这几天科技圈最热闹的事,莫过于科大讯飞扔出的这颗重磅炸弹。
就在2026年2月11日,讯飞星火X2大模型正式发布。说实话,作为一名长期关注AI底层的博主,我起初对这场发布会的期待值是持保留态度的。毕竟市面上“吊打”、“遥遥领先”的PPT我们见得太多了。
但这次不一样。星火X2最让我感兴趣的不是它的参数量,而是它脚下踩着的基座——全链路国产算力。
没错,在被卡脖子的大背景下,讯飞这次没用英伟达,而是完全基于国产昇腾服务器跑通了训练和推理。这本身就是一个巨大的工程学信号。
293B参数,单卡居然能跑?
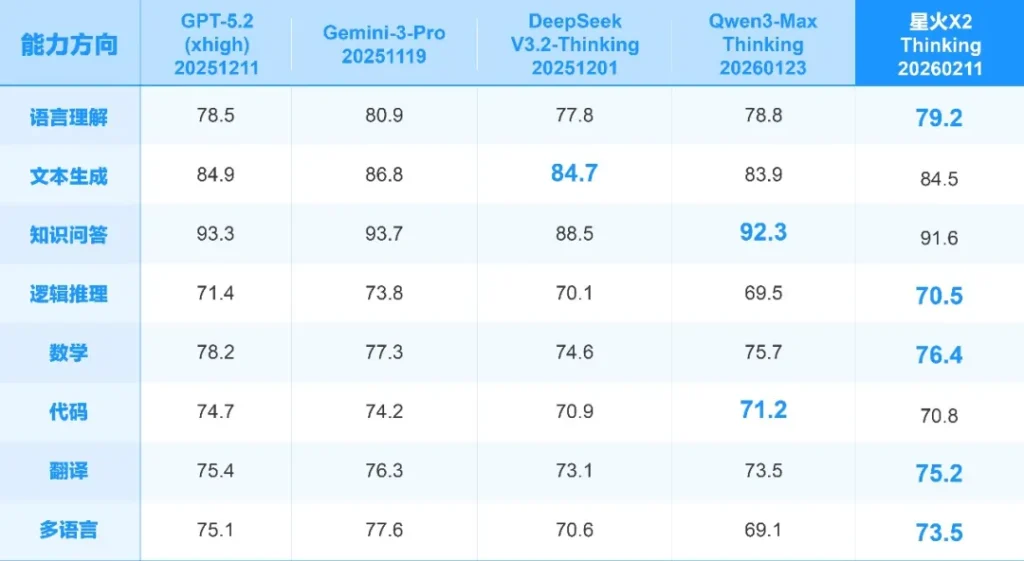
先看参数党最关心的硬指标。星火X2采用了293B的MoE(混合专家)稀疏架构。
两年前我们还在纠结MoE怎么训练稳定,现在讯飞已经把它玩出花了。他们搞定了一个叫“训推采样校准”的技术,简单说就是让模型在训练和推理时的表现更一致,不再是“模拟考满分,高考拉胯”。
最离谱的数据是部署门槛。对于千亿级参数的模型,通常需要昂贵的集群支撑。但星火X2通过极极致的权重量化和VTP(虚拟张量并行)技术,宣称单台国产昇腾服务器就能跑起来。
这对企业意味着什么?意味着私有化部署的成本直接腰斩。推理性能比上一代X1.5提升了50%,这在实际业务中是肉眼可见的流畅度提升。
不只是聊天,更是“做题家”
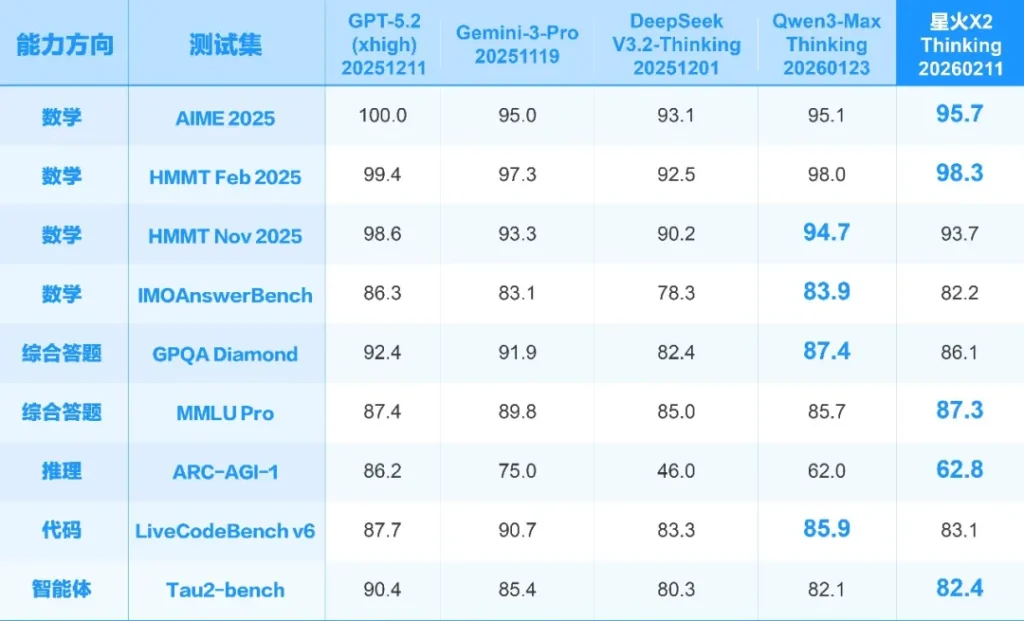
为了证明自己不是只能聊天的“吉祥物”,讯飞直接拿出了哈佛-麻省理工数学锦标赛(HMMT)的题目来练手。
演示中,X2不仅解出了这道英文高难数学题,甚至连步骤逻辑都严丝合缝。官方称其数学和逻辑推理能力已经“媲美国际最优”。虽然“对标”这个词在业界通稿里很常见,但结合其在医疗和教育领域的实战数据来看,这次的底气确实比以往更足。
说到实战,这才是讯飞的老本行。
垂直场景的“降维打击”
如果不谈落地,大模型就是空中楼阁。讯飞这次显然是盯着“干活”去的:
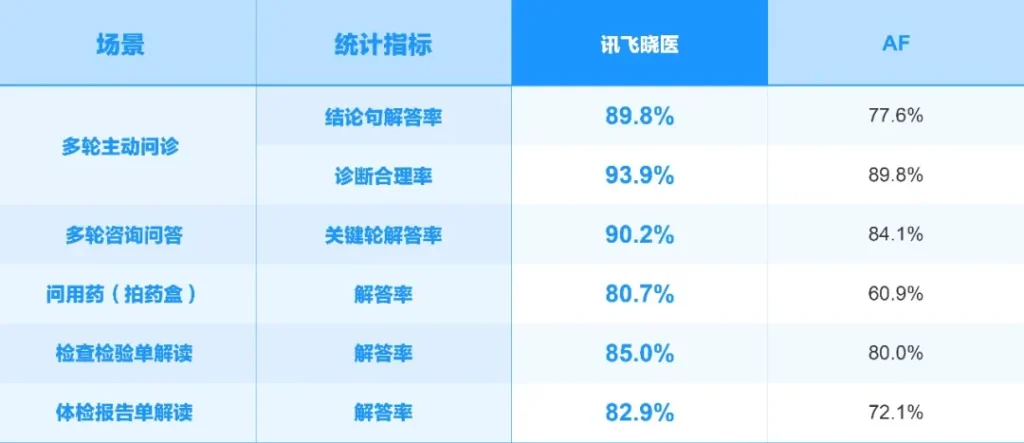
- 医疗领域:这可能是最硬核的背书。X2的医疗能力通过了上海市医疗大模型应用检测验证中心的评测。在看病历、写报告、审处方这些事上,官方数据显示它甚至压过了DeepSeek V3.2和GPT-5.2。
- 教育领域:AI学习机一直是个黑箱,以前是直接给你答案,现在X2能做到“错因贯穿”。它能像老师一样分析你为什么错,而不是仅仅告诉你什么是对的。
- 汽车座舱:这块大家痛点最深。以前的车机是“人工智障”,稍微复杂点的模糊指令就听不懂。X2上车后,把那套基于2B/7B小模型的意图理解能力拉高了一个档次,终于能听懂人话了。

商业化的野心
还有一个数据很有意思。2025年,讯飞拿下了23.16亿元的大模型中标金额,比第二名到第六名的总和还多。这说明在B端市场,尤其是在政企、央国企这些对数据安全和国产化极其敏感的领域,讯飞已经建立了绝对的护城河。
写在最后
星火X2的发布,某种意义上是中国AI产业的一个分水岭。
它证明了在顶级算力受限的情况下,通过算法优化和工程创新(MoE架构+国产硬件软硬协同),我们依然能造出第一梯队的大模型。
对于开发者来说,讯飞这次也挺大方,新注册直接送100万Tokens。不管你是做应用的还是纯粹的技术爱好者,我都建议你去试一试。毕竟,在全栈国产化的这条路上,星火X2可能是目前最接近“完全体”的样本。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


