曾几何时,强大的 AI 能力似乎总是与庞大的数据中心、高昂的计算成本划等号。但现在,Google 用全新发布的 Gemma-3n 系列小模型,将这份“智能”悄然送入了你我身边的每一个设备。想象一下,你的手机能理解视频内容并给出描述,你的智能手表能实时翻译外国语种,你的车载系统能通过摄像头和麦克风感知周围环境……这一切,Gemma-3n 正让它成为可能。

告别云端依赖,智能就在“身边”
Gemma-3n 系列最令人兴奋的特点是,它专为 嵌入式设备 量身打造,能直接在你的手机、平板、甚至一些物联网设备上运行。这意味着什么?
- 隐私更安全:你的数据不必离开设备,处理过程更加安全可靠。
- 响应更迅速:无需网络连接,即时响应,摆脱网络延迟的烦恼。
- 离线也能用:即使在没有信号的环境下,AI 功能依然在线。
这标志着 AI 的应用场景从云端走向了更广阔的边缘,让智能真正触手可及。
不止是文本,更懂“万象”
Gemma-3n 不仅仅是一个文本处理模型,它是一个真正的 “多面手”。原生支持 图像、音频、视频和文本 四种输入,并能输出文本。这意味着你可以:
- “看”懂世界:通过摄像头识别物体、场景,进行视频内容分析。
- “听”懂万语:进行语音识别,甚至在不同语言间进行实时翻译。
- 多模态联动:结合多种信息,实现更智能的交互,比如通过语音指令控制手机的图片编辑功能。
轻巧身躯,强大内核:技术背后的魔法
如此强大的能力,是如何塞进小巧的设备里的呢?Google 的工程师们施展了多项“魔法”:
-
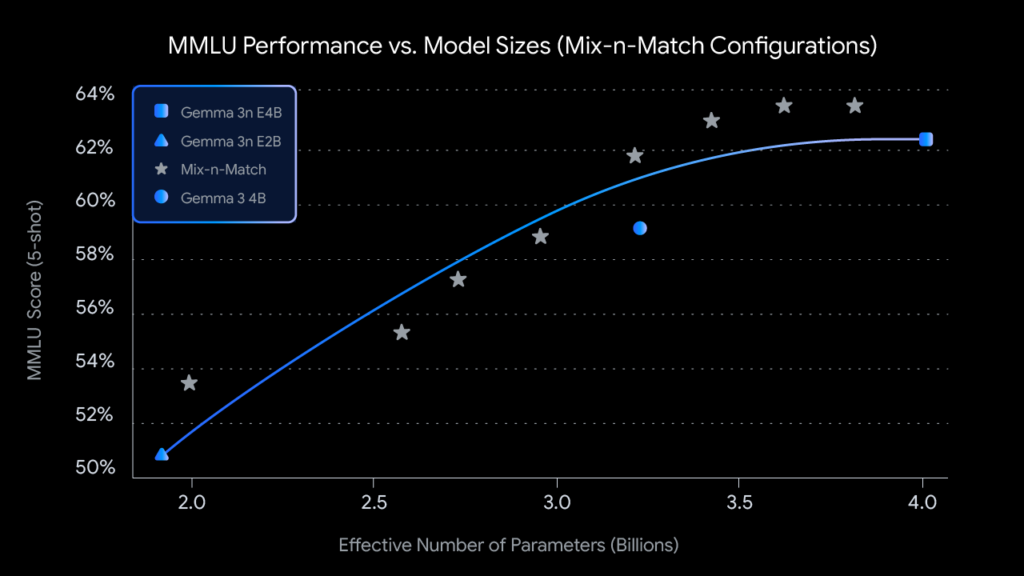
MatFormer 架构:像俄罗斯套娃一样灵活 这个创新的架构允许模型在训练 80 亿参数(E4B)的同时优化 50 亿参数(E2B)。就好比一个大模型里藏着一个精巧的小模型,你可以根据设备的具体性能,动态选择最适合的“大小”来运行,实现性能和效率的最佳平衡。
-
Per-Layer Embeddings (PLE):内存占用大幅削减 为了让模型在内存有限的设备上运行,Gemma-3n 采用了革命性的 PLE 技术。它能智能地将部分参数“卸载”到 CPU,让 80 亿参数的模型,实际运行所需的内存,仅相当于传统 40 亿参数的模型。这意味着即便是配置稍低的设备,也能流畅运行。

- 专为移动优化的编码器:
- 视觉处理:搭载的 MobileNet-V5-300M 视觉编码器,能处理最高 768x768 像素 的图像,并在 Google Pixel 手机上实现 每秒 60 帧 的视频处理速度。
- 音频处理:基于通用语音模型(USM)的音频编码器,支持 自动语音识别 (ASR) 和 自动语音翻译 (AST),并且在多种语言间的翻译表现尤为出色。
小模型,大作为:性能亮眼,应用无限
别看 Gemma-3n 系列参数量不大,它们的性能却非常惊人:
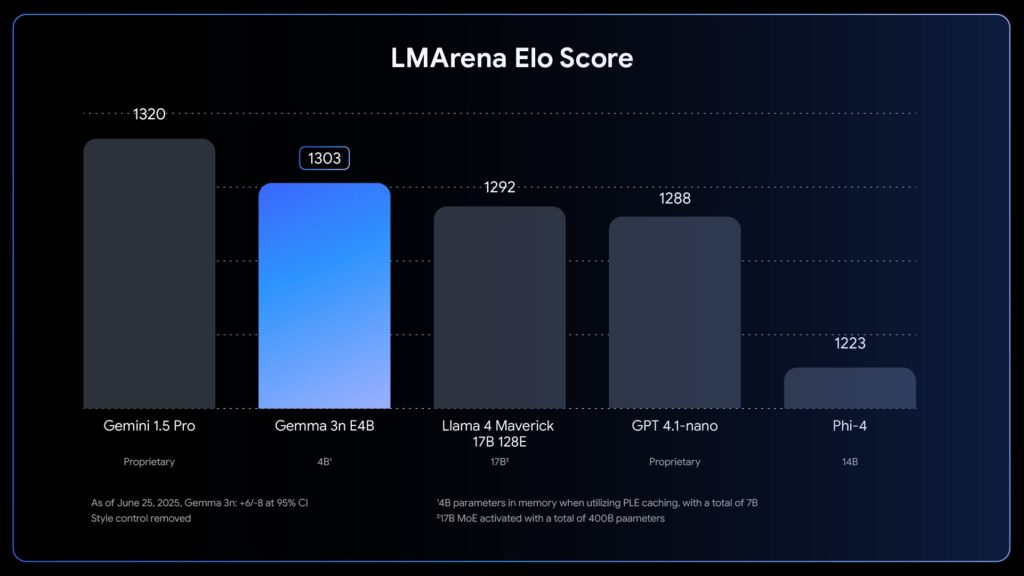
- 80 亿参数的 E4B 模型,在著名的 LMArena 评测中得分超过 1300 分,成为首个参数量低于 100 亿却能达到此成绩的模型。
- 能效比极高,在 Google Pixel 手机上,1080p 视频帧的解析成功率高达 90%,甚至能实现长达 30 秒的语音片段离线识别和翻译。
这些能力为各种创新应用打开了大门:
- 旅行助手:离线实时语音翻译,打破语言障碍。
- 无障碍交互:为视障人士提供实时的环境描述。
- 内容创作:在手机上实现视频的智能剪辑和字幕生成。
- 智能家居:通过语音和图像更自然地与家居设备互动。
开放与赋能:加速端侧 AI 的普及
Google 将 Gemma-3n 系列模型 全面开源,开发者们可以通过 Hugging Face、Google AI Studio 等平台轻松获取和使用。这意味着一个充满活力的开发者生态即将形成,更多创新应用将由此诞生。
Gemma-3n 的推出,不仅是 Google 在 AI 领域的一次技术飞跃,更是对 “AI 普惠化” 愿景的生动实践。它证明了强大的 AI 能力可以不再受限于昂贵的硬件和复杂的云基础设施,而是可以嵌入到我们日常使用的每一个设备中,让智能真正成为我们生活的一部分。
准备好迎接一个更智能、更懂你的未来了吗?Gemma-3n 已经启程。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论