还记得那些让人惊叹的AI生成视频吗?它们画面精美、创意无限,却常常带着一丝遗憾——有画无声,或是配乐生硬。这就像看一部默片,总觉得少了点灵魂。如今,腾讯混元团队给出了答案,他们开源的端到端视频音效生成模型 HunyuanVideo-Foley,正在悄然改变这一切,让AI视频真正拥有了“电影级的耳朵”。
作为一名AI圈的观察者,我一直期待能有一种技术,彻底解决AI内容“视听分离”的痛点。HunyuanVideo-Foley的出现,无疑是这个领域的一个里程碑。

一、告别“默片时代”:HunyuanVideo-Foley 的声音魔法
想象一下,你上传一段无声的视频,再配上一句简单的文字描述,比如“引擎轰鸣,汽车加速”,或者“小狐狸踩踏树叶的沙沙声”。几秒钟后,视频便被赋予了生命:引擎从怠速到轰鸣的动态变化,轮胎摩擦湿地的质感,小狐狸踏过枯叶的细微声响,丝丝入扣,栩栩如生。这,就是 HunyuanVideo-Foley 带来的改变。
它不仅仅是简单地添加声音,而是在进行一场复杂的“声音创作”:
- 智能听懂: 它能同时理解视频画面中的内容(是海浪,还是人群?)和你的文字指令(你想要“海浪声”,但它还会智能补充海鸥鸣叫和人群喧哗)。这种多模态语义的均衡响应,让生成的音效层次丰富、真实自然。
- 专业级保真: 模型输出的音频能达到 48kHz 采样率,有效抑制底噪和杂音,确保了电影级别的声音质感。无论是风吹草动的轻柔,还是金属碰撞的铿锵,都能精准呈现。
- 泛化能力惊人: 无论是人物、动物、自然风光,甚至是卡通动画或科幻场景,HunyuanVideo-Foley 都能轻松驾驭,生成与画面语义高度对齐的音效。
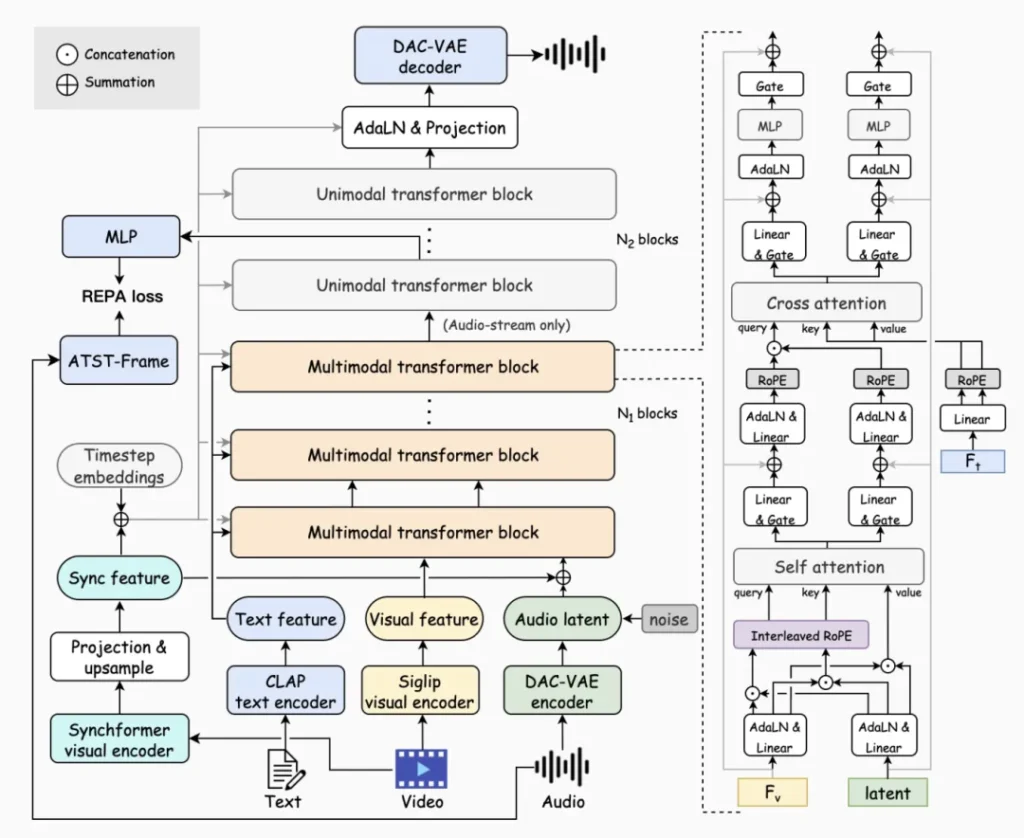
二、声音魔法的底气:技术突破揭秘
这背后究竟蕴藏着怎样的“黑科技”?HunyuanVideo-Foley 的核心创新主要集中在以下几个方面:
- 双流多模态扩散变换器 (MMDiT): 这听起来拗口,但你可以把它想象成模型拥有两只“眼睛”和一只“耳朵”。它通过一套精密的联合自注意力机制,让视频画面和音频帧级信息实现同步;再通过交叉注意力机制,把文字描述的语义精准注入,避免了过去模型可能“顾此失彼”的问题。
- 庞大的“知识库”: 腾讯混元团队构建了约10万小时级的文本-视频-音频(TV2A)数据集。这些海量、高质量的真实世界数据,经过自动化标注和严格过滤,为模型提供了源源不断的“学习养料”,使其具备了出色的泛化能力。
- 表征对齐(REPA)损失函数: 这好比给模型的音频生成过程配备了一位“声学导师”。通过利用预训练的音频特征进行指导,它能显著提升音频生成的质量和稳定性,确保声音不仅“像”,而且“真”。
- 增强的音频 VAE: 模型采用了优化的变分自编码器,将离散的音频信号转换为连续的128维表示,进一步提升了音频的重建能力和细节表现。
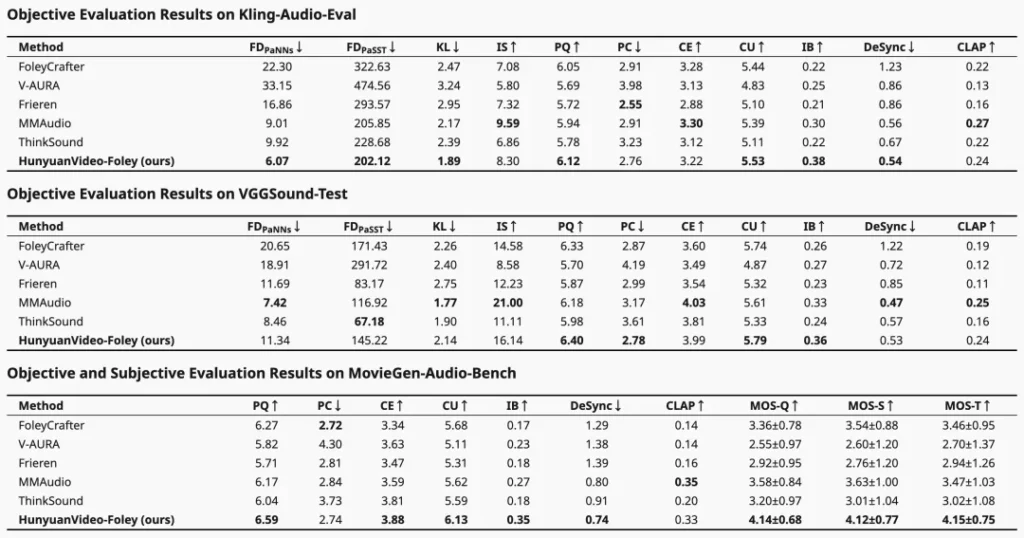
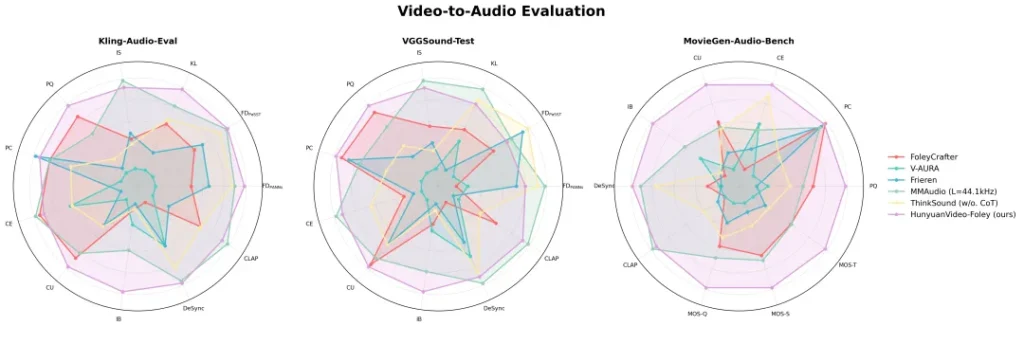
三、硬核数据,刷新行业天花板
在权威评测基准 MovieGen-Audio-Bench 上,HunyuanVideo-Foley 的表现可谓一鸣惊人,全面超越了现有开源方案,达到了 SOTA(State-of-the-Art) 水平。
- 音频质量(PQ):从 6.17 跃升至 6.59。
- 视觉语义对齐(IB):从 0.27 大幅提升至 0.35。
- 时序对齐(DeSync):从 0.80 优化至 0.74(数值越低越好)。
更重要的是,在主观评测中,模型在音频质量、语义对齐和时间对齐三个维度的平均意见得分(MOS)均超过 4.1分(满分5分),这已然逼近专业音频工程师的水准。
四、声音触手可及:如何体验与使用
腾讯混元团队的慷慨开源,让这项前沿技术不再是实验室里的“秘密武器”。
- 在线体验: 最直接的方式就是访问腾讯混元官网的体验入口。上传你的视频和文字描述,几秒钟就能感受这份惊喜。
- 代码与模型下载: 对于开发者和研究人员,项目代码、预训练模型以及详细的技术文档都已在 GitHub 和 Hugging Face 上公开。这意味着你可以轻松地在本地部署和二次开发。
这项技术的应用场景也异常广阔:
- 短视频创作: 让你的 UGC 内容瞬间拥有电影质感,告别干巴巴的画面。
- 影视后期: 辅助拟音师进行环境音、特效音的快速生成,大幅降低制作成本和周期。
- 游戏开发: 为游戏场景和角色动作实时生成沉浸式音效,增强玩家的代入感。
- 在线教育: 为教学视频增添生动音效,提升学生的学习兴趣和专注力。
五、不止于 Foley:混元视频生成生态的宏大愿景
值得一提的是,HunyuanVideo-Foley 并非孤军奋战。它与去年底(2024年12月3日)开源的 HunyuanVideo 文生视频模型,以及今年3月6日开源的 HunyuanVideo-I2V 图生视频模型,共同构成了腾讯混元在AI视频生成领域的完整生态。当视频生成不再是“无声电影”,当图生视频可以自动配乐,我们看到的是一个真正视听一体、多模态融合的AI创作新时代正在加速到来。

六、一些思考与提醒
HunyuanVideo-Foley 的开源,无疑为广大创作者和开发者提供了一个强大的工具,它将极大地降低高质量音效制作的门槛,激发更多富有创意的多媒体内容诞生。
但作为开源模型,也需要留意其许可协议(Hugging Face 标注为 tencent-hunyuan-community 许可),在使用和商业化过程中,务必仔细阅读并遵守相关条款。同时,任何AI生成内容,都需要人类的审慎判断和负责任的使用。
我们正在见证AI技术如何一点点填补创意的空白,将过去的“不可能”变为“触手可及”。HunyuanVideo-Foley,正是这场视听革命中的一个响亮音符。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站

