哈喽各位AI圈的朋友们!最近这大模型圈子真是卷得停不下来,动不动就是千亿、万亿参数的大块头。但今天咱们要聊的这位主角,字节跳动 Seed 团队新发布的 Seed-Coder-8B,虽然参数只有80亿,在代码生成这个领域却像匹黑马一样冲了出来,而且TA的“成长方式”还特别有意思!
别看个头不大,Seed-Coder-8B 在代码能力上可是相当能打,甚至在不少榜单上超越了一些体量更大的选手。而它背后的独门绝技,据团队自己透露,是打破了传统AI训练中那个又苦又累的环节——“模型中心化”的数据管理。简单来说,就是不再过度依赖人工制定规则去筛选和清洗海量训练数据,而是让AI自己去学习、去判断哪些数据质量高,哪些是“营养不良”的垃圾代码。是不是有点“让AI自己挑食,喂出个天才”的意思?
告别“人工洗数据”,让AI自我管理训练营养库
我们都知道,大模型的训练效果很大程度上取决于喂给它的数据质量。特别是代码模型,网上代码千千万,优劣参差不齐,怎么高效、准确地从中挑出高质量的代码、提交记录、文档来训练模型,一直是个巨大的挑战,也是一个耗费大量人力和时间的活儿。
字节跳动 Seed 团队这次放出的 Seed-Coder-8B,最亮眼的地方就在这儿了。他们公开分享了一套“模型中心化”的数据流水线。想象一下,他们不是雇一堆人去写复杂的规则、脚本来过滤GitHub数据,而是训练了一个专门负责给代码打分、筛选的大模型!这个“评分模型”能从可读性、模块化、清晰度、可复用性等多个维度去评估一段代码的价值,然后把那些低质量的、重复的数据过滤掉,只留下那些“黄金营养”。
官方数据显示,Seed-Coder-8B-Base 版本是在高达 6万亿 token 的代码数据上预训练的。这海量的数据,配合这种高效、智能的“自我管理”方式,最大限度地减少了预训练数据构建中的人力投入,同时提升了数据质量,这才让80亿参数的小模型也能拥有如此强大的能力。

Seed-Coder-8B 家族:各有绝活,任君挑选
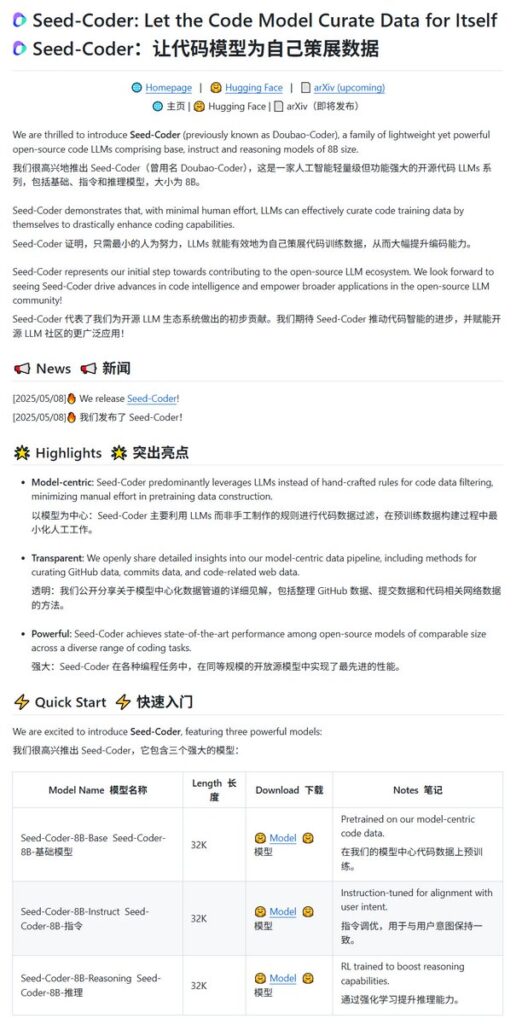
Seed-Coder 系列可不是单打独斗,这次一共推出了三款主力变体,都已经在 Hugging Face 上开源了,而且是友好的 MIT 许可证,学术研究、商业落地都能用!
- Seed-Coder-8B-Base: 基础预训练模型,是整个家族的底子。在大规模代码数据上打磨,特别擅长代码补全和代码填充(Fill-in-the-Middle, FIM)——就是那种你写了一段代码的前半部分和后半部分,中间空着,模型能帮你把中间缺失的逻辑补全,非常实用!
- Seed-Coder-8B-Instruct: 指令微调模型,是在 Base 模型基础上,通过在公开数据集和字节跳动自己生成的数据上进行精细调教。这个版本更听得懂“人话”,能更好地对齐你的指令,比如让你写个函数、修改一段代码、解释代码逻辑等等,是日常开发的好帮手。
- Seed-Coder-8B-Reasoning: 推理能力增强模型。这个版本特别针对复杂代码问题和算法题进行了强化训练(甚至用了强化学习RL),旨在提升模型在解决有挑战性的编程问题时的逻辑推理能力和多步骤规划能力。在一些算法竞赛模拟测试中表现亮眼。

小身板,大能量:实测数据说话
Seed-Coder-8B 家族不仅有创新的数据管理,性能也是实打实的强。要知道,80亿参数的模型,相比那些几百上千亿参数的模型,部署和运行成本要低得多,更有希望在消费级硬件甚至本地环境运行。而 Seed-Coder-8B 在这个参数量级下,表现达到了开源模型的顶尖水平(SOTA)。
看看官方放出的几组数据(注意这些通常是Instruct或Reasoning版本在对应任务上的成绩):
- HumanEval: 77.4 (代码生成基准,这个分数在8B级别里相当炸裂!)
- MBPP (Mostly Basic Python Problems): 82.0 (另一个Python编程问题基准,表现依旧优秀)
- MultiPL-E: 67.6 (评估模型生成多种语言代码的能力,覆盖语言多)
- SWE-bench / Multi-SWE-bench: 在软件工程实战任务(比如自动修复bug)和多语言代码修复基准上,Seed-Coder-8B 也展现了很强的能力,修复率超过了一些更大参数的模型。
- IOI (国际信息学奥林匹克竞赛) / Codeforces: Reasoning 版本在这些算法竞赛模拟测试中,成绩甚至超越了一些30B+参数的模型,Codeforces 评分达到了约 1553,接近人类铜奖水平!
而且,它们都支持高达 32,768 个 token 的上下文长度,这意味着模型能一次性“看”更多的代码,理解项目级的依赖和逻辑,这对于复杂的代码生成和修改任务至关重要。

字节跳动AI生态的新成员
Seed-Coder 来自字节跳动的“ByteDance Seed”团队,这个团队是字节跳动AI基础模型研发的主力军,“豆包大模型”家族的一员。Seed-Coder 可以说是豆包家族在代码领域的专项突破。他们之前也贡献了不少好东西,比如 Multi-SWE-bench 这个多语言代码修复基准,还有 SandboxFusion 这样的代码沙箱执行工具。这次开源 Seed-Coder-8B,进一步巩固了字节跳动在AI基础研究和开源贡献上的地位。
社区反响与未来期待
Seed-Coder-8B 的发布在开发者社区引起了不少关注,大家对它的性能表现、尤其是那个“模型中心化”的数据管理方法非常感兴趣。作为一个小巧但强大的开源模型,它在本地化部署、低成本AI代码助手等场景有着巨大的潜力。
当然,社区也在期待更详细的技术报告(团队提到了即将发布arXiv论文),希望能看到更多关于模型架构、训练细节、数据处理方法的深入阐述,以及与其他主流代码模型(比如CodeLlama, DeepSeek Coder, Qwen Code等)在更多维度、更多编程语言上的详细对比评测。独立的第三方评测数据出来后, Seed-Coder-8B 的真实实力和价值将更加清晰。
总的来说,字节跳动这波操作,用一个80亿参数的小模型,凭借创新的数据管理思路和优异的性能,在竞争激烈的代码大模型领域杀出了一条路。它不仅提供了一个高性能、易于部署的开源工具,也为未来AI模型的训练范式提供了新的启发。 Seed-Coder-8B 的故事,也许正是“小而美,巧而强”在AI时代的又一个精彩注脚。
接下来就看社区的反馈和更深入的评测了,说不定 Seed-Coder-8B 很快就会成为你代码编辑器里的得力助手呢!一起期待吧!
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论