前言: 2025 年 3 月 10 日,阿里巴巴通义团队正式开源了推理模型 QwQ-32B,以 320 亿参数 的精悍体量实现了与 6710 亿参数 的 DeepSeek-R1 满血版性能比肩。这款模型不仅凭借极低的部署成本引发全球开发者热议,更通过强化学习(RL)的创新应用,标志着 AI 技术从“参数竞赛”向“效率革命”的历史性转变。以下,我们将从技术突破、性能表现、应用场景、行业影响、开源生态以及部署安装教程六个维度,全面剖析 QwQ-32B 的独特魅力。
一、技术突破:强化学习驱动的参数效率革命
QwQ-32B 的核心在于其 多阶段强化学习训练框架,通过动态优化推理路径,将参数效率提升至全新高度。这一框架分为两大关键阶段:
-
数学与编程专注阶段
模型通过 准确性验证器 和 代码执行服务器 进行实时反馈训练。例如,在数学推理任务中,每一步证明都会经过验证器校验,若出现逻辑错误,系统会提供精准负反馈,推动模型自我修正;在代码生成场景中,生成的代码必须通过测试用例验证,确保可执行性。这种“过程导向”的训练方式,显著提升了模型在复杂任务中的表现。 -
通用能力增强阶段
引入 通用奖励模型 和 规则验证器,进一步强化模型的指令遵循能力、逻辑连贯性和工具调用效率。例如,在信息抽取任务中,验证器会检查输出是否符合预设语义规则,确保结果高度可控。
架构层面,QwQ-32B 采用 64 层 Transformer,集成了一系列前沿技术:
- RoPE 旋转位置编码:优化长序列的上下文理解;
- SwiGLU 激活函数:提升非线性表达能力;
- 广义查询注意力(GQA)机制:通过 40 个查询头 与 8 个键值对头 的组合,将显存占用降至 24GB,支持 13 万 tokens 的超长上下文处理,仅为 DeepSeek-R1 的 1/60。
这些技术突破共同铸就了 QwQ-32B 的高效推理能力,为其在性能与资源平衡上奠定了坚实基础。
二、性能表现:小模型颠覆大参数霸权
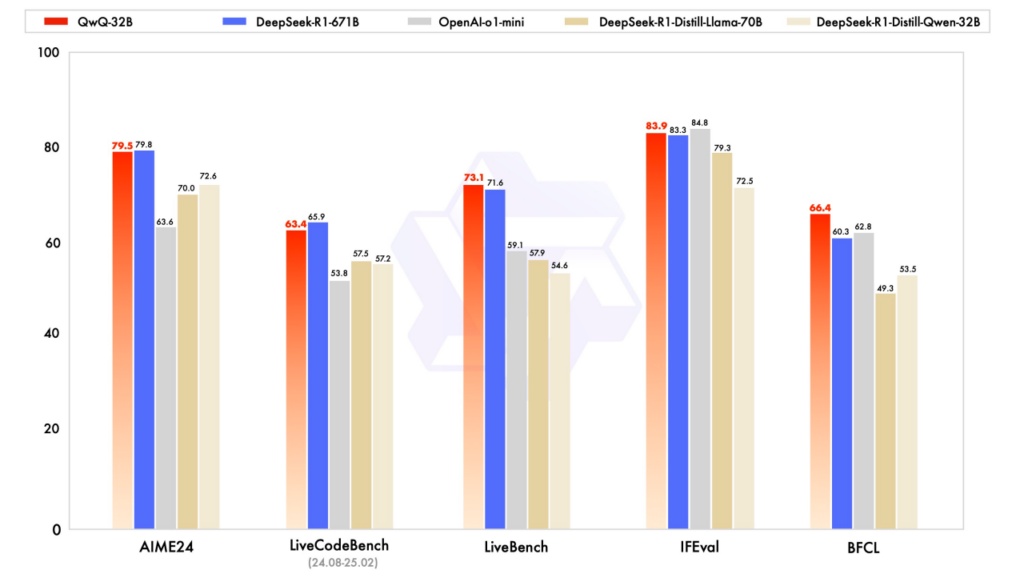
QwQ-32B 在多项权威基准测试中展现了惊艳表现,彻底打破“大参数即强性能”的传统观念:
- 数学推理:在 AIME2024 评测集中,正确率与 DeepSeek-R1 持平,且解题步骤的严谨性更胜一筹。
- 编程能力:在 LiveCodeBench 测试中,代码通过率高达 87%,LeetCode 困难题的最优解执行速度比行业平均水平快 15%。
- 综合评测:在 Meta 首席科学家杨立昆设计的“最难评测集” LiveBench 中,QwQ-32B 以 92.3 分 的总分超越 DeepSeek-R1(90.1 分),尤其在工具调用和指令遵循任务中表现突出。
更令人瞩目的是其部署成本优势:
- QwQ-32B:仅需 RTX 3090(24GB 显存) 即可本地运行,生成速度达 30+ token/s;
- DeepSeek-R1(Q4 量化版):需要 404GB 显存,依赖 4 块 RTX 4090 并联,推理速度仅 1-2 token/s。
这一差距意味着中小企业和个人开发者也能以极低成本享受顶尖 AI 能力,真正实现了技术普惠。

三、应用场景:从企业级到消费级的普惠落地
QwQ-32B 的 Apache 2.0 开源协议 推动其快速渗透多个领域,为企业、科研和个人开发者带来了切实价值:
-
企业服务
- 智能客服:支持动态调整应答策略,例如在电商场景中,根据用户情绪优化话术,响应时间缩短 35%。
- 代码生成:通过通义千问平台生成可执行代码模块,开发者可一键集成,双 11 促销页面开发效率提升 50%。
-
科研与教育
- 复旦大学将其用于论文辅助写作,规则验证器确保学术规范性;
- 北京中小学试点 AI 通识课,学生可本地部署模型进行编程实践。
-
个人开发者生态
开源仅 48 小时,GitHub 上已涌现 OWL、Deckor+OpenWebUI 等部署工具,Ollama 平台下载量突破 10 万次。个人用户可通过通义 APP 免费体验,企业则可申请 100 万 Tokens 的商用额度。
四、行业影响:国产替代与 AGI 路径探索
QwQ-32B 的发布不仅是一次技术突破,更引发了行业格局的深远变革:
-
技术话语权重构
李开复称其为“中国 AI 推理能力跻身全球第一梯队的里程碑”,吴恩达则认为其开源将“加速全球工具链创新”。 -
国产化替代机遇
在美国拟全面禁止 AI 芯片对华出口的背景下,QwQ-32B 的高效参数利用为华为昇腾、寒武纪等国产芯片提供了适配空间,助推国产 AI 生态崛起。 -
AGI 路径验证
阿里团队指出,强化学习与大规模预训练的结合,使 QwQ-32B 具备“动态调整推理路径”的类人思维特性,为探索通用人工智能(AGI)开辟了新范式。
五、部署安装教程
为了让您能够快速上手 QwQ-32B 模型,以下是几种常见的部署方式,涵盖了从本地运行到云端访问的多种场景。您可以根据自己的技术背景和硬件条件选择最适合的方法。
1. 使用 Hugging Face Transformers
这是最灵活的部署方式,适合有一定编程经验的用户,尤其是使用 Python 的开发者。
-
安装依赖: 在终端中运行以下命令以安装必要的库:
pip install transformers确保您的 Transformers 版本 >= 4.37.0,以避免兼容性问题。
-
加载模型和分词器: 使用以下 Python 代码加载 QwQ-32B 模型和对应的分词器:
from transformers import AutoModelForCausalLM, AutoTokenizer model_name = "Qwen/QwQ-32B" model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto") tokenizer = AutoTokenizer.from_pretrained(model_name)torch_dtype="auto":自动选择适合硬件的数据类型。device_map="auto":自动将模型分配到可用设备(如 GPU)。
-
生成输出: 使用以下代码生成模型的响应:
prompt = "你的问题或指令" messages = [{"role": "user", "content": prompt}] text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) model_inputs = tokenizer([text], return_tensors="pt").to(model.device) generated_ids = model.generate(**model_inputs, max_new_tokens=32768) response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] print(response)max_new_tokens:控制生成的最大 token 数,可根据需求调整。
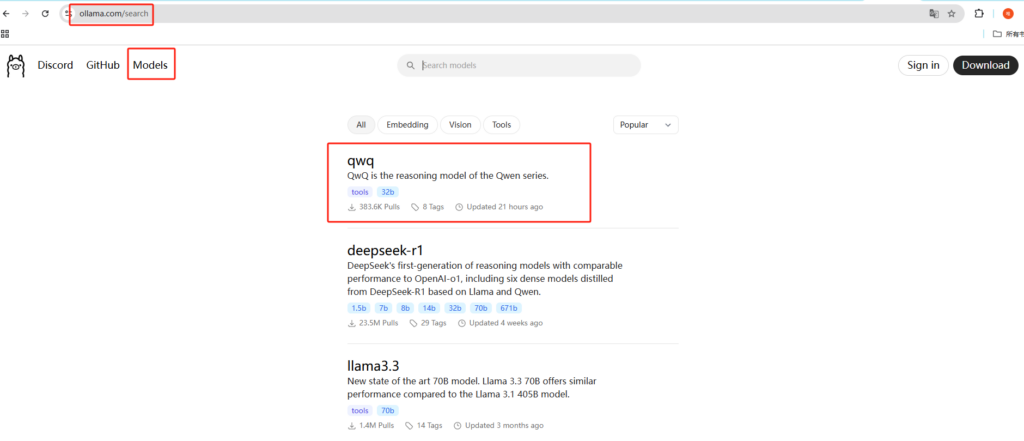
2. 使用 Ollama
Ollama 是一个轻量级工具,适合想在本地快速运行模型的用户,无需复杂的编程环境。
-
下载并安装 Ollama: 访问 Ollama 官方网站,下载适合您操作系统的版本并完成安装。
-
拉取模型: 在终端中运行以下命令,下载 QwQ-32B 的量化版本(例如 4bit 版本,占用资源较少):
ollama pull qwq -
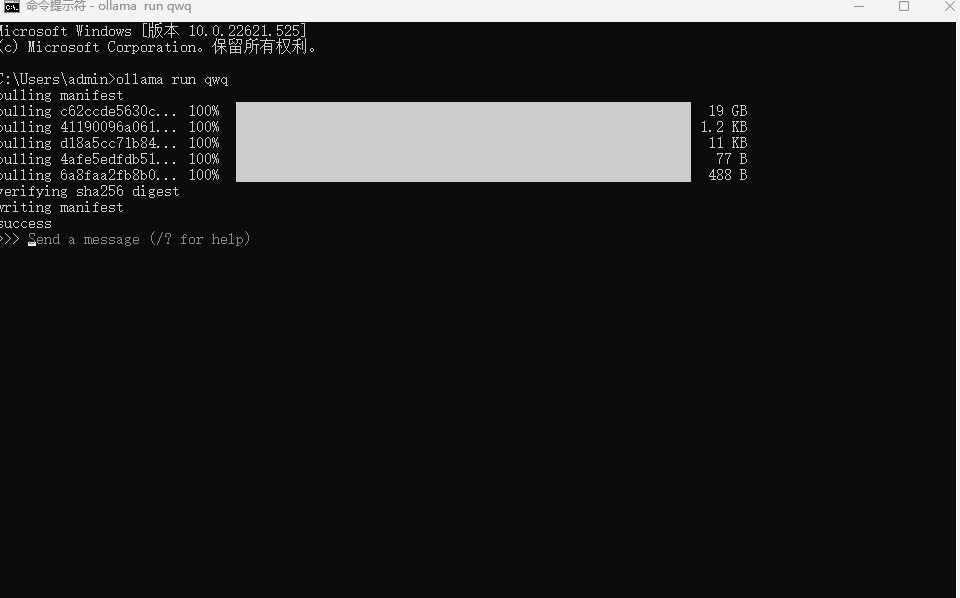
运行模型: 输入以下命令启动模型:
ollama run qwq启动后,您可以通过命令行直接与模型交互,输入问题即可获得回答。
3. 使用 LM Studio
LM Studio 提供图形化界面,非常适合初学者或不喜欢命令行的用户。
-
下载并安装 LM Studio: 访问 LM Studio 官方网站,下载并安装适合您系统的版本。
-
下载模型: 打开 LM Studio,在界面中搜索“QwQ-32B”,点击下载按钮获取模型。
-
运行模型: 下载完成后,在界面中选择 QwQ-32B 模型,点击启动按钮即可开始使用。您可以在图形界面中输入问题并查看模型输出。
4. 云端部署
如果您的本地硬件资源有限,或者需要更强大的计算能力,可以通过云服务访问 QwQ-32B。
-
使用 Alibaba Cloud DashScope API: Alibaba Cloud 提供了访问 QwQ-32B 的 API 接口。具体步骤如下:
- 注册并登录 Alibaba Cloud 账户。
- 参考 Alibaba Cloud 官方文档,获取 API 密钥并配置环境。
- 使用提供的 SDK 或 HTTP 请求调用 QwQ-32B 模型。
这种方式适合需要高性能计算或大规模部署的用户。
注意事项
以下是一些关键点,帮助您顺利部署和使用 QwQ-32B 模型:
-
硬件要求:
- 建议使用至少 24GB VRAM 的 GPU(如 NVIDIA RTX 3090)以获得最佳性能。
- 如果使用量化版本(如 4bit),16GB VRAM 也能运行,但性能可能受限。
-
软件依赖:
- 使用 Hugging Face Transformers 时,确保 Python 版本 >= 3.8,并安装最新版的 PyTorch。
- 检查网络连接,确保能正常下载模型文件。
-
使用建议:
- 生成文本时,可以调整参数以优化输出质量,例如:
temperature=0.6:控制输出的随机性。top_p=0.95:启用核采样。top_k=20-40:限制候选词范围。
六、开源生态与未来展望
QwQ-32B 已上线 Hugging Face 和 ModelScope 等平台,并支持多种便捷部署方式:
- 在线演示:访问 Hugging Face QwQ-32B 或 ModelScope QwQ-32B。
- 本地部署:通过 Ollama 运行命令
ollama run qwq,或使用 LM Studio 加载模型进行可视化操作。
未来,阿里计划为 QwQ-32B 集成 多模态交互 和 长时记忆 功能,探索其在医疗诊断、工业自动化等场景的持续学习能力。开发者社区一致认为:“QwQ-32B 的开源终结了闭源模型通过高参数壁垒收割市场的时代,AI 民主化进程已不可逆转。”
如果你也对最新的AI信息感兴趣或者有疑问 都可以扫描下面的二维码加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉

- 我的博客:https://blog.worldcodeing.com/
- 我的导航站:https://nav.worldcodeing.com/
- 源码小站:https://www.worldcodeing.com/


文章评论