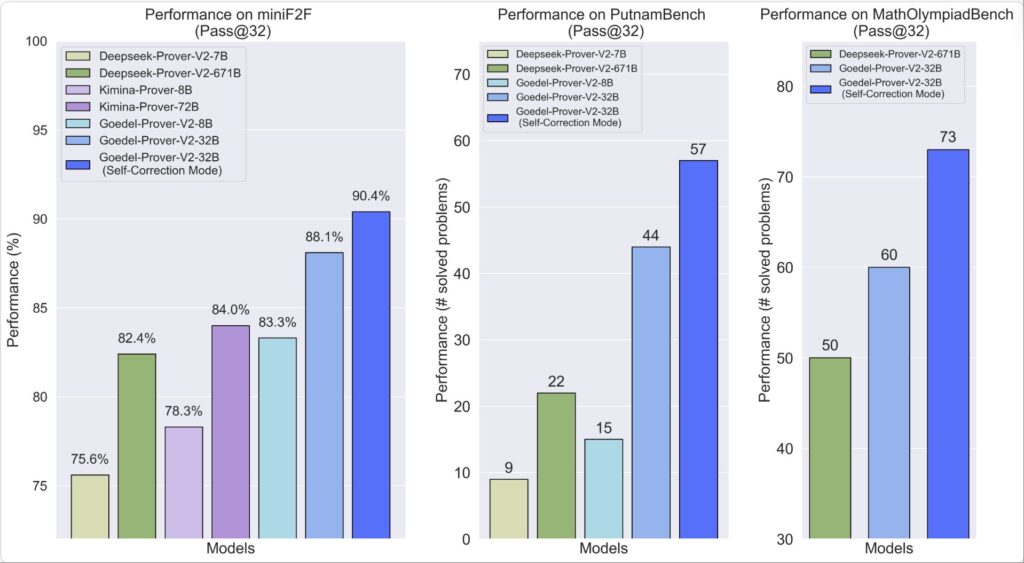
- miniF2F 咱就不说了,90.4% 的正确率(而且是在“自我修正”模式下,牛不牛?!),直接把 671B 的大佬甩在身后,8% 的差距,这在 AI 圈是天文数字。
- 再看看 PutnamBench(普特南数学竞赛),这个连人类学霸都得抓耳挠腮的赛场。Goedel-Prover-V2 的 32B 版本,人家是 Pass@64 就轻松解决了 64 道题,而那个 671B 的,得 Pass@1024 才勉强啃下 47 题。这差距,已经不是“卷”,这是“降维打击”了。
- 还有 MathOlympiadBench(数学奥赛题集),32B 版本直接拿下了 73 题,而对方只能拿出 50 题。这战绩,我只能说:格局,打开了!
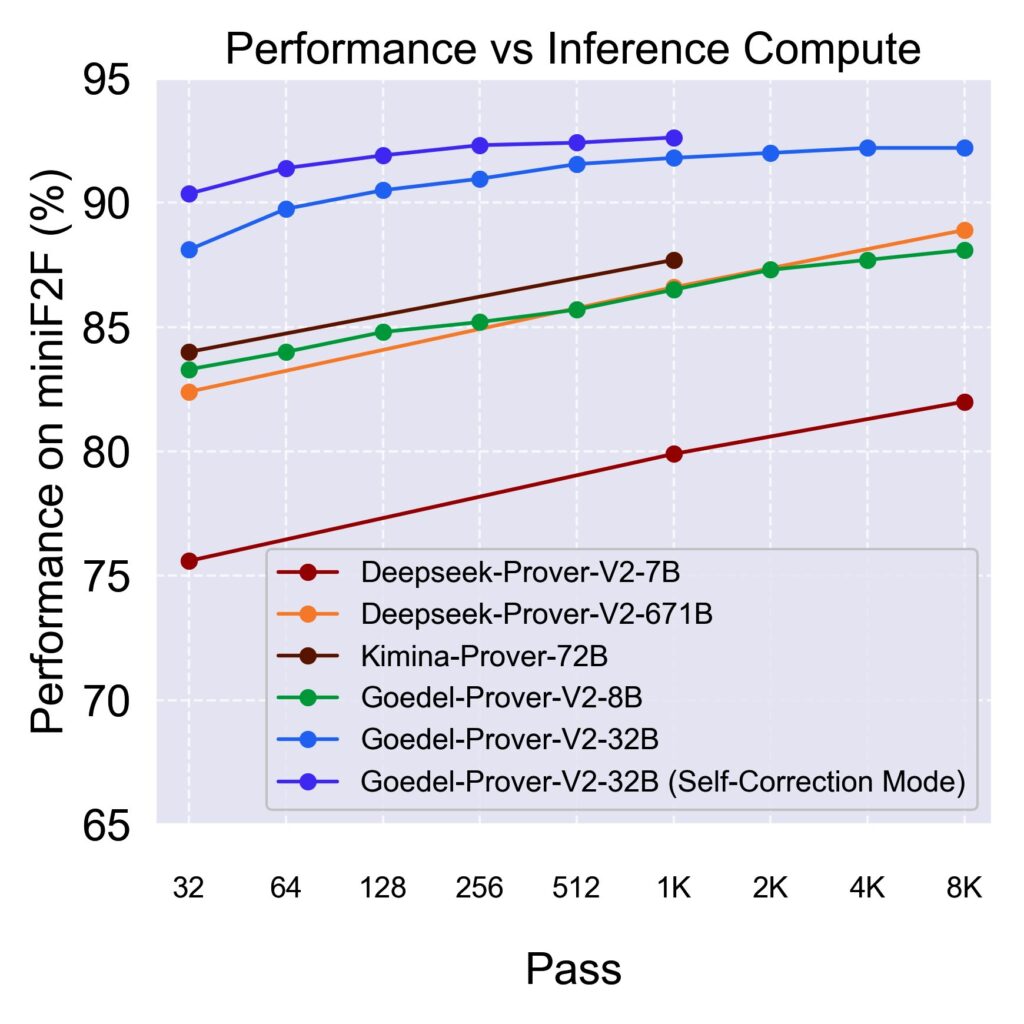
是什么让 Goedel-Prover-V2 如此“不讲武德”?
这背后,可不是什么玄学,而是实打实的技术创新。他们用了三个绝招:
- 分层式数据合成(Scaffolded Data Synthesis):就像给模型搭积木,从简单的开始,一步步来,让模型在学会“加法”后,再去挑战“微积分”。这下好了,模型学习的知识点不再是零散的,而是层层递进,泛化能力直接起飞。
- 验证器引导的自我修正(Verifier-Guided Self-Correction):这招就更骚了。模型自己写个证明,然后让 Lean 编译器来“批改作业”。发现错误?没关系,模型会自己改,就像我们写文章会反复修改一样。而且,人家改两次,就把正确率蹭蹭往上提,输出的文字量也没增加多少,简直是“优雅地变强”。
- 模型平均(Model Averaging):简单理解就是,把模型在不同训练阶段的“优秀成果”融合在一起,这样不仅能保证模型的多样性,还能让它的“抗打击能力”(鲁棒性)和“高采样性能”(Pass@K)都得到飞跃。
谁在背后搞事情?(划掉)搞研究?
这支团队也很有意思,领头的是普林斯顿大学的教授 金驰(Chi Jin),在“大模型推理”和“强化学习”领域是响当当的人物。核心成员里,还有来自清华、北大、上海交大、斯坦福的顶尖学者,甚至英伟达、亚马逊、Meta FAIR 这种大厂也来凑热闹了。而且,我发现这支队伍里的华人面孔还不少,挺有排面!
Goedel-Prover-V2 的“野心”与未来
说实话,看到 Goedel-Prover-V2 的这些表现,我脑子里蹦出好多词:颠覆、革新、未来已来。特别是那个 8B 模型,能在参数量上实现“以少胜多”,这给整个 AI 领域都指明了一个新的方向——高效推理,而不是一味地堆砌参数。
未来,我们可以期待它在数学研究、教育、甚至软件和硬件的验证领域大显身手。想想看,数学家们可以在它手上快速验证猜想,学生们能看到更清晰的证明过程,工程师们能更放心地验证算法逻辑……这简直就是 AI 赋能科学的理想范本。
总而言之,Goedel-Prover-V2 这位“数学证明界的新晋卷王”,用实力告诉我们,AI 的发展,总是充满惊喜。它不仅在技术上实现了效率和性能的双重突破,还以开源的方式,号召大家一起玩。

想了解更多细节?可以去他们的官网(blog.goedel-prover.com)或者即将更新的论文里一探究竟。反正我是已经搓手手期待后续更多精彩了!
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论