哈喽各位 AI 圈的老铁们,最近有个消息简直炸裂!我们的“牙膏厂”苹果,竟然也悄悄地在端侧 AI 领域扔下了一颗重磅炸弹——FastVLM!
这可不是什么云里雾里的概念,而是个实打实、能直接在我们手里的 iPhone、iPad、Mac 上跑起来的视觉语言模型(VLM)。而且,它的名字里带着个大写的“Fast”,那速度,真的是快到让你惊掉下巴!
FastVLM 是啥?简单来说,它让你的设备有了“眼睛”和“嘴巴”
想象一下,你拍了张照片,或者屏幕上有一张图,你想问它点啥,或者让它描述一下。传统的路子,可能得把图传到云端服务器,那里有强大但遥远的 AI 模型处理,再把结果传回来。这中间嘛,有延迟、有隐私问题,还可能得联网。
苹果 FastVLM 就不一样了。它的核心工作流程非常直接且高效:
- 先看懂图(图像 → token): 它用一套特别厉害的技术(后面会讲)飞快地把图像“消化”一遍,然后转化成一堆它能理解的、高度浓缩的信息块,我们叫它“视觉 token”。你可以理解成是给图片做的“速记笔记”。
- 再生成话(token → 语言): 拿到这些“笔记”后,它再交给设备上的语言模型,语言模型根据这些笔记和你的问题,嗖嗖嗖地生成回答或描述。
整个过程,全程在你的设备本地完成!不上传云端,又快又安全。
为啥叫“FastVLM”?因为它的首 token 输出快到离谱!
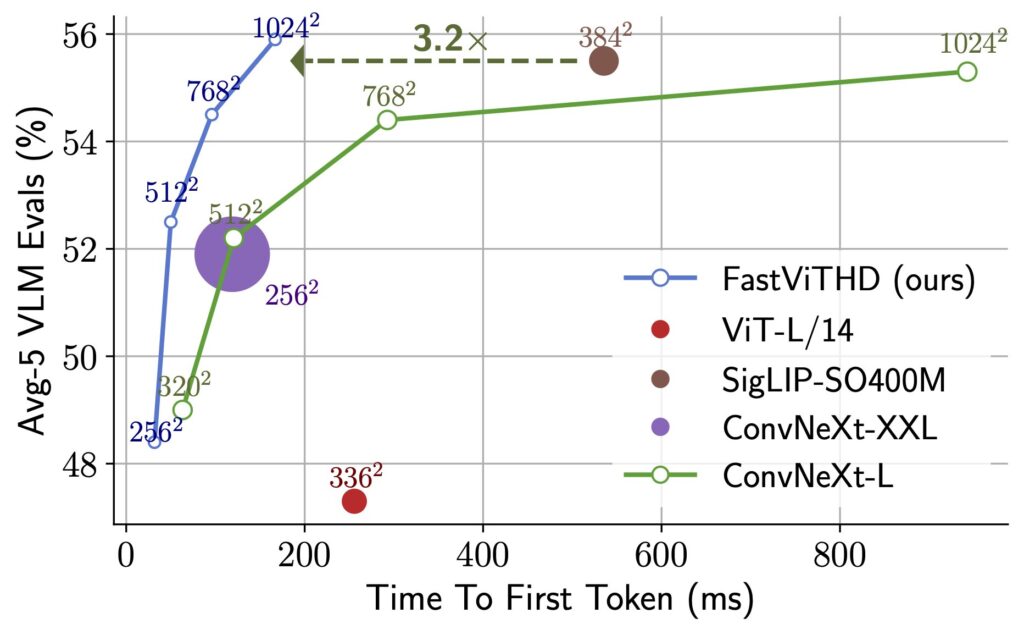
这绝对是 FastVLM 最亮眼的招牌!苹果在性能对比中放出的数据,简直让人难以置信:
- 对比同等规模的LLaVA-OneVision-0.5B模型,FastVLM-0.5B 的首个 token 输出速度竟然快了整整 85 倍! 85 倍啊!这是什么概念?就是你问它问题,它几乎能瞬间给出第一个字的反应,后续文字也源源不断跟上。这对于实时交互体验来说,简直是革命性的。
- 即使是更大的 FastVLM-7B 模型(基于强大的 Qwen2-7B 语言模型),对比同类模型 Cambrian-1-8B,首 token 速度也快了 7.9 倍。
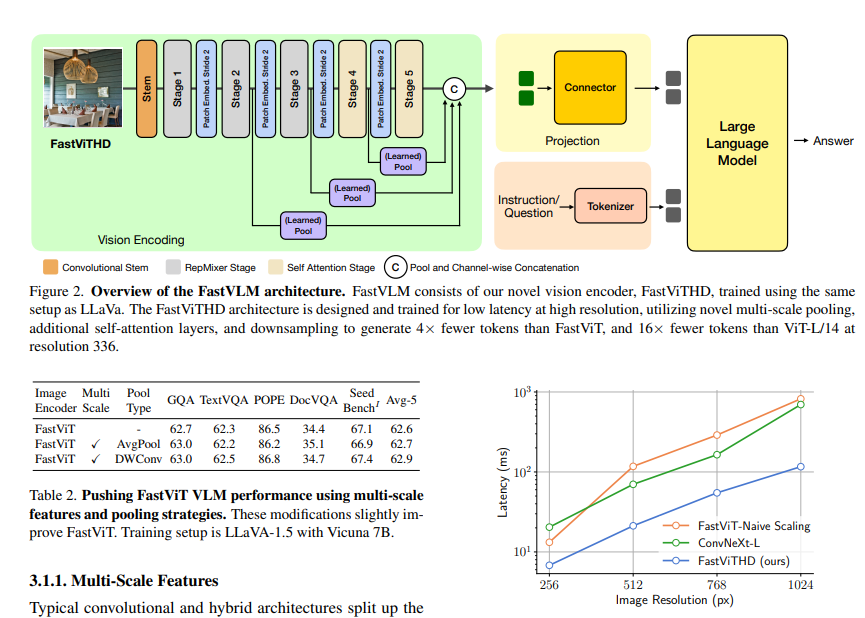
为什么能这么快?秘密藏在它全新的视觉编码器 FastViTHD 里。传统的模型处理图像,尤其是高分辨率图像时,生成的视觉 token 数量巨大,给后续的语言模型造成很大负担。FastViTHD 就聪明多了,它能在保证不丢失关键信息的前提下,生成数量更少但信息更丰富的视觉 token(比如从1536个压缩到576个),大大减轻了语言模型的计算压力。而且,这个编码器本身也非常高效,体积比之前的小了 3.4 倍!
更厉害的是,它是针对苹果自己的 A18、M2 等芯片做了深度优化,支持 FP16 和 INT8 量化,能最大限度地利用苹果硬件的算力,同时还省电(据说连续运行功耗相当于看视频的水平)。
小巧玲珑,轻松跑在你的 iPhone 上
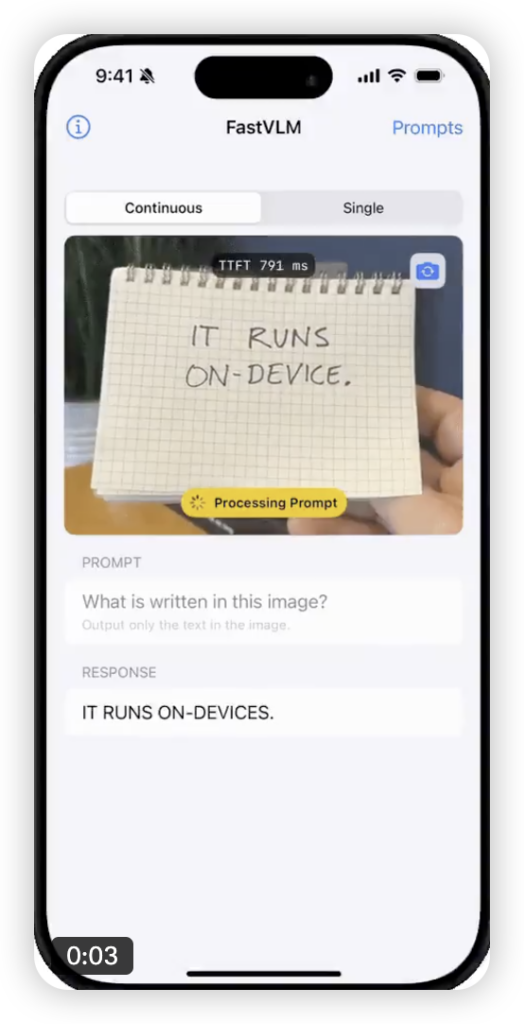
除了快,FastVLM 的另一个核心优势就是小!它被设计得非常紧凑,配合苹果的 MLX 框架和 CoreML 工具链,可以非常轻松地部署在 iPhone、iPad、Mac 上。
这意味着,未来的 iPhone 不仅性能强劲,还能直接在本地完成复杂的视觉理解和语言交互任务。无论是实时 AR 应用中的环境理解,还是辅助功能里的图像描述,亦或是更智能的照片搜索和编辑,都能获得前所未有的流畅体验。想象一下在 iPad Pro M2 上实现 60FPS 的连续对话体验,是不是已经心动了?
而且,本地运行带来的隐私保护也是云端方案无法比拟的。你的照片和数据,就安全地待在你的设备里。
不止是“看图说话”,它还能干啥?
别以为 FastVLM 只能简单地描述图片。它是一个真正的视觉语言模型,能力覆盖很广:
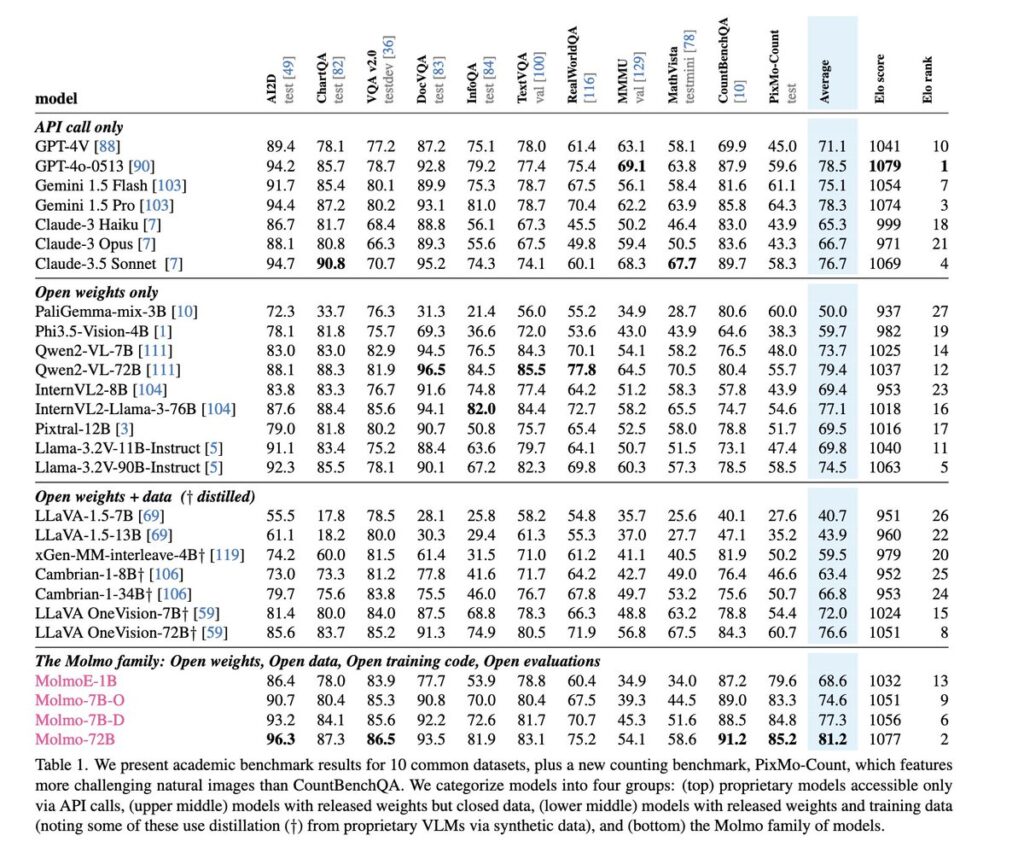
- 实时问答: 针对图片内容回答各种问题。
- 文档解析: 阅读图片中的复杂文档或表格(在 DocVQA 任务上性能提升显著)。
- 文字识别与理解: 识别图片中的文字,并理解其含义(TextVQA 任务表现出色)。
- 更高级的推理: 在多模态理解任务(如 MMMU、SeedBench)上也能保持出色性能。
更具体的应用场景,就像源信息里提到的:医疗影像辅助分析(肺结节检测准确率达 93.7%),工业质检(智能手机生产线缺陷检测误报率大幅降低),甚至未来集成到 Xcode 帮助写代码,或者让 Messages 应用里的表情包更智能,都充满了想象空间!

开源!苹果正在构建自己的 AI 生态
值得一提的是,苹果这次非常开放,FastVLM 的代码和模型已经在 GitHub 和 Hugging Face 上开源了!这基于 LLaVA 代码库训练,并提供了详细的指南。
这意味着开发者可以基于 FastVLM 在苹果设备上构建各种各样的 AI 应用,充分利用苹果强大的硬件能力和苹果提供的开发工具。这无疑会极大地推动苹果生态内 AI 应用的创新和普及。
总结:移动端 AI 的新里程碑
FastVLM 的发布,不只是苹果秀肌肉那么简单,它真正地重新定义了移动设备上多模态 AI 的可能性边界。
通过极速的视觉编码(FastViTHD)、对苹果硬件的深度协同优化、小巧的模型体积以及开放的开源策略,苹果不仅解决了端侧部署的“慢”和“大”的痛点,还为用户提供了更流畅、更私密、更强大的 AI 体验。
它证明了在消费级设备上实现高性能的实时视觉语言交互是可行的,并且已经成为现实。FastVLM 有望成为未来苹果设备上诸多智能化功能的基石,让我们的 iPhone、iPad 不再只是工具,而是更加智能、更能理解我们世界的伙伴。
对于我们 AI 圈的开发者来说,这无疑是一个令人兴奋的消息。苹果已经搭好了舞台,提供了利器,接下来就看大家能用 FastVLM 创造出什么精彩的应用了!
你对 FastVLM 有什么看法?或者已经跃跃欲试想玩玩开源模型了?欢迎在评论区交流!
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论