如果你关注大模型领域的最新动态,应该注意到了2026年1月8日的一个重磅消息:阿里通义千问团队把他们的“看家本领”拿出来了。
这次开源的不是又一个单纯聊天的Chatbot,而是一套专门解决“多模态检索”难题的工具链——Qwen3-VL-Embedding 和 Qwen3-VL-Reranker。
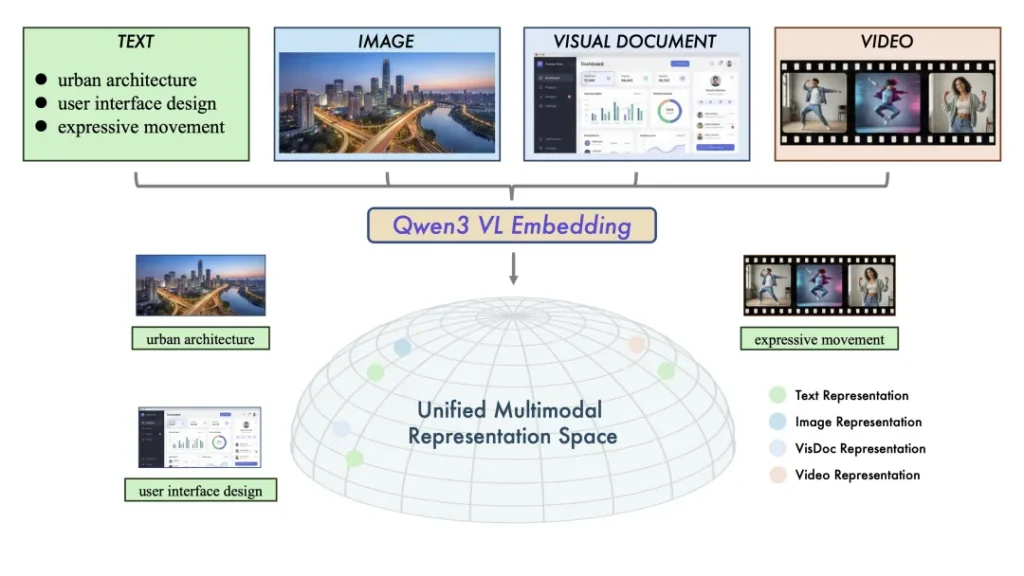
简单说,这套模型是基于强大的Qwen3-VL底座打造的,它们解决了一个让开发者头疼已久的问题:在这个图文、视频爆炸的年代,我们该如何像搜索文字一样,精准地搜索视频片段、复杂图表和截屏?
为什么需要这套“双子星”?
在过去的一年里,RAG(检索增强生成)几乎成了企业级应用的标配。但痛点在于,传统的RAG大多是“瞎子”,只能处理纯文本。一旦文档里夹杂了流程图、或者知识库里堆满了视频素材,传统模型就歇菜了。
通义团队这次打出的组合拳,正是为了填补这个空白。
这套系统由两个核心角色组成,配合起来就像是一个经验丰富的“图书管理员”:
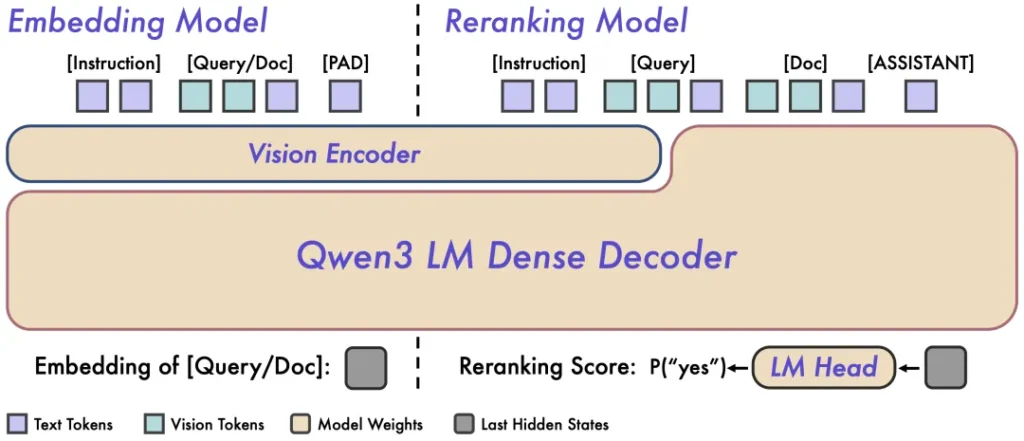
第一步:Qwen3-VL-Embedding(负责“广撒网”) 这是检索的第一道关卡。它的任务是把所有的素材——无论是PDF里的文字、PPT里的架构图,还是长视频里的某一帧,统统“翻译”成统一的数学向量。 这打破了模态之间的“生殖隔离”。有了它,你不仅可以用文字搜图,还能用图搜视频。而且,它支持所谓的“Matryoshka”套娃式表示学习,这意味着你可以在推理时灵活截断向量维度,在精度和速度之间自由切换,不用重新训练模型。
第二步:Qwen3-VL-Reranker(负责“精挑选”) Embedding虽然快,但有时候不够精准。这时候就需要Reranker登场了。 不同于市面上常见的双塔结构,这个Reranker会把用户的查询和Embedding捞回来的候选内容放在一起进行“深度阅读”。它会通过交叉注意力机制,仔细比对查询意图和素材细节的匹配度,然后重新排座次。官方数据显示,这个精排步骤能显著提升最终结果的准确性。

看起来很强,用起来重吗?
这可能是开发者最关心的问题。好消息是,这套模型非常“亲民”。
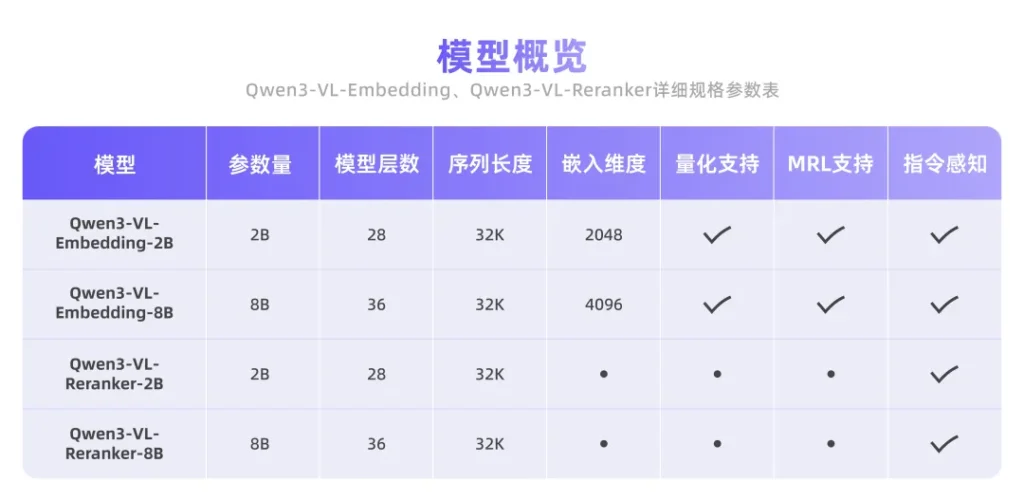
Qwen3-VL-Embedding 提供了 2B 和 8B 两个版本。 Qwen3-VL-Reranker 目前开源了 2B 版本。
对于大多数商业应用或个人开发者来说,2B和8B的参数量意味着你不需要拥有显卡集群,就能在本地或中型服务器上跑起来。同时,它们原生支持32K的上下文长度,处理长文档或长视频片段绰绰有余。
硬实力的证明
在技术圈,不服跑个分。
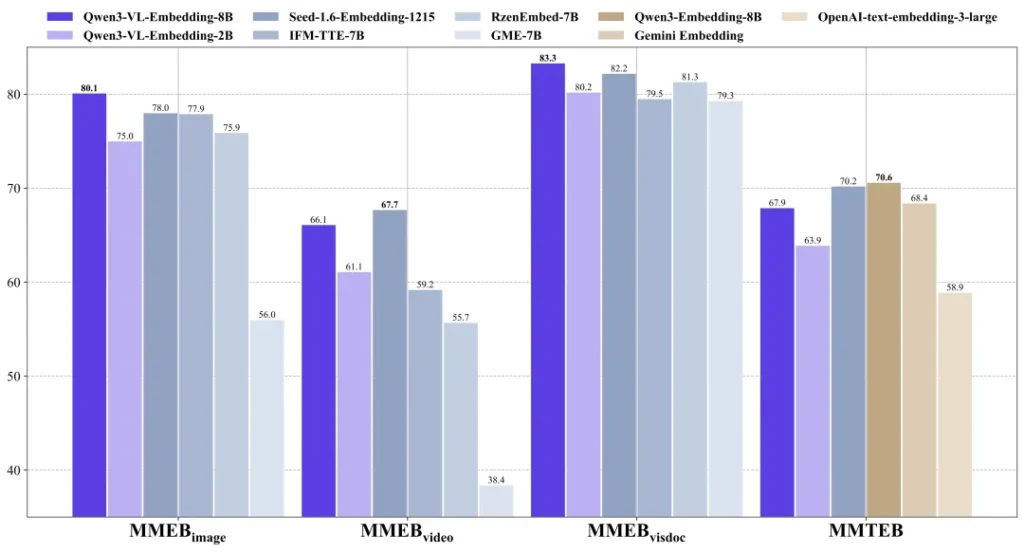
根据官方和第三方的测试数据(如MMEB-V2、MMTEB基准),Qwen3-VL-Embedding的8B版本在多模态检索任务上,性能直接超越了目前市面上已知的开源模型,甚至把一些闭源商业服务甩在了身后。
特别是对于那些复杂的视觉文档——比如包含代码截图的教程、充满UI组件的设计稿,这套模型的理解能力展现出了SOTA(当前最佳)的水准。
总结
通义千问这次的开源动作,实际上是把多模态RAG的门槛给踏平了。
无论你是想做一个能看懂设计图的企业知识库,还是想搭建一个能搜到“主角穿红衣服那个镜头”的视频搜索引擎,Qwen3-VL的这套Embedding和Reranker组合,都是目前开源界最值得尝试的基石。
目前,模型权重已经全部托管在Hugging Face和ModelScope上,遵循Apache 2.0协议。也就是说,哪怕你是拿去商用,也是完全免费且合规的。
对于正在构建下一代AI应用的开发者来说,这绝对是2026年开年的一份大礼。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


