2025年6月30日,华为在人工智能领域投下了一枚重磅炸弹,正式宣布首次大规模开源其核心底牌——盘古大模型系列。这并非一次简单的模型分享,而是一套包含了两款重磅模型及全套昇腾硬件推理技术的“组合拳”,旨在为全球开发者构建一个从芯片到应用的完整AI生态。
“航母级”选手:盘古 Pro MoE 72B
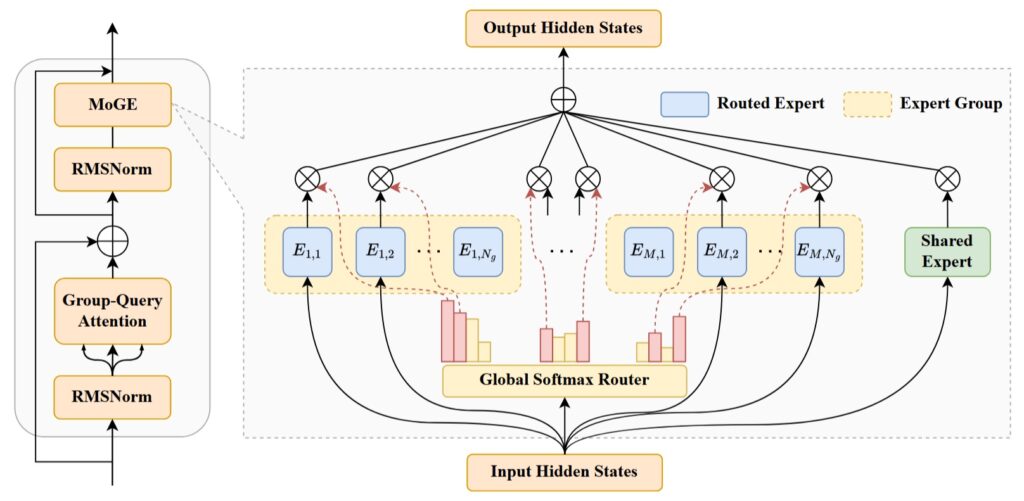
首先登场的是“航母级”选手——拥有720亿总参数的盘古 Pro MoE 模型。它没有简单地堆砌参数,而是独创了MoGE(分组混合专家)架构。
你可以把它想象成一个拥有众多顶尖专家的智囊团。传统方式是任务来了大家一起上,容易造成忙的忙死、闲的闲死。而MoGE则聪明地将专家们分成了不同的小组,任务来了先分配到小组,再由小组内的专家协同解决,确保了计算资源的负载均衡。
这种设计的巧妙之处在于,每次处理任务时,仅需激活约160亿参数,却能爆发出远超同级模型的能量。在华为自家的昇腾800I A2芯片上,它的推理速度飙到惊人的1148 tokens/s,通过技术加速更能冲到1528 tokens/s,真正实现了“以小博大”的超高效率。目前,这款模型的权重和配套的推理代码已在GitCode平台开放。
灵活的“特种兵”:盘古 7B
如果说72B模型是重装旗舰,那么70亿参数的盘古7B模型就是一名灵活善战的“特种兵”。它最大的亮点是具备“快思考”与“慢思考”双系统框架。
- 快思考:处理日常、简单的任务,追求极致的响应速度。
- 慢思考:当遇到复杂的推理难题时,它会自动切换到该模式,进行深度分析,确保结果的准确性。
这种自适应能力让它在AIME、GPQA等高难度推理测试中,表现超越了Qwen3-8B等同规模的对手。更重要的是,它对边缘设备极为友好,非常适合部署在算力有限的终端上,让AI能力深入到工厂、汽车、医疗设备等各个角落。这款模型也即将开放下载。

真正的底牌:软硬协同的昇腾生态
这次开源的核心,远不止模型本身。华为同步开放了基于昇腾(Ascend)硬件的全套大规模模型推理技术。
这套工具链包含了从底层通信优化(FlashComm)、量化压缩(OptiQuant)到负载均衡算法(OmniPlacement)等一系列“独门秘籍”。正是这些技术,才将盘古模型的潜力在昇腾芯片上压榨到了极致。
华为此举意图明确:通过开放最高性能的模型和最高效的工具,吸引全球开发者在昇腾硬件上进行创新。这不仅是技术自信的体现,更是构建国产AI全栈体系、从“算力追随者”向“架构定义者”转变的关键一步。
总而言之,华为这次开源,为开发者同时送上了“顶级跑车”(盘古模型)和“无限油料的高速公路”(昇腾生态),无疑将极大降低AI应用的门槛,加速整个行业的创新浪潮。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论