2026年1月29日,对于AI视频生成社区来说,是一个值得标记的日子。
就在各家大厂还在把高质量视频模型藏在付费墙后面的时候,昆仑万维旗下的Skywork AI团队做了一个相当极客的决定:把他们最新的“全能型”视频生成大模型——SkyReels-V3,彻底开源了。
如果你是长期关注这个领域的开发者或创作者,你应该深知当下的痛点:想做个好视频,往往需要在Midjourney里画图,去Runway或Kling里动起来,最后还得找个LipSync工具对口型。流程割裂,风格难统一。
而SkyReels-V3这次最大的看点,就是它在一个统一的架构里,硬是塞进了三大核心能力:参考图生视频、视频无限延长、以及音频驱动虚拟人。
这不是一次简单的版本更新,这是一次对“全流程AI视频制作”门槛的降维打击。
从“抽卡”到“精准控制”:参考图生视频
在这个赛道,大家最怕的就是“崩坏”。你给了一张主角图,生成的视频里主角换了张脸,这在以前是常态。
SkyReels-V3在这个环节下了狠手。它支持输入1到4张参考图像。这意味着什么?你可以同时把人物的正脸、侧脸、甚至特定的服装细节喂给模型。
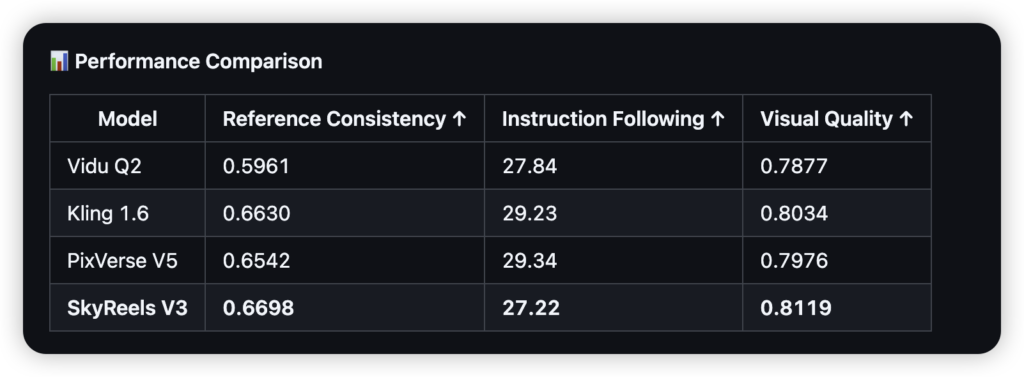
根据官方放出的硬核评测数据,在“参考一致性”这一指标上,SkyReels-V3拿到了0.6698的分数。为了让你对这个数字有概念,目前市面上的商业强手Vidu Q2得分是0.5961,而备受好评的Kling 1.6则是0.6630。也就是说,在保持人物长得像、衣服不乱变这件事上,这个开源模型已经略微领先了第一梯队的商业闭源模型。
同时,在视觉质量(Visual Quality)上,它以0.8119的得分压过了PixVerse V5和Kling 1.6。对于做电商广告或者影视预演的人来说,这不仅仅是参数的胜利,而是工作流可用的开始。
不再是5秒真男人:电影级的视频延长
短视频生成最大的尴尬在于时长。大多数模型只能跑个3到5秒,再长就变形。
SkyReels-V3引入了更符合影视逻辑的“视频延长”功能。它不仅能把5秒的镜头拉长到30秒,更关键的是它懂“镜头语言”。它内置了切入、切出、正反打等5种专业电影转场逻辑。
这意味着模型不是在机械地预测下一帧像素,而是在理解叙事。它知道什么时候该给特写,什么时候该切全景。通过统一的多分段位置编码技术,即使是复杂的运动场景,画面也能保持物理逻辑的连贯。
把数字人做进模型里:音频驱动虚拟形象
以前做“会说话的头像”(Talking Avatar),通常需要专门的独立模型。SkyReels-V3把这项能力也整合了进来。
只需要一张肖像图和一段音频,它就能生成口型精准、表情自然的视频,而且支持分钟级的长视频生成。这直接切中了数字人直播和在线教育的命门。
在评测中,它的音视频同步性得分高达8.18,视觉质量4.60。这个数据基本和垂直领域的霸主OmniHuman 1.5持平(OmniHuman同步性8.25)。但在SkyReels-V3里,这只是它众多功能中的一项而已。更炸裂的是,它是业内首个支持单镜头内“多角色多轮对话”的模型,这让生成双人访谈类内容成为了可能。
开源的诚意与野心
这次Skywork AI没有玩虚的。模型权重、推理代码在GitHub和Hugging Face上全部放出。
他们采用了一种“一核多支”的训练框架,通过高质量的混合数据训练,让模型具备了多模态的理解力。对于开发者而言,这意味着你可以下载模型,在本地(只要显存够,据悉优化到了24G显存以下)部署,甚至进行二次开发和微调。
除了硬核的代码,他们还提供了限时免费的API,并将这些能力集成到了自家的SkyReels平台上,让普通用户通过拖拽也能用上这些技术。
总的来说,SkyReels-V3的出现,打破了高性能视频模型必须闭源收费的刻板印象。它不仅在各项参数上硬刚主流商业模型,更重要的是,它把“做图+动效+口型”这三座大山铲平,铺成了一条通往全自动视频生成的平路。
对于内容创作者和开发者来说,2026年的开年大礼,确实够分量。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


