你敢相信吗?一个模型只有区区 30亿参数(3B),却能在性能上“碾压”动辄几十上百倍体量的“老大哥”?这就是 MonkeyOCR 带来的震撼!它由华中科技大学与金山办公联合研发,以其惊人的速度和精度,重新定义了我们对轻量级文档解析模型的认知。
⚡️ 性能炸裂:小模型逆袭顶流大模型
最让人跌破眼镜的,是它那看似不起眼的30亿参数。在 英文文档解析任务 中,MonkeyOCR 竟然能把谷歌的 Gemini 2.5 Pro 和阿里的 Qwen2.5-VL-72B 这些顶级“大哥”远远甩在身后!这简直是 AI 领域的“以小博大”经典案例,效率与精度,它做到了双丰收。
而说到速度,MonkeyOCR 更是快到惊人!在多页文档解析中,它能达到 每秒0.84页 的处理速度,这是什么概念?
- 比同类竞品 MinerU 快了近30% (0.65页/秒)
- 更是 Qwen2.5-VL-7B 的七倍多 (0.12页/秒)
想象一下,未来处理海量文档,效率将是质的飞跃!
更别提在复杂内容上的“精雕细琢”:相比 MinerU,MonkeyOCR 在9类中英文文档上平均性能提升 5.1%,尤其在:
- 公式识别 能力上飙升 15%
- 表格识别 也猛增 8.6%
这意味着无论是科研论文还是财报数据,它都能轻松拿捏,大大降低了人工校对的成本和时间。

🧠 幕后魔法:SRR三元组范式
那么,这个“小不点”是如何施展魔法的呢?MonkeyOCR 的秘密武器在于一套独创的 “结构检测-内容识别-关系预测”(SRR)三元组范式:
- 结构检测(Where):首先,它会精准地找出文档中的各个区域块——哪里是文字,哪里是表格,哪里是公式。
- 内容识别(What):接着,再针对性地识别这些区域里的具体内容。
- 关系预测(How):最后,它会聪明地分析这些内容之间的逻辑关系,重构出符合人类阅读习惯的结构化输出。
这套流程巧妙地避开了传统方法的两大痛点:既告别了“流水线”式的错误累积(旧方法往往是 OCR + 布局分析 + NER 多步串联,一步错步步错),也省去了大模型“蛮力”处理整页带来的巨大计算开销。可谓是“四两拨千斤”的智慧之举!
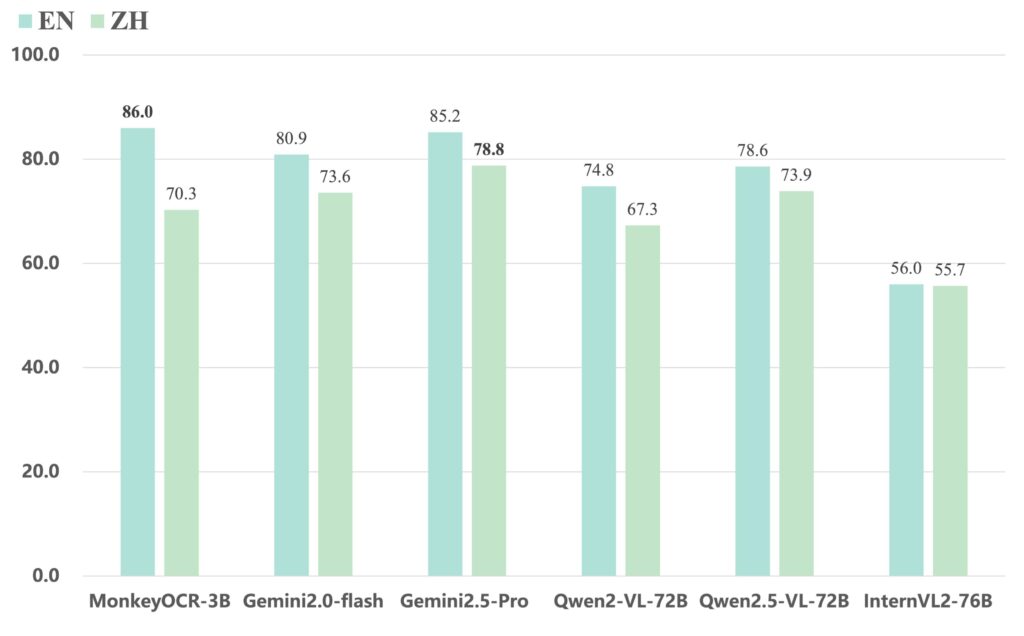
🚀 潜力无限:你的文档自动化利器
别以为性能强悍就意味着高门槛,MonkeyOCR 可是个“平易近人”的实用派。其3B的轻量化模型,意味着 单张NVIDIA 3090显卡就能轻松搞定部署!这意味着它能深入到更多企业级场景的“毛细血管”中。
未来,它有望成为企业级文档自动化的核心引擎:
- 金融/法律:快速解析海量合同、财报、法律文书,极大提升效率。
- 教育:高精度识别试卷、教材中的公式和表格,加速题库数字化。
- 科研:自动化提取论文中的核心图表和数据,助力研究加速。
小贴士:目前 MonkeyOCR 主要擅长处理标准化的电子文档(PDF、扫描件等),对于手机随手拍的“照片文档”(比如歪斜、光线不佳的图片),暂时还没能完全驾驭哦。

💡 触手可及:开源与未来
好消息是,MonkeyOCR 项目不仅性能卓越,更是秉持了开源精神!目前,其 GitHub 代码库和在线 Demo 已经开放,让更多开发者能够亲身体验并参与进来。
- GitHub 代码库:https://github.com/Yuliang-Liu/MonkeyOCR
- 在线 Demo:https://huggingface.co/spaces/Yuliang-Liu/Monkey
- 论文地址:https://arxiv.org/abs/2506.05218 (注意:论文地址可能随版本更新而变动,请以官方发布为准)
总而言之,MonkeyOCR 的出现,无疑是文档智能领域的一次里程碑式突破。它用事实证明:在AI的赛道上,“小而美”也能爆发出震撼全球的能量。对于所有关注文档自动化、希望将AI能力落地的开发者和企业来说,MonkeyOCR 绝对是一个不容错过的选择!
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论