各位AI圈的朋友们,又一个重磅消息!美团在2025年10月17日悄然揭开了它在语音AI领域深耕已久的秘密武器——LongCat-Audio-Codec的神秘面纱。这可不是一个普通的编解码器,它旨在为语音大模型(Speech LLM)打造一套全新的“听”与“说”的链路。想象一下,我们离那个能真正流畅、自然、高效对话的AI,又近了一大步!
语音AI的“死结”与LongCat的破解之道
你可能想不到,现在我们与智能设备的那些看似流畅的语音交互背后,其实隐藏着不少“死结”。语音大模型在理解语义、生成逼真音色、同时还要保证实时响应这三者之间,常常难以兼顾。尤其是在将连续的语音信号转化为机器能理解的离散Token时,如何在压缩效率、信息保真度和延迟之间找到最佳平衡点,一直是困扰业界的难题。传统方法往往顾此失彼,导致语音助手偶尔的“卡壳”,或者合成语音听起来总有些“AI味儿”。
而LongCat-Audio-Codec的出现,正是为了破解这个死结。它就像给语音大模型装上了“顺风耳”和“巧舌”,背后有三大核心技术创新:
-
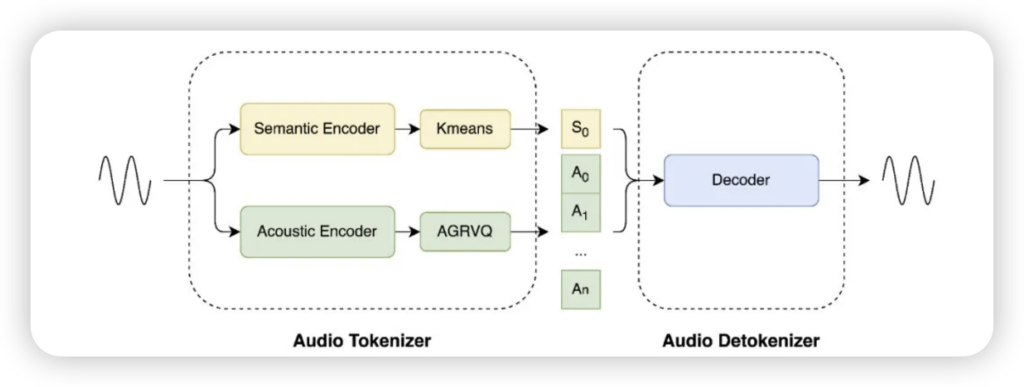
语义与声学双Token并行:听得懂,也听得好! 这是最亮眼的设计。LongCat巧妙地将原始音频信号分拆成两个平行的Token序列——一个专注于语义信息(你说了什么),另一个则捕捉声学信息(你说话的音色、韵律)。这种“分工合作”模式,让模型能更纯粹地理解内容,同时精细还原声音特质。它甚至可以动态调整声学码本数量,在不同场景下平衡计算负担与声音细节,真正做到了“按需定制”。
-
低延迟流式解码:告别“卡半秒”的尴尬! 你有没有遇到过跟语音助手对话,它总是慢半拍?LongCat为此设计了帧级增量处理的低延迟解码器,成功将端到端延迟控制在百毫秒级别。对于车载助手、实时翻译这些对实时性有极高要求的场景来说,这简直是救命稻草,让对话真正流畅起来。
-
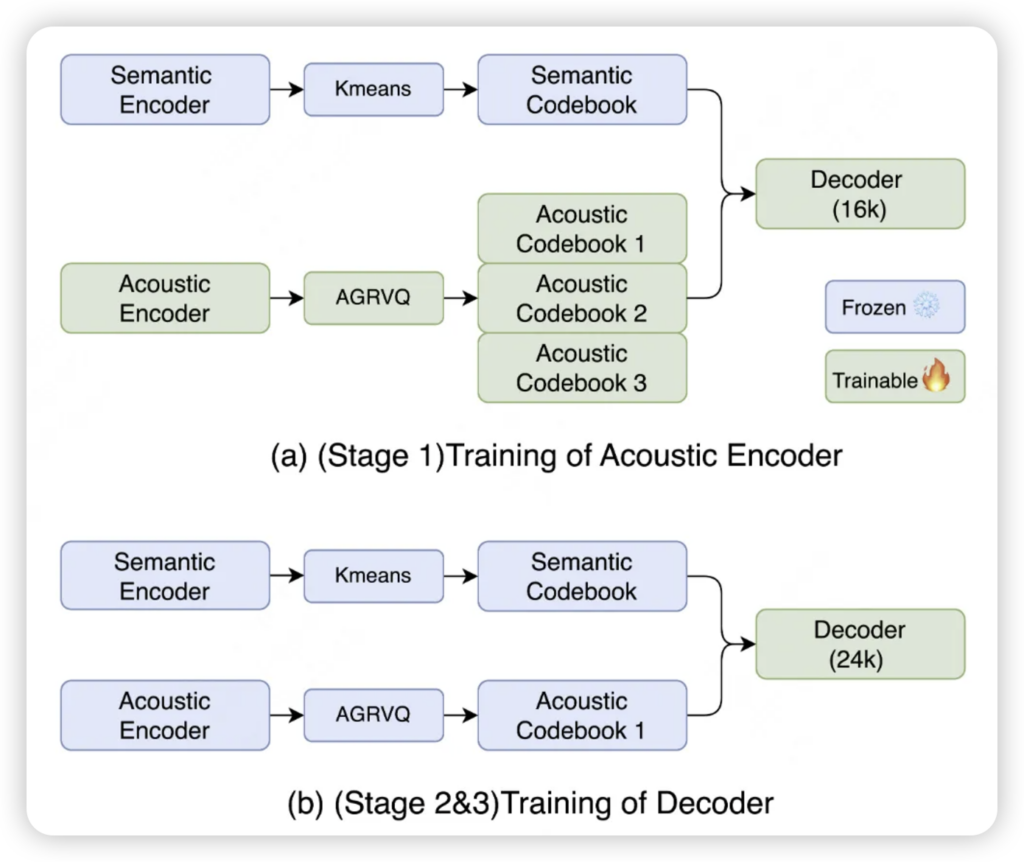
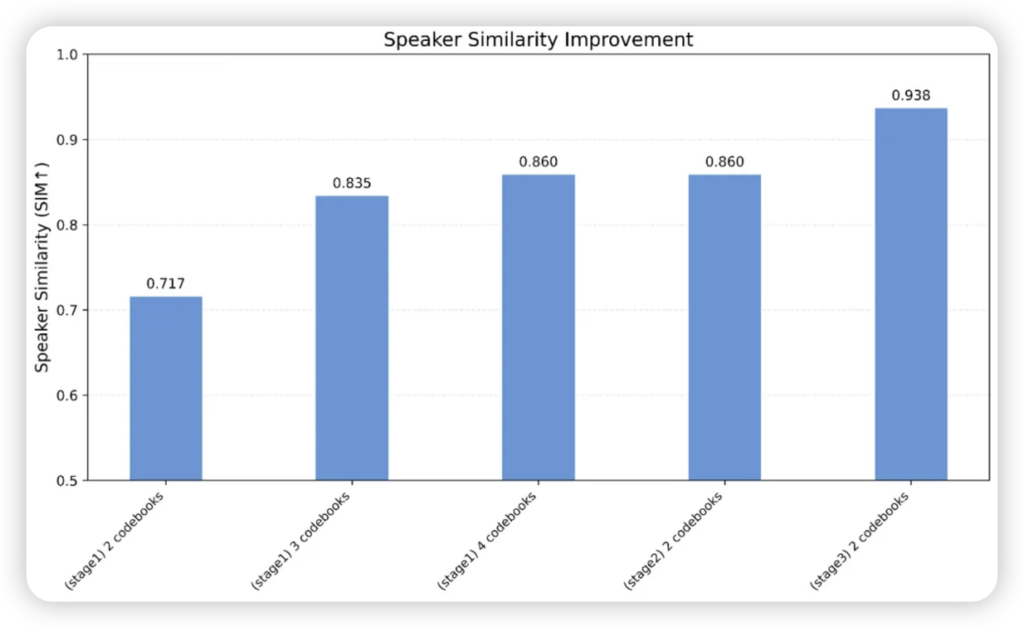
超低比特率与高保真“超能力”:小巧身材,大声量! 在保证音质的前提下,LongCat实现了惊人的压缩效率,最低支持到0.43kbps,却依然能保持高可懂度。更厉害的是,它还直接把“超分辨率”功能集成到了解码器中,无需额外模型就能提升输出音频的采样率和自然度。美团团队更是通过多阶段训练策略,将重建音频的无参考音质指标优化得超过了原始高质量录音,这着实令人惊叹!
性能跃升,体验升级
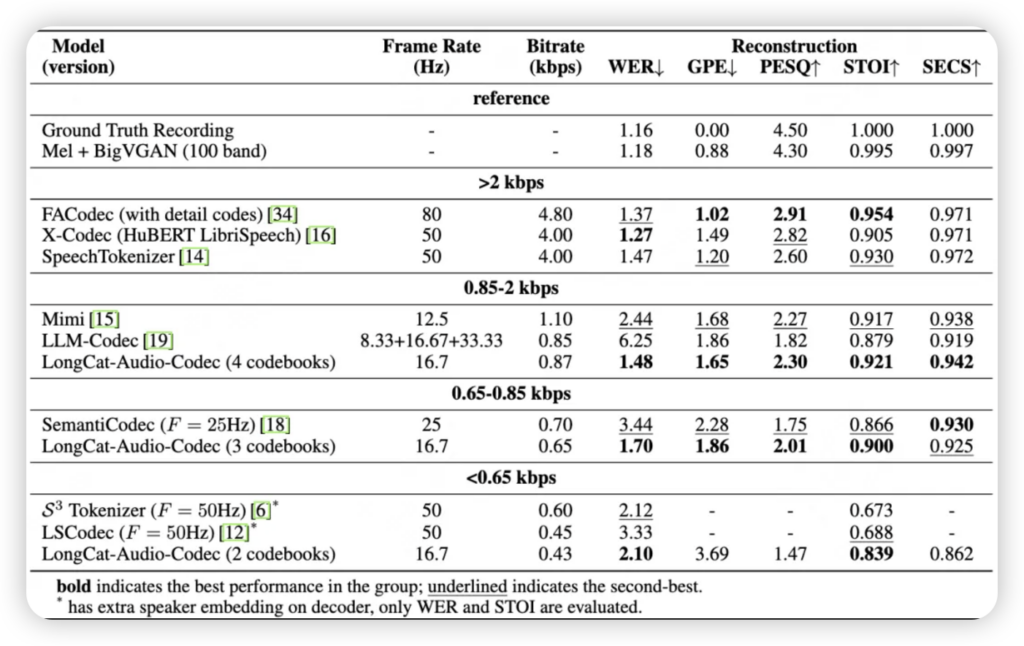
这些创新带来的效果是实打实的:在最低0.43kbps的极端比特率下,LongCat仍能保持基本的语音可懂性;而在0.87kbps的较高比特率下,其词错误率(WER)低至1.48%,语音质量(PESQ)和短时可懂性(STOI)也表现优异。更令人惊艳的是,经过美团团队的优化,LongCat重建音频的无参考音质指标(如SIGMOS和NISQA)甚至超越了原始高质量录音的参考值。这意味着,即使经过压缩和处理,我们听到的声音,在某些维度上甚至可能比原声更“悦耳”!
开源的意义与未来图景
美团选择将LongCat-Audio-Codec开源,无疑是给整个AI音频社区打了一针强心剂。
- 加速AI音频应用落地:高效、低延迟的编解码方案,将推动语音交互、语音搜索等AI音频应用在智能家居、车载、在线教育等更多场景下生根发芽。
- 降低开发门槛:开源意味着开发者可以免费使用并基于此创新,极大地降低了语音技术应用的门槛,有望催生更多新颖的语音AI产品。
- 赋能Speech LLM:它为语音大模型提供了从信号输入到输出的完整音频处理支持,让大模型能更深入地理解语音的“言外之意”和“弦外之音”,并生成更加符合人类听觉习惯的语音。
这项技术与美团已有的LongCat系列模型协同,正在构建一个从底层编解码到上层大模型的全栈式语音智能系统。这不仅仅是一个编解码器的开源,更像是美团向行业亮出了其在AI时代深耕产业应用、推动技术普惠的决心。
美团LongCat-Audio-Codec的到来,或许将成为语音AI领域的一个重要里程碑,我们有理由期待一个更加智能、更加流畅、无缝连接的语音交互时代。想要深入了解或尝试,不妨访问美团的GitHub和Hugging Face官方仓库,一探究竟!
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站

