一、这到底是什么"黑科技"?
想象你有一个超级智能机器人,它的大脑里住着100位专家——有人擅长翻译,有人擅长绘画,还有人是代码专家。传统的AI模型会要求所有专家同时工作,结果就是能源爆炸、效率低下。而DeepSeek EP就像一位天才总调度师,让专家们各司其职的同时,还能完美配合。
这种名为"专家并行(EP)"的技术,专为解决混合专家模型(MoE)的核心痛点而生。就像在城市中架起高架桥缓解交通拥堵,DeepSeek EP通过优化专家之间的通信网络,让原本"堵车"的AI训练现场瞬间畅通。

二、简单的项目介绍
- DeepEP 是为专家混合 (MoE) 和专家并行 (EP) 量身定制的通信库。它提供高吞吐量和低延迟的 all-to-all GPU 内核,也称为 MoE dispatch 和 combine。该库还支持低精度运算,包括 FP8。 为了与 DeepSeek-V3 论文中提出的组限制门控算法保持一致,DeepEP 提供了一组针对非对称域带宽转发进行了优化的内核,例如将数据从 NVLink 域转发到 RDMA 域。这些内核提供高吞吐量,使其适用于训练和推理预填充任务。此外,它们还支持 SM (Streaming Multiprocessors) 号码控制。 对于延迟敏感型推理解码,DeepEP 包括一组具有纯 RDMA 的低延迟内核,以最大限度地减少延迟。该库还引入了一种基于 hook 的通信计算重叠方法,该方法不占用任何 SM 资源。
注意:本库中的实现可能与 DeepSeek-V3 论文有一些细微的差异。
- 性能NVLink 和 RDMA 转发的性能测试
- 普通内核测试(H800) 我们在 H800 上测试普通内核,每个内核都连接到 CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约 50 GB/s)。测试遵循 DeepSeek-V3/R1 预训练设置(每批 4096 个令牌、7168 个隐藏、前 4 组、前 8 名专家、FP8 调度和 BF16 组合)。
| 类型 | 调度 #EP | 瓶颈带宽 | 结合 #EP | 瓶颈带宽 |
|---|---|---|---|---|
| 节点内 | 8 | 153 GB/s (NVLink) | 8 | 158 GB/s (NVLink) |
| 节点间 | 16 | 43 GB/s (RDMA) | 16 | 43 GB/s (RDMA) |
| 节点间 | 32 | 44 GB/s (RDMA) | 32 | 47 GB/s (RDMA) |
| 节点间 | 64 | 46 GB/s (RDMA) | 64 | 45 GB/s (RDMA) |
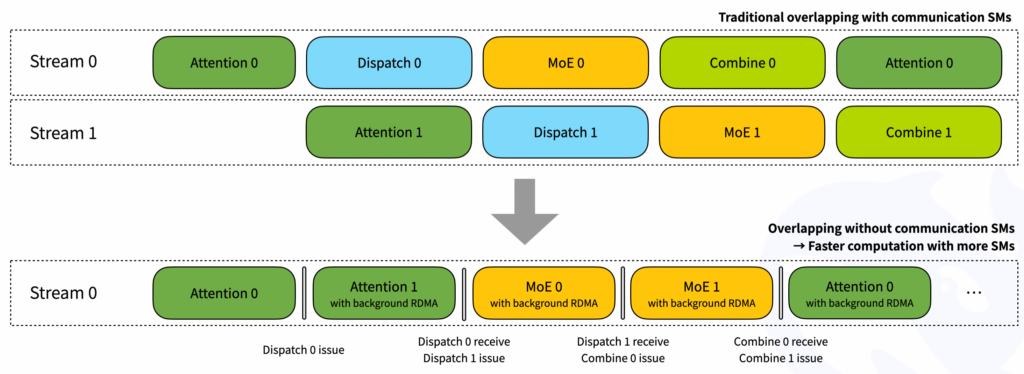
- 低延迟内核测试(H800) 我们在 H800 上测试低延迟内核,每个内核都连接到 CX7 InfiniBand 400 Gb/s RDMA 网卡(最大带宽约 50 GB/s)。测试遵循典型的 DeepSeek-V3/R1 生产设置(每批 128 个令牌,7168 个隐藏,前 8 名专家,FP8 调度和 BF16 组合)。
| 调度 #EP | 延迟 | RDMA 带宽 | 结合 #EP | 延迟 | RDMA 带宽 |
|---|---|---|---|---|---|
| 8 | 163 微秒 | 46 GB/s | 8 | 318 微秒 | 46 GB/s |
| 16 | 173 微秒 | 43 GB/s | 16 | 329 微秒 | 44 GB/s |
| 32 | 182 微秒 | 41 GB/s | 32 | 350 微秒 | 41 GB/s |
| 64 | 186 微秒 | 40 GB/s | 64 | 353 微秒 | 41 GB/s |
| 128 | 192 微秒 | 39 GB/s | 128 | 369 微秒 | 39 GB/s |
| 256 | 194 微秒 | 39 GB/s | 256 | 360 微秒 | 40 GB/s |

三、三招解锁AI效率密码
-
通信智囊团:独创的"全对全通信优化",好比把普通公路升级为立体交通枢纽,数据传输效率暴涨40%。更聪明的是,它能让数据传输和计算任务像双人滑冰般默契配合,GPU再也不用停工等数据。
-
精算大师:支持最新的FP8低精度计算,将每个数据包的"重量"减少一半。就像用真空压缩袋打包棉被,运载效率却丝毫不降,最高可节省35%的计算资源。
-
硬件达人:深度绑定NVIDIA显卡并非偶然。通过挖掘GPU超高速通道NVLink的潜力,让专家间的"密谈"速度达到普通网络传输的8倍。这种强强联合,就像给法拉利发动机匹配了专用赛道。
四、看得见的科技红利
在杭州某AI实验室,原本需要3周完成的语言模型训练,现在10天就能收工。上海一个医疗AI团队使用后,每天处理的医学影像分析量翻了两番。这些改变正在从三个方面重塑科技版图:
- 成本大瘦身:企业级AI训练开支平均降低42%,让中小团队也能玩转大模型。
- 应用加速度:智能客服响应时间缩短70%,自动驾驶决策延迟降低至毫秒级。
- 科研破上限:支持千亿参数规模的模型训练,为真正的通用AI铺平道路。
五、未来已来:当效率革命席卷全球
DeepSeek EP的开源如同投下科技界的"开放种子"。在深圳,创业团队用它开发出精准度前所未有的工业质检系统;在硅谷,科学家正在探索十万亿参数的超级大脑;而普通用户即将体验到更流畅的智能助手和更聪明的推荐系统。
展望未来,这项技术或许会催生出真正的"通用型AI管家"。到那时,你的手机助手不仅能理解冷笑话,还能实时翻译80种语言,甚至通过分析你的表情调整沟通策略——所有这些魔法,都始于今天这场安静的通信效率革命。


文章评论