2025年10月,当许多人还在讨论大模型如何更好地对话、写文章时,北京智源人工智能研究院悄然发布了一个名为“悟界·Emu3.5”的家伙。它带来的,远不止是模型参数的又一次攀升,而是人工智能对“真实世界”理解方式的一次根本性变革。这不禁让人惊叹,AI,似乎终于开始摸到世界的脉搏了!
从“文字接龙”到“世界预判”的跃迁
想象一下,过去的AI更像一个超级会接龙的诗人,你给它一个词,它能根据概率接出下一个。但Emu3.5呢?它开始尝试成为一个能看懂电影、甚至预判电影走向的“导演”。它的目标不再是简单地预测“下一个词”或“下一个像素块”,而是要预测“下一个状态”——理解一个杯子放在桌边摇摇欲坠,然后判断它下一步可能掉落的物理过程。这,才是AI真正开始“看懂”并“推演”世界的基础。这种从“下一Token预测”到“下一状态预测”的范式跃迁,无疑是Emu3.5最激动人心的核心创新。

庞大身躯与精妙大脑
为了实现这个雄心壮志,Emu3.5可不是随随便便就能练成的。它拥有高达340亿的参数,在超过10万亿Token的海量多模态数据中浸淫。特别值得一提的是,其中视频数据总时长就逼近790年!这简直是给AI灌输了数不清的“世界纪录片”。而它背后那套“大一统”的原生多模态自回归架构,加上将图像生成速度提升近20倍的“离散扩散自适应(DiDA)”技术,以及首次大规模应用的强化学习,都像一个个精妙的齿轮,驱动着这台庞大机器高效运转,让它不仅能学,还能学得又快又好。
AI的“双手”与“眼睛”开始触及真实
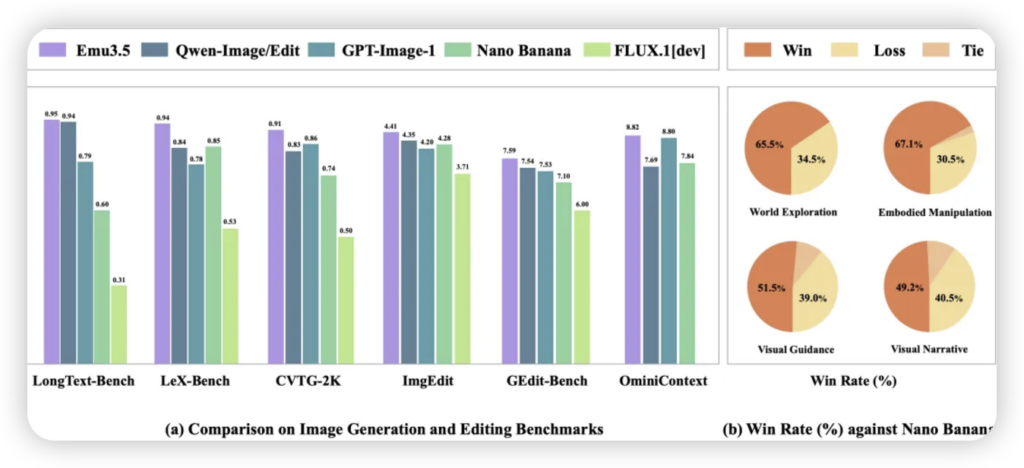
别以为这些技术创新只停留在论文里,Emu3.5已经开始在现实世界中展露拳脚。它的能力覆盖了从高质量的图文/视频生成与编辑,到更深层次的长程视觉叙事推演,乃至跨场景的具身操作与规划。
想象一下,一个机器人不再需要你手把手教,就能理解“叠衣服”指令,并自主规划出详细的动作序列;或者,你只需要给一个主题,它就能生成一段逻辑连贯、物理真实的长程视觉叙事视频。从复杂环境中的机器人操作,到沉浸式内容的自动化创作,甚至预测物理世界的动态变化,Emu3.5正在把科幻电影里的场景一点点变成现实。它能在虚拟世界中漫游,能像人类一样理解空间和物体之间的互动,这无疑为具身智能与机器人领域打开了全新的大门。

开启AGI的新篇章
智源研究院将Emu3.5视为多模态Scaling新范式的开启者,这不仅仅是一个模型的进步,更是AI发展路径上的一个里程碑。它让我们看到了通往通用人工智能(AGI)的又一条清晰可行的道路——一条让AI从单纯的“信息处理者”,升级为“世界理解者与模拟者”的道路。更令人振奋的是,智源宣布将开源Emu3.5,这无疑为全球的AI研究者和开发者们提供了一个强大而开放的基座,去共同探索、去创造更多不可思议的未来。
Emu3.5的出现,让我们离那个AI不仅能对话,更能“感知”、“理解”、甚至“影响”物理世界的未来,又近了一步。这,才是真正让人热血沸腾的地方。

如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站

