当业界仍在讨论大模型参数竞赛的尽头时,腾讯混元团队在2025年9月1日投下了一枚重磅炸弹:正式开源其轻量级翻译模型Hunyuan-MT-7B。这不仅是一款技术产品,更是对当前机器翻译发展路径的一次深刻审视与实践。
颠覆性的竞技表现:小体量,大胜利
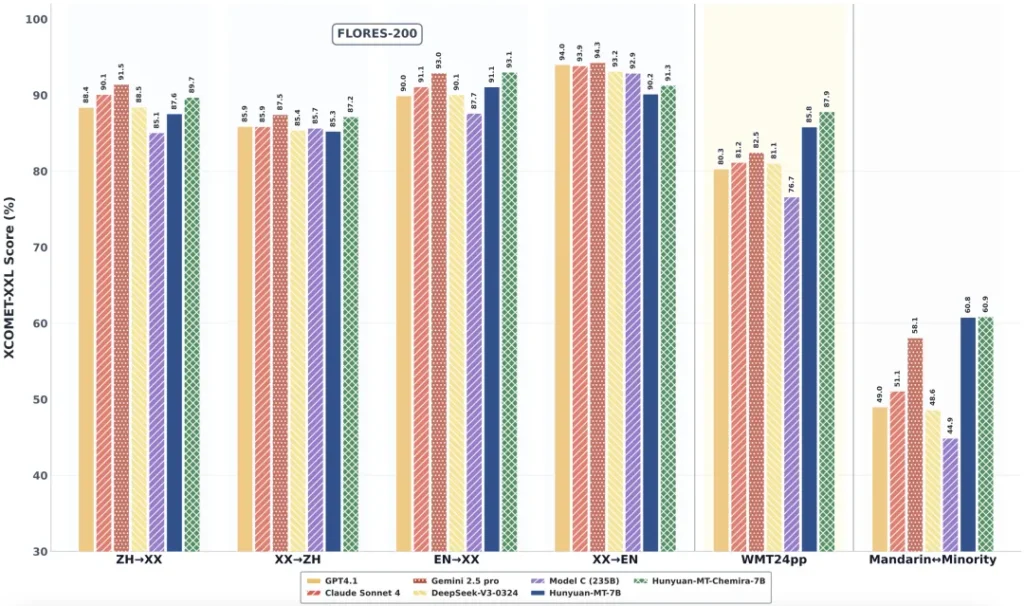
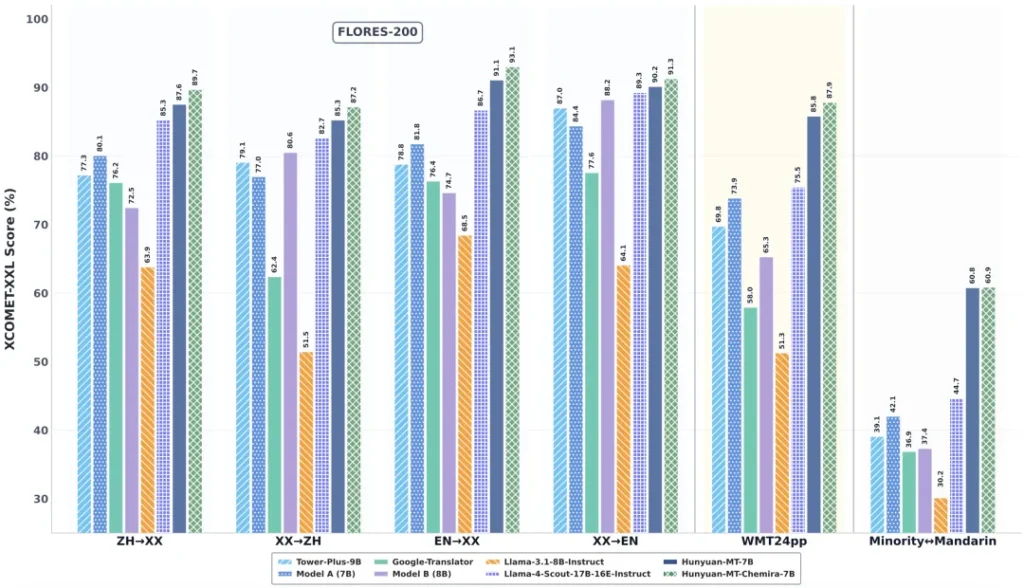
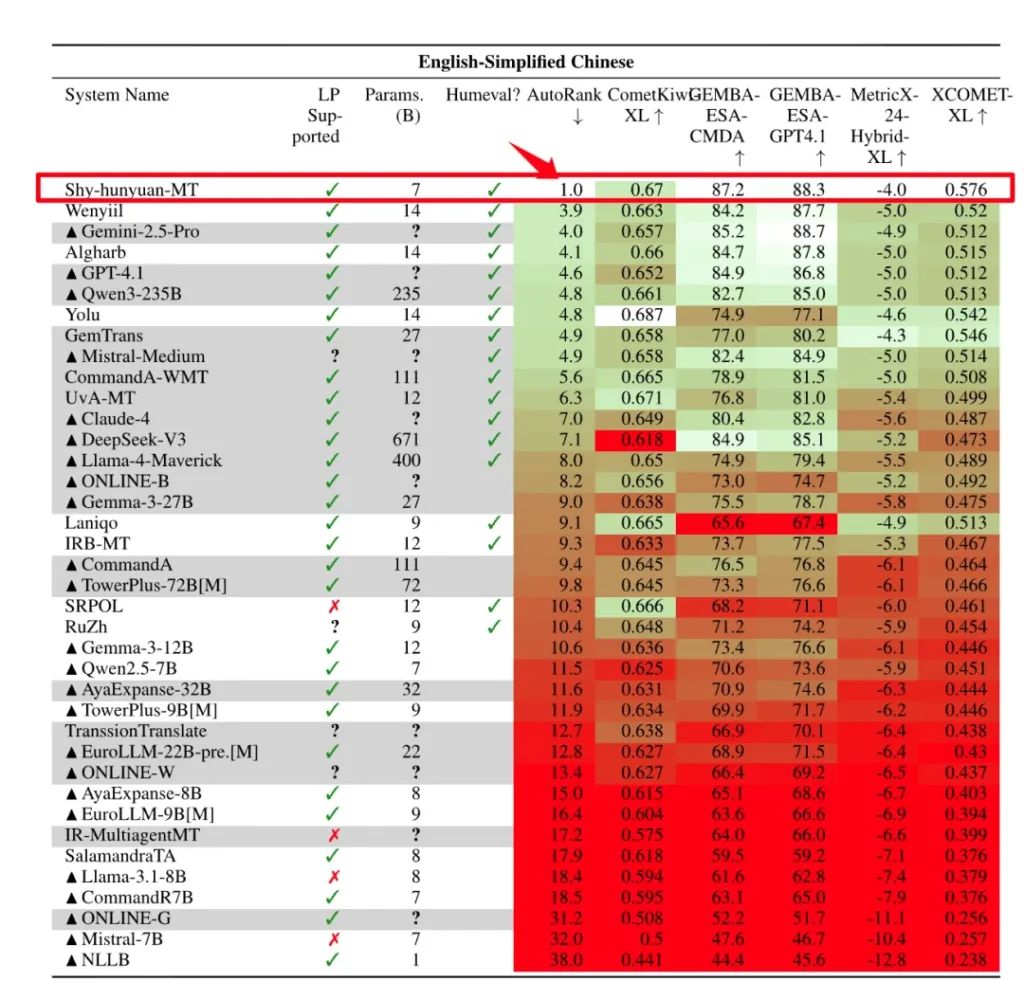
Hunyuan-MT-7B的实力并非流于纸面。在国际计算语言学协会(ACL)主办的WMT2025机器翻译比赛中,这款仅拥有70亿参数的模型,在31个语种方向中一举斩获了30个第一名。这一战绩无疑是现象级的,它不仅力压一众参数量更大的竞争对手,更在权威评测数据集Flores200上展现出足以媲美甚至超越部分巨型模型的性能。
这不单是一场胜利,它宣告了一个清晰的信号:机器翻译的领先地位,并非完全由参数规模所决定。精巧的设计、优化的训练策略,同样能够铸就卓越。
技术深挖:效率与创新的双轮驱动
Hunyuan-MT-7B的成功,离不开其背后一系列的技术创新。
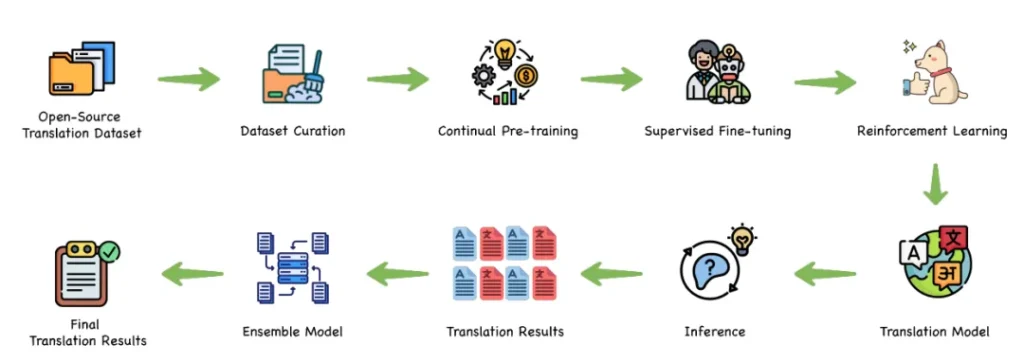
首先是其独特的“全链条训练范式”。腾讯混元团队构建了一个涵盖预训练、继续预训练(CPT)、监督微调(SFT)、翻译强化学习,乃至集成强化学习的完整流程。这种端到端、逐级精炼的训练方法,确保了模型能够在多维度上达到业界顶尖的翻译效果,实现了从基础能力到精细化输出的全面优化。
其次,模型的轻量化设计与高效推理是其核心竞争力之一。7B的参数规模天然具备部署优势,而通过腾讯自研的AngelSlim大模型压缩工具进行FP8量化后,其推理性能可再提升30%。这意味着Hunyuan-MT-7B能够在消费级硬件乃至边缘设备上高效运行,极大地降低了高性能翻译技术的应用门槛。
值得一提的是,随Hunyuan-MT-7B一同开源的还有Hunyuan-MT-Chimera-7B(奇美拉)。作为业界首个开源翻译集成模型,“奇美拉”能够智能融合多个翻译模型的输出,生成更为精良的译文。这种“弱到强”的强化学习集成策略,为专业级翻译场景提供了更为可靠的质量保障。
策略性布局:覆盖与理解的深度拓展
Hunyuan-MT-7B在语种支持上展现了其战略眼光,它支持33个语种互译,不仅涵盖了中、英、日等主流语言,更特别纳入了对藏语、维吾尔语、蒙古语等5种中国少数民族语言/方言的支持。这一举措不仅弥补了传统机器翻译在低资源语种上的短板,也彰显了其在文化传承和多语言交流方面的社会责任。
更深层次的突破在于其强大的上下文理解能力。得益于大模型技术底座,Hunyuan-MT-7B能够精准捕捉俚语、古诗词、网络用语等复杂语境下的深层含义,从而生成更自然、更贴合原文“神韵”的译文,显著提升了用户体验。这标志着机器翻译正从单纯的词句转换,迈向了对文化和语境的深度洞察。
市场影响与未来展望
Hunyuan-MT-7B的开源,无疑将在行业内掀起波澜。它不仅通过在Hugging Face、Github等平台的免费发布,推动了高性能机器翻译的民主化进程,使得更多中小企业和开发者能够低成本地获取顶尖技术。同时,这款模型也重新定义了机器翻译的评价标准,促使行业将目光从单一的参数规模,转向更为综合的效率、实用性与训练方法的优化。
未来,Hunyuan-MT-7B有望在更广泛的企业级应用场景中发挥价值,如腾讯会议、企业微信等产品已证实了其潜力。同时,其开源特性也将激励社区在垂直领域进行创新和微调,进一步拓展其应用边界。
结语
腾讯混元Hunyuan-MT-7B的问世,不仅仅是又一个开源模型的发布。它以其在性能、效率和语言覆盖上的卓越表现,清晰地描绘了机器翻译技术发展的一个新方向:在参数理性与技术创新并行的道路上,实现更广泛的普惠与更高质量的沟通。这是一款值得所有关注AI和多语言技术发展的人们,深入研究和实践的标志性产品。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站

