嘿,各位AI圈的朋友们,最近的大模型世界可真是精彩纷呈,让人应接不暇!每一次技术迭代,都像是在向我们展示未来智能的又一块拼图。今天,我想和大家聊聊两股近期搅动风云的力量:阿里通义千问Qwen3-Max的“深度思考”模式,以及月之暗面Kimi Linear带来的长程记忆突破。它们一个向内深挖,一个向外拓宽,共同为我们描绘了一个更强大、更高效的AI新时代。
通义千问Qwen3-Max:当大模型开始“深度思考”
想象一下,当你抛出一个复杂问题,AI不再只是机械地给出答案,而是能像一个经验丰富的侦探,一步步剖析线索,抽丝剥茧,最终给出严谨的结论。这正是阿里通义千问Qwen3-Max最新上线的“深度思考”模式所试图实现的目标。
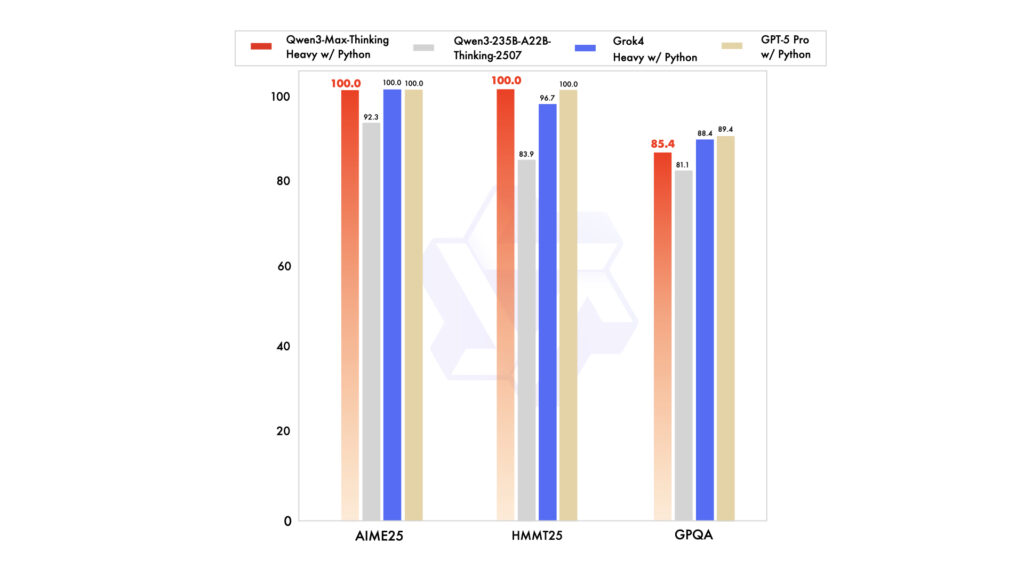
作为通义团队迄今为止规模最大、能力最强的旗舰模型,Qwen3-Max以其超万亿参数和36T tokens的惊人预训练数据量,奠定了深厚的基础。而这次的“深度思考”模式,就像是给这艘巨型航母安装了更强大的导航系统。它强化了推理链分析和多步骤问题拆解能力,尤其在处理逻辑严谨、步骤繁琐的复杂任务时,表现出前所未有的稳健性。
通义团队透露的数据更是令人振奋:结合了外部工具的Qwen3-Max-Thinking版本,在AIME 25、HMMT这类高难度数学推理基准测试中,竟然取得了100%的准确率!这可不是随随便便就能达成的成就,它意味着模型不再只是“懂”知识,更能“用”知识进行深层次的逻辑推演。未来,无论是复杂的编程任务、跨文档推理,还是智能体的多步骤计划,我们都能期待Qwen3-Max带来更可靠、更智能的解决方案。
月之暗面Kimi Linear:突破长文瓶颈,记忆无限延伸
如果说通义千问是让AI“想得更深”,那么月之暗面的Kimi Linear,则是让AI“记得更久,看得更远”。在长文本处理领域,这可一直是个老大难问题,传统模型往往效率低下,甚至难以处理百万量级的文本。而Kimi Linear的出现,无疑是投下了一颗重磅炸弹。
它最核心的创新在于其混合线性注意力架构。这是一个巧妙的设计,不再是简单粗暴地堆叠,而是采用“3层Kimi Delta Attention(KDA)线性注意力层 + 1层全注意力层(MLA)”的交错设计。KDA负责高效处理局部信息,而MLA则作为全局信息的枢纽,弥补了线性注意力在长距离精细检索上的不足。这种设计,就像是给AI的大脑既配置了高效的“局部缓存”,又保留了强大的“全局检索器”,从而在性能和效率之间取得了完美平衡。
Kimi Linear在测试中的表现堪称惊艳:不仅在短上下文任务上超越了传统全注意力模型,更在处理128k甚至百万级(1M)token的长文本时,展现出卓越的长程依赖建模能力。最让人眼前一亮的是其效率提升:KV缓存减少高达75%,解码吞吐量提升约6.3倍!这意味着未来AI处理海量法律合同、学术论文,或者作为需要超长记忆的高级智能体时,将变得更加流畅和可行。更棒的是,月之暗面已经开源了核心代码和模型权重,并且得到了vLLM这样的高性能推理框架的迅速支持,这无疑会加速其在业界的应用落地。
展望:智能双核驱动的AI未来
Qwen3-Max的“深度思考”与Kimi Linear的“长程记忆”,就像是AI发展的两大核心引擎,分别在“理解深度”和“信息广度”上做出了开创性的贡献。
一个让AI能更严谨地思考,处理那些需要层层推理才能解决的难题;另一个则让AI能够无惧信息洪流,在海量数据中轻松捕捉并利用关键信息。这两项技术的进步,无疑将共同推动大模型向着更通用、更智能、更高效的AGI(通用人工智能)目标迈进。我们有理由相信,在它们的共同驱动下,未来的AI智能体将不再是简单的聊天工具,而是真正能够理解世界、解决复杂问题的强大伙伴。这个由深度思考和长程记忆共同塑造的AI新篇章,正缓缓拉开序幕,让我们拭目以待。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站

