全世界的AI圈子,似乎都在屏息等待。从各种小道消息到官方偶尔泄露的只言片语,过去这一个月,大家都在猜测阿里通义千问的下一代大模型——Qwen3,到底会带来怎样的惊喜。今天,靴子终于落地!Qwen3 正式发布,我只能说:这一个月,值了!它不仅仅是升级,更像是一场开源大模型的“范式革新”。
如果让我用一句话概括 Qwen3 的核心印象?那就是:思考更深,速度更快。 这听起来有点矛盾?别急,这恰恰是 Qwen3 最具颠覆性的地方。
告别“比肩”时代:它敢说自己是“全球最强开源”!
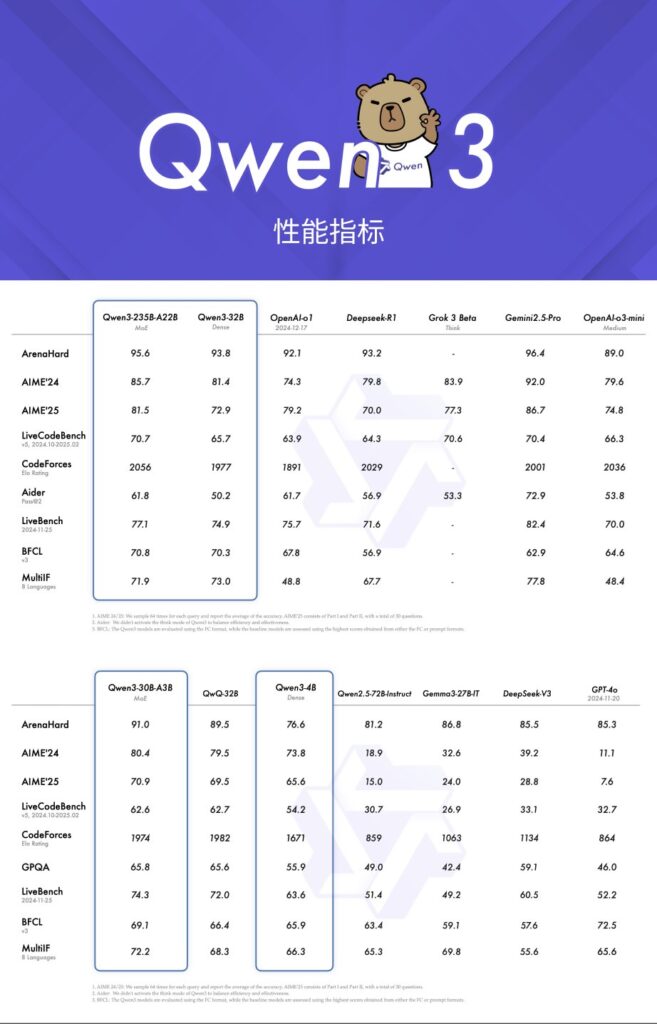
敢说自己是“全球最强开源模型”,这底气从何而来?Qwen3 直接亮出了成绩单:性能全面超越了 DeepSeek R1!
各位玩家可能知道,R1 之前一直是开源界的天花板,国内其他模型提到 R1,大多还在用“比肩”这个词。而 Qwen3,是国内第一个敢于正面宣告“全面超越” R1 的模型。
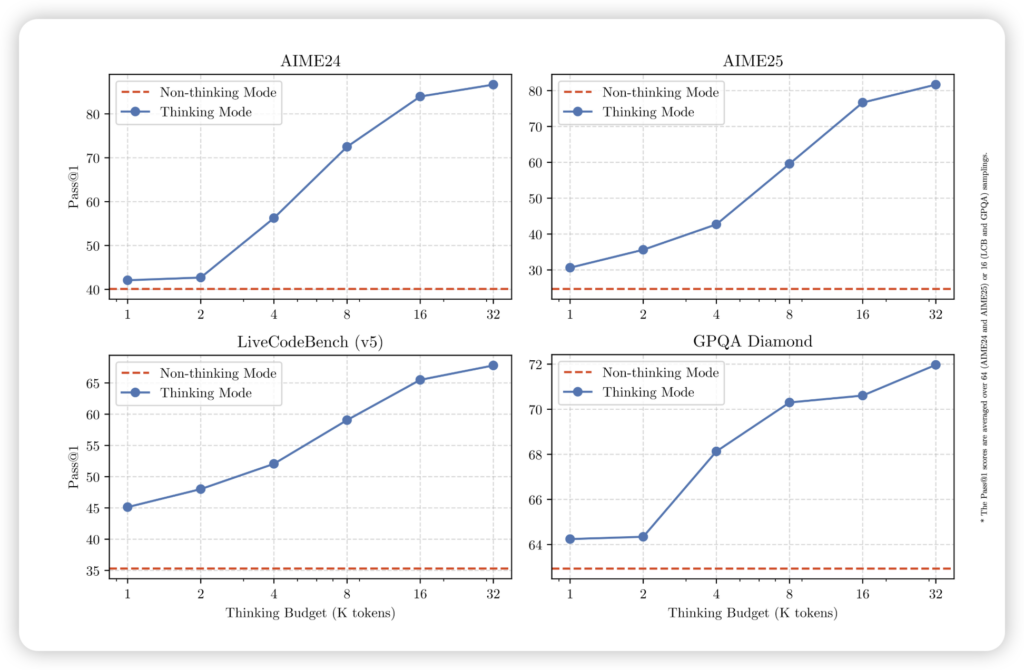
在最考验模型硬实力的数学、代码等各项基准测试中,Qwen3 的旗舰版本都展现出了统治级的表现,甚至对标 OpenAI 的 o1 和 o3 mini、以及 Grok3 这样的顶尖闭源模型,也毫不逊色。这意味着,无论你是用它来解复杂的数学题、生成高质量的代码,还是进行逻辑推理,Qwen3 都能给你更精准、更可靠的答案。
国内首创“混合推理”:一颗既能深思也能闪回的大脑!
还记得我说它“思考更深,速度更快”吗?这要归功于 Qwen3 独创的 “混合推理”模型。这可是国内大模型的头一份!
想象一下,当你向 AI 提问时:
- 问一个简单的事实性问题(比如“北京的首都是哪里?”),它能像闪电一样瞬间给出答案,几乎零延迟!
- 抛给它一个复杂的挑战(比如“解释一下链式思考的过程,并用 Python 写个模拟代码”),它不会敷衍了事,而是会进入“思考模式”,进行层层推理,一步步拆解问题,最后给你一个结构清晰、逻辑严密的深度回答。
Qwen3 厉害的地方就在于,它能根据你问题的复杂程度,自动切换 这种“深度思考”和“即时响应”模式。这不像很多模型只能选择一种风格。这种动态切换,简直就像给模型装了一个智能的“双模引擎”:既保证了解决复杂问题的“智力上限”,又在处理简单任务时大幅节省了宝贵的计算资源和时间。 这不就是我们梦寐以求的“智力与效率的双向奔赴”吗?!

成本屠夫来了!顶级模型不再是“烧钱怪兽”
以往,想要本地部署一个性能顶尖的大模型?那意味着动辄几十张 GPU 的庞大集群和天文数字的投入。 DeepSeek R1 的部署要求就让很多中小企业和研究机构望而却步。
但 Qwen3 彻底改变了游戏规则!
它大幅降低了模型部署的硬件要求。重点来了:Qwen3 的旗舰模型,Qwen3-235B-A22B(虽然总参数庞大,但每次推理只激活其中一部分),竟然只需要区区 4 张 H20 显卡,就能实现本地部署!
这是什么概念?这硬件需求量,据官方和社区反馈,只有 DeepSeek R1 所需硬件的 三分之一!由此带来的部署成本下降更是惊人,估算下来能比 R1 下降 超过六成!
(此处建议插入图片:一张对比图或简单图标,对比 Qwen3 旗舰版和 DeepSeek R1 部署所需的 GPU 数量(例如 4个 GPU vs 12个+ GPU 的简笔画),并标注“成本下降超60%”。)
这意味着什么?意味着顶级开源大模型不再是少数巨头的专属玩物。更多企业、更多高校、甚至是一些具备一定硬件条件的个人开发者,都能以远低于过去的门槛,拥有并掌控世界顶级的开源 AI 能力。这对于推动整个开源生态的繁荣和 AI 技术的普及,无疑是里程碑式的一步!
Agent 能力爆炸提升:国内工具开发者有福了!
AI 的未来,很大程度上在于 Agent(智能体)的应用。Agent 就像是 AI 的“手和脚”,让模型能调用工具、与环境交互、完成更复杂的任务。Qwen3 在 Agent 能力上做了大幅优化,特别是 原生支持了 MCP 协议,这极大地提升了模型的代码理解、生成和执行能力,也让它在进行多步规划、工具调用时更加稳定可靠。
我可以大胆地说,国内一大批正在开发 Agent 工具和应用的团队,可真是等到 Qwen3 登场了!它的强大 Agent 底座,无疑会成为他们打造下一代智能助理、自动化流程和创新应用的得力引擎。新一轮的 Agent 应用爆发潮,或许就将由 Qwen3 点燃!
普惠全球:119种语言和方言,让AI无处不在
AI 不应该有语言的壁垒。Qwen3 深谙此道,它支持的语言和方言数量达到了惊人的 119 种!这不仅仅是常见的几大语种,更包括了爪哇语、海地语等众多地方性语言。
这意味着,无论你身处世界的哪个角落,使用哪种语言,都有机会直接与 Qwen3 进行交互,享受 AI 带来的便利和价值。这种对全球语言多样性的支持,真正体现了开源模型“普惠”的精神,让全世界的用户都能零距离拥抱 AI。
海量数据喂养:36万亿Token铸就的智能基石
模型的智能程度,与它的训练数据量和质量密不可分。Qwen3 在这方面也毫不手软,它的训练数据量直接飙升到了 36 万亿 token!这是 Qwen2.5 训练数据量的 整整两倍!
更重要的是,这些数据并非简单堆砌。除了海量的网络抓取内容,Qwen3 还创新性地 大量提取了 PDF 文档的结构化内容(这对于理解专业文档、报告等至关重要),并 合成生成了大量的代码片段。这种多样化、高质量的数据“喂养”,为 Qwen3 强大的通用能力、代码能力和专业领域知识奠定了坚实的基础。
模型家族:从手机到服务器,总有一款适合你
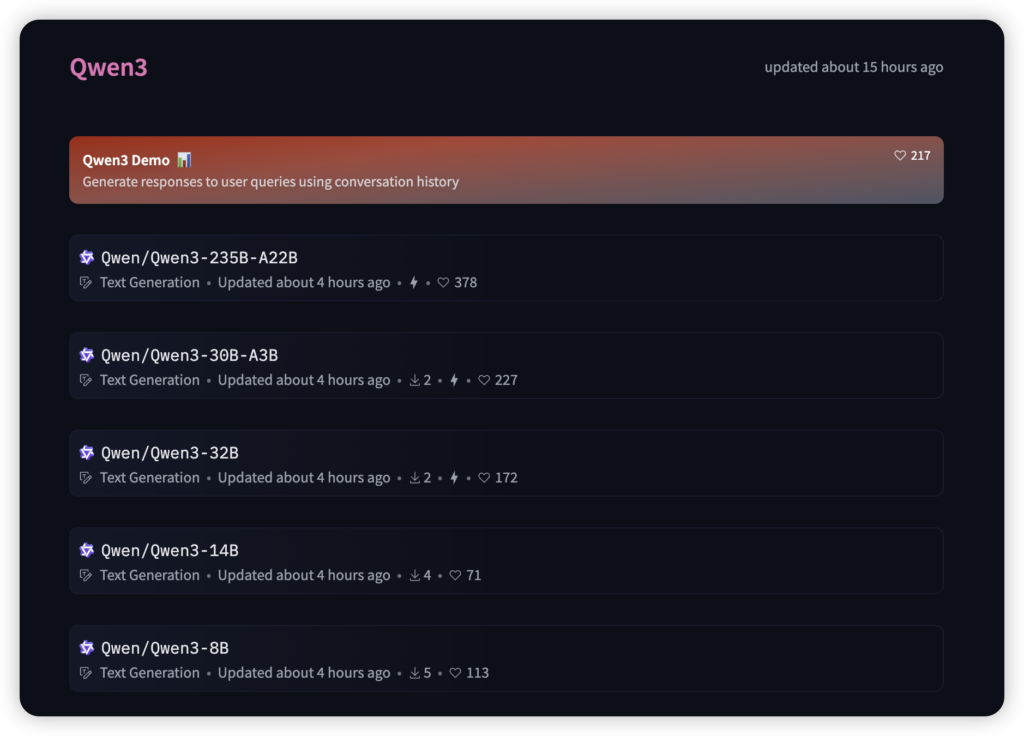
Qwen3 不止一个模型,它是一个庞大的“模型家族”,总共开源了 8 款模型,包括备受瞩目的 2 款 MoE 模型和 6 款 Dense 密集模型:
- MoE 模型:
- 旗舰版 Qwen3-235B-A22B:性能最强,激活参数 22B,部署成本低(前面说过的 R1 三分之一)。
- 迷你版 Qwen3-30B-A3B:激活参数仅 3B,性能却能媲美 Qwen2.5-32B!非常适合在消费级显卡上部署,让你的个人电脑也能跑起强大的 AI。
- Dense 模型:
- 0.6B、1.7B、4B、8B、14B、32B:从超轻量级到企业级全面覆盖。那个 0.6B 的小家伙,甚至可以在手机等端侧设备上顺畅运行!
这种全栈的模型矩阵,让 Qwen3 能够满足从个人开发者在笔记本上探索,到企业级大规模部署的各种需求,真正实现了技术的平民化和普惠化。
总结:等,是值得的!
全世界等了一个月,Qwen3 终于来了!它不仅带来了性能上的飞跃,直接挑战并超越了此前的开源霸主,更在技术架构上进行了大胆创新,尤其是“混合推理”模式,完美平衡了效率与智能。再加上大幅降低的部署成本、强化的 Agent 能力、广泛的多语言支持以及扎实的数据基础,Qwen3 无疑是当前开源大模型领域最闪耀的新星。
它让顶级 AI 能力不再遥不可及,让 Agent 应用的想象空间被进一步打开,让全球用户都能享受到 AI 的便利。
这是一个令人兴奋的时刻!Qwen3 的发布,不仅仅是阿里通义千问团队的技术胜利,更是整个开源 AI 社区的巨大福音。
如果你对大模型感兴趣,Qwen3 绝对是你不能错过的新宠。去 Hugging Face、ModelScope 等平台看看吧,亲手体验一下这个既能“深思”又能“秒回”的开源新王!
未来已来,Qwen3,全速开跑!
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论