做过文档解析的开发者都有过这种绝望时刻:面对一份排版复杂的PDF或一张字迹潦草的报销单,传统OCR只会给你吐出一堆乱序的字符,而动用GPT-4V这种通用大模型又像是“大炮打蚊子”——既烧钱又慢得让人心焦。
就在2026年2月3日,智谱AI甩出了一个让开源社区炸锅的项目——GLM-OCR。这款模型最让人惊讶的不是它能做什么,而是它“怎么做到的”。
它只有0.9B(90亿)参数。
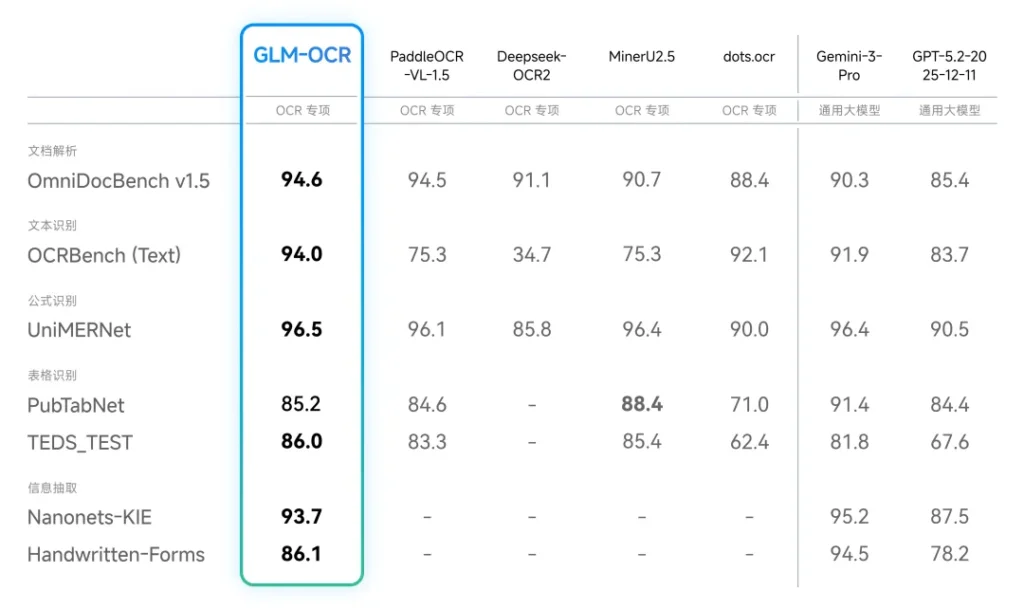
在动辄千亿参数的大模型时代,0.9B听起来像是玩具。但正是这个“小个子”,在权威的OmniDocBench V1.5榜单上拿下了94.6分,一举登顶,甚至在部分能力上贴脸输出了谷歌的Gemini-3-Pro。
今天我们就来扒一扒,这个号称“小尺寸、高精度”的开源模型,到底是不是文档处理领域的“版本答案”。
拒绝臃肿,只要精度
在AI圈子里,我们习惯了用堆参数来换智能。但GLM-OCR走了一条反直觉的路:极致的轻量化。
0.9B参数意味着什么?意味着它的模型体积只有约2.65GB。你不需要昂贵的H100集群,甚至在边缘设备上也能跑得飞起。智谱并没有因为体积小就牺牲性能,反而通过自研的CogViT视觉编码器和GLM-0.5B解码器架构,把技能点全加在了“视觉理解”上。
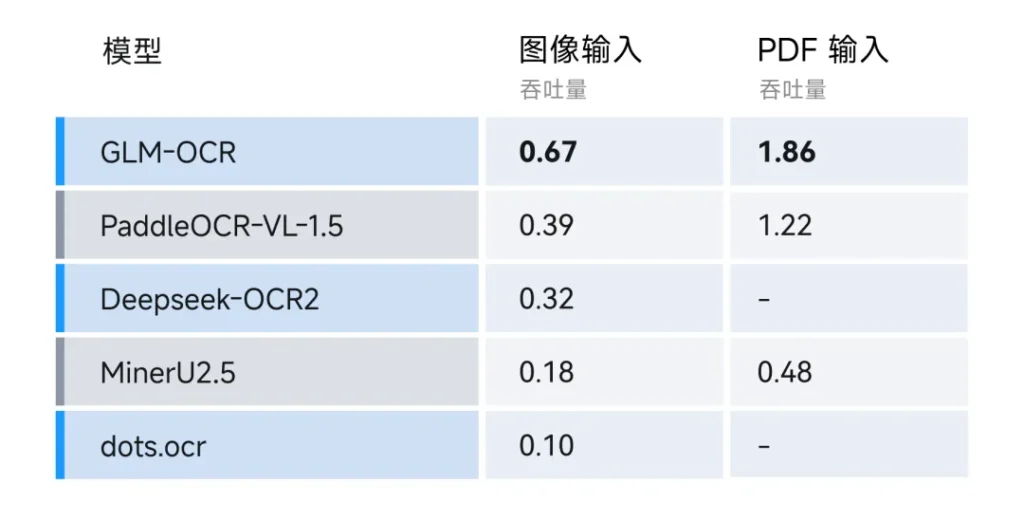
数据不会撒谎。在单副本单并发的情况下,它处理PDF的速度达到了每秒1.86页,图片处理达到每秒0.67张。相比同类竞品(比如PaddleOCR),吞吐量提升了近50%。简单说,它不仅看得准,而且读得快。
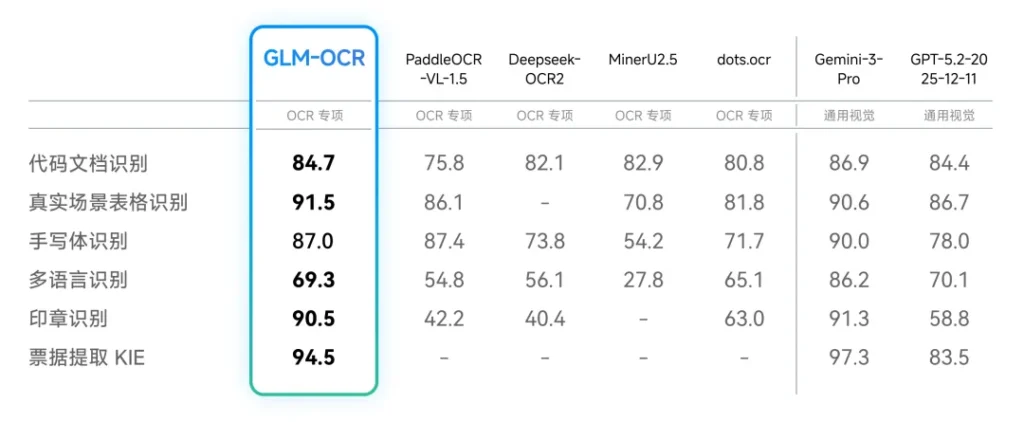
专治各种“排版噩梦”
传统OCR最怕什么?怕表格,怕公式,怕中英文混排,更怕财务大姐那龙飞凤舞的手写发票。
GLM-OCR显然是盯着这些痛点训练的。它不仅仅是识别文字,更是在“理解结构”。
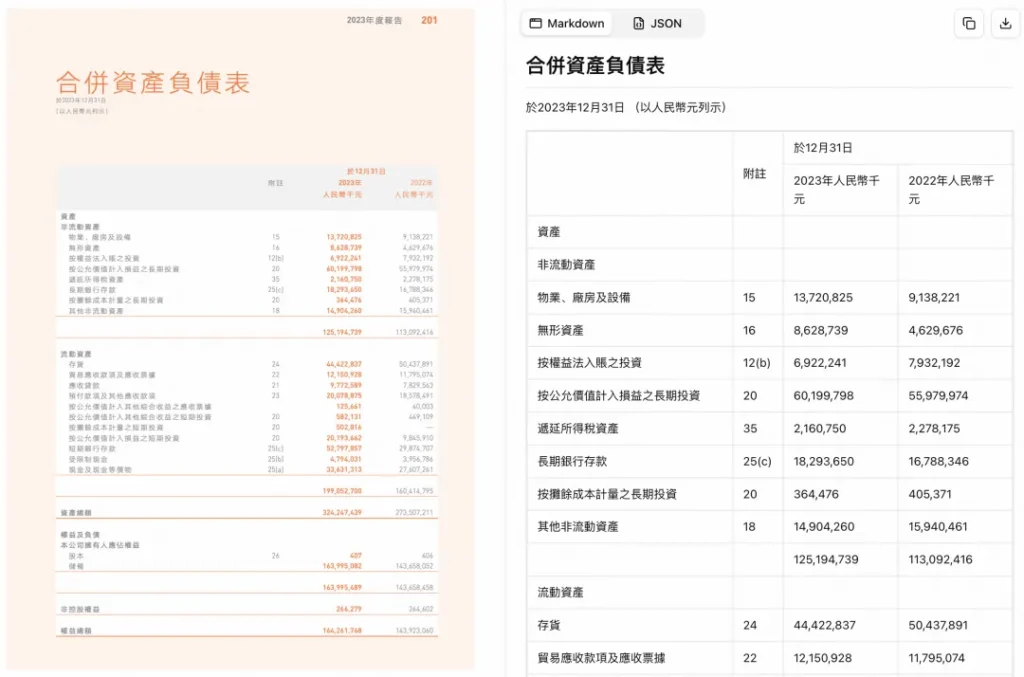
搞定复杂表格: 不需要后期再写一堆正则代码去拼凑表格,GLM-OCR能直接输出标准的HTML代码或Markdown。合并单元格、多层表头、跨页表格,它都能还原得整整齐齐,直接省去了二次制表的繁琐。
死磕高难场景: 针对手写体、印章遮挡、代码文档以及那种让人头大的多栏混排,智谱进行了全任务强化学习训练。实测显示,它能从票据和卡证中精准提取关键字段,并输出干净的JSON格式。这对于金融、保险和物流行业的自动化流程来说,简直是救命稻草。
把价格打下来的“实用主义”
技术再好,太贵也是白搭。GLM-OCR这次的定价策略非常激进,甚至可以说是“甚至不想赚你钱”。
API调用成本仅为0.2元/百万Tokens。
这是什么概念?大约1块钱就能处理2000张A4扫描图片,或者200份10页的PDF文档。相比传统OCR方案,成本直接砍到了十分之一。对于那些甚至还在犹豫要不要上AI的企业来说,这个价格门槛几乎被抹平了。
而且,它对部署环境极度友好。不仅支持vLLM、SGLang、Ollama这些主流推理框架,还完成了对国产算力(如沐曦GPU)的Day 0适配。无论是想在云端薅羊毛,还是想私有化部署保隐私,路都给你铺好了。
写在最后
GLM-OCR的出现,某种意义上是在给当下的AI热潮降温——它提醒我们,不是所有问题都需要万亿参数的“超级大脑”来解决。在文档解析这个垂直领域,一个设计精良、专注于结构化输出的轻量级模型,往往能带来更高的工程价值。
目前,项目代码和模型权重已经全量开源至GitHub和Hugging Face。如果你正被文档解析的烂摊子搞得焦头烂额,不妨试试这个0.9B的“小钢炮”,它可能会给你带来久违的清爽感。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


