当所有人的目光都还聚焦在“谁家模型参数更多、体量更大”的军备竞赛时,阿里通义千问团队却悄悄换了个赛道,扔出了一颗重磅炸弹:Qwen3-4B-2507系列。
你没看错,参数只有4B。在动辄千亿万亿的时代,这听起来像个“弟弟”。但请收起你的轻视,因为这个小家伙,正在用一种近乎蛮横的方式,重新定义我们对“性能”与“尺寸”的认知。

这不是升级,是“降维打击”
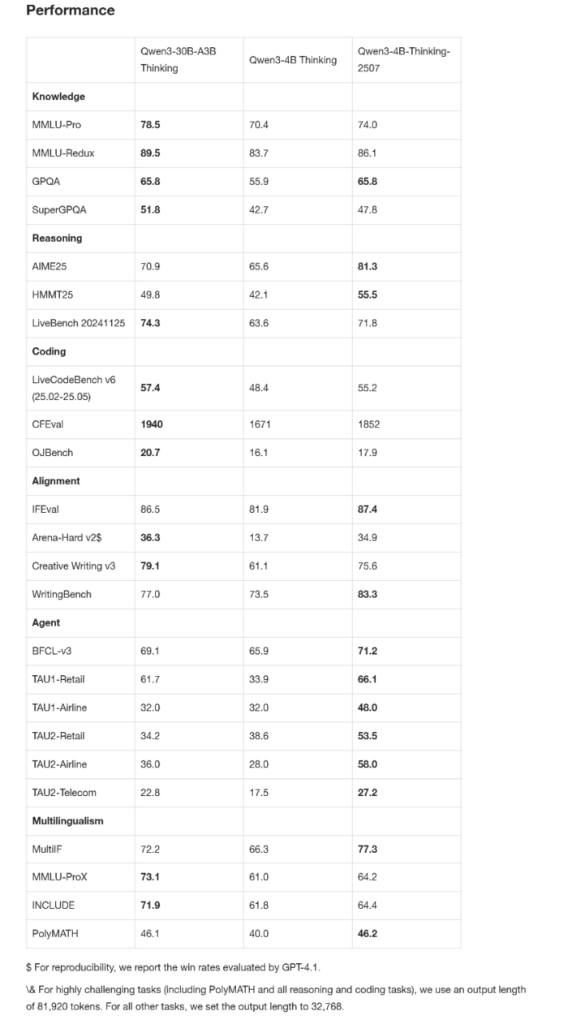
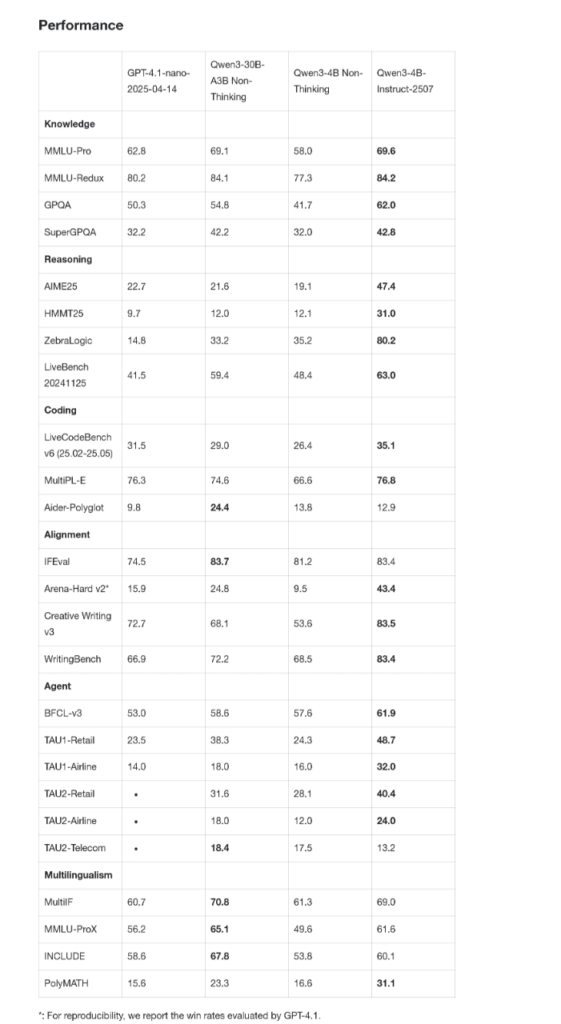
我们先不谈那些复杂的术语,直接上战绩。
过去,小模型总被认为是“智商阉割版”,能聊天就不错了。但这次的Qwen3-4B,尤其是它的“思考增强版”(Thinking-2507),在公认高难度的数学评测AIME25上,拿下了81.3分。这是什么概念?这个分数已经能和许多30B甚至更大规模的模型平起平坐。它就像一个轻量级拳手,一拳KO了重量级选手。
而在大家更关心的通用能力上,它的“指令执行版”(Instruct-2507)更是直接“点名”了闭源小模型标杆GPT-4.1-nano,并实现了全面超越。
这已经不是简单的性能提升了,这几乎是在说:“在4B这个量级,我就是规则。”

真正的魔法:当AI跑在你的iPhone上
性能爆表固然惊艳,但Qwen3-4B最可怕的,是它的“亲民”。
官方数据显示,经过INT8量化后,它的显存占用仅需2GB。
这意味着什么?意味着它不再是数据中心里吞电的巨兽,而是可以安安静静躺在你手机、树莓派,甚至更低功耗物联网设备里的智能核心。开发者社区已经有人在iPhone和旧款安卓手机上成功运行,速度流畅。
想象一下:一个不需要联网、能在本地运行的AI助手,帮你实时翻译、规划行程、分析表格;一个能处理256K上下文(相当于40万汉字)的阅读器,随时帮你总结厚厚的法律文件或学术论文。这一切,都可以在你的掌上设备实现。
这才是真正的“AI for Everyone”,将高端AI能力从云端解放,赋予了每一个普通设备。
快思慢想,它比你更懂“思考”的节奏
另一个让人拍案叫绝的设计,是它的动态推理模式。
简单来说,模型懂得“看情况办事”。当你需要快速得到答案时,它启用“快思考”模式,响应迅捷;当遇到需要严密逻辑的复杂任务(比如工具调用或代码生成),它会自动切换到“慢思考”模式,进行深度推理,确保结果的准确性。
这种设计,完美平衡了效率与质量,让小模型拥有了堪比大模型的“智慧”与“情商”。
写在最后:一个时代的开启
Qwen3-4B-2507的出现,可能比发布一个万亿参数模型更具里程碑意义。它证明了极致的优化和巧妙的架构,完全可以弥补参数量的差距。
更重要的是,它完全开源(Apache 2.0),允许商用。
这意味着从独立开发者到中小企业,都能以极低的成本,构建出过去不敢想的、运行在终端设备上的强大AI应用。一个去中心化、AI无处不在的时代,似乎真的要来了。
所以,别再只盯着云端的庞然大物了。真正的革命,或许就源自这些小而精悍、能被装进口袋的“性能怪兽”。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论