在AI圈子里混久了,大家都有个心照不宣的认知:想训练顶级的SOTA(State of the Art)模型,似乎总绕不开那几张绿色的显卡。
但就在2026年1月14日,这个所谓的“铁律”被撕开了一道口子。
智谱AI联合华为悄无声息地开源了一个新家伙——GLM-Image。仅仅过了24小时,它就直接冲上了全球最大的AI开源社区Hugging Face的Trending榜单首位。这不仅是一次排名的更迭,更像是一场宣誓:即便完全脱离英伟达的硬件生态,全流程跑在国产算力上,我们依然能做出世界级的模型。
今天我们不谈那些晦涩的学术定义,单从技术和产业的角度,聊聊这个名为GLM-Image的项目到底为什么值得你关注。
并没有“大力出奇迹”,而是赢在架构
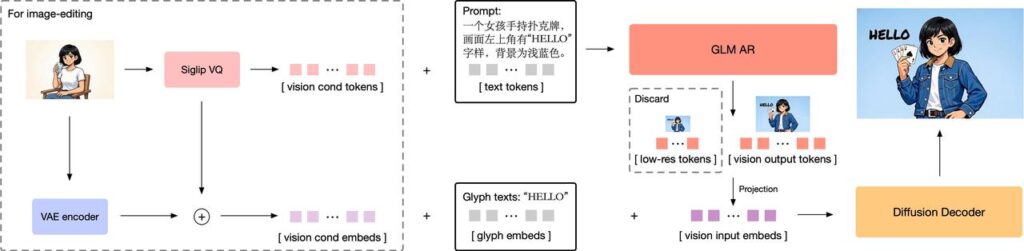
如果你只看参数量,GLM-Image并不是市面上最大的。它聪明在架构的设计上,采用了“自回归 + 扩散解码器”的混合打法。
我们可以把这个模型想象成一个配合默契的画家团队:
其中有一个90亿参数(9B)的自回归模型,它更像是一个“导演”或“构图师”。它的强项在于理解复杂的语言指令,规划画面的全局结构。它不负责具体的涂色,只负责把逻辑理顺,告诉后面的人:这里该有人,那里该有树,海报的标题必须放在正中间。
配合它的是一个70亿参数(7B)的扩散解码器,这是负责执行的“画师”。它拿着导演的草图,配合专门的字形编码器,开始精细地填充像素、还原光影,最重要的是——死磕文字的笔画细节。
这种组合拳彻底解决了一个长期困扰文生图领域的痛点:要么图好看但听不懂复杂指令,要么听得懂指令但画出来的字是乱码。GLM-Image在CVTG-2K(复杂视觉文本生成)榜单上拿下了开源第一,靠的就是这种分工明确的“脑手分离”架构。
真正的“全栈国产”意味着什么?
这才是GLM-Image最硬核的地方。
以往我们在谈论国产模型时,往往指的是算法层面的自研,但底层的训练芯片大概率还是依赖A100或H100。但GLM-Image这次把底裤都换了——它是首个从数据预处理、模型训练到最终推理,全流程基于华为昇腾Atlas 800T A2设备和昇思MindSpore框架完成的SOTA模型。
这意味着什么?
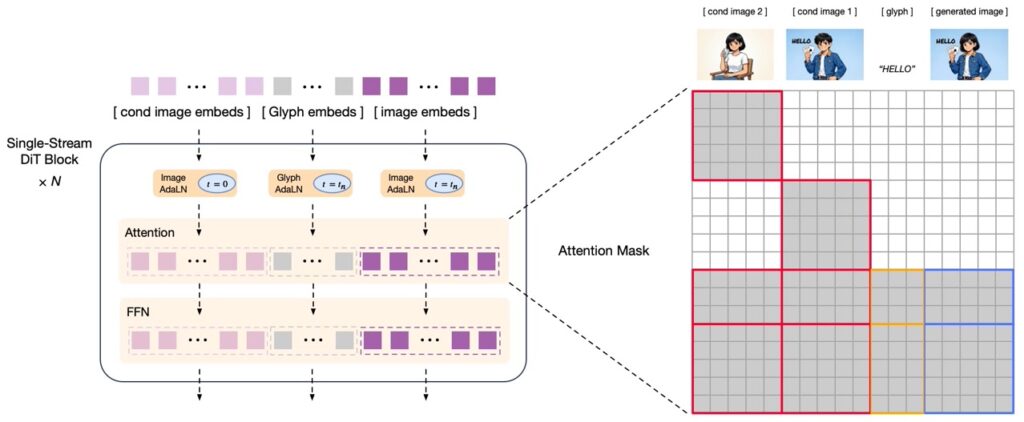
意味着智谱和华为的工程师们,硬是在国产硬件上跑通了复杂的分布式训练。他们用了动态图多级流水下发、高性能融合算子这些听起来很硬核的技术,去压榨昇腾NPU的性能上限。
结果证明,这套全栈国产的组合不仅能跑,而且跑得很快,甚至在训练效率上已经能和国际主流方案掰手腕。对于在这个特殊时期依然在探索AI自主可控的企业来说,这无疑是一剂强心针。
当AI不再“提笔忘字”
对于普通开发者和设计师来说,GLM-Image最直观的冲击力在于它对文字的处理能力。
用过Midjourney或DALL-E 3的朋友都知道,让AI画一只猫容易,但让AI在猫的衣服上准确写出“恭喜发财”这四个汉字,简直是噩梦。GLM-Image得益于其独特的字形编码器,在中文长文本渲染上表现出了惊人的准确率(Word Accuracy达到0.9116)。

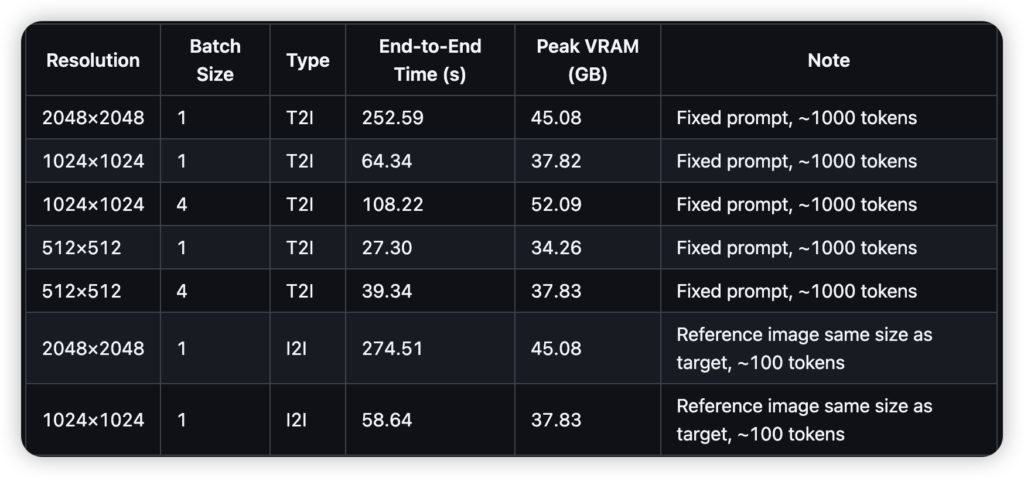
无论是做电商海报、科普插画,还是生成带文字的PPT配图,它都能做到字迹清晰、笔画准确。而且,它原生支持从1024到2048分辨率的任意比例生成,不需要重新裁剪或后期处理。
务实的定价与开源的诚意
最后聊聊钱。
技术再好,用不起也是白搭。GLM-Image在API调用模式下,生成一张图的成本仅为0.1元人民币。相比于国外同类产品动辄几毛甚至上块的价格,这个定价极其务实,几乎是贴着成本价在跑。
更重要的是,它彻底开源了。无论是GitHub还是魔搭社区,你都可以直接下载权重,在自己的服务器上部署。
总结一下,GLM-Image的出现,不仅为我们提供了一个好用的文生图工具,更是在全行业面前完成了一次极具象征意义的技术验证:在国产算力底座上,我们完全有能力通过架构创新和软硬协同,构建出具有国际竞争力的多模态大模型。
这,或许才是它霸榜Hugging Face背后的真正原因。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


