大语言模型(LLM)的能力提升,似乎一直在遵循一条“越大越好”的定律——参数量越多,模型在各种任务上表现越强。然而,“大”模型带来了巨大的计算和显存开销,让许多研究者和开发者望而却步。近期,Qwen团队提出了一个令人耳目一新的解决方案:ParScale,它另辟蹊径,通过创新的“并行推理”方法,在不显著增加模型参数的情况下,显著提升模型性能。
ParScale:一种全新的扩展范式
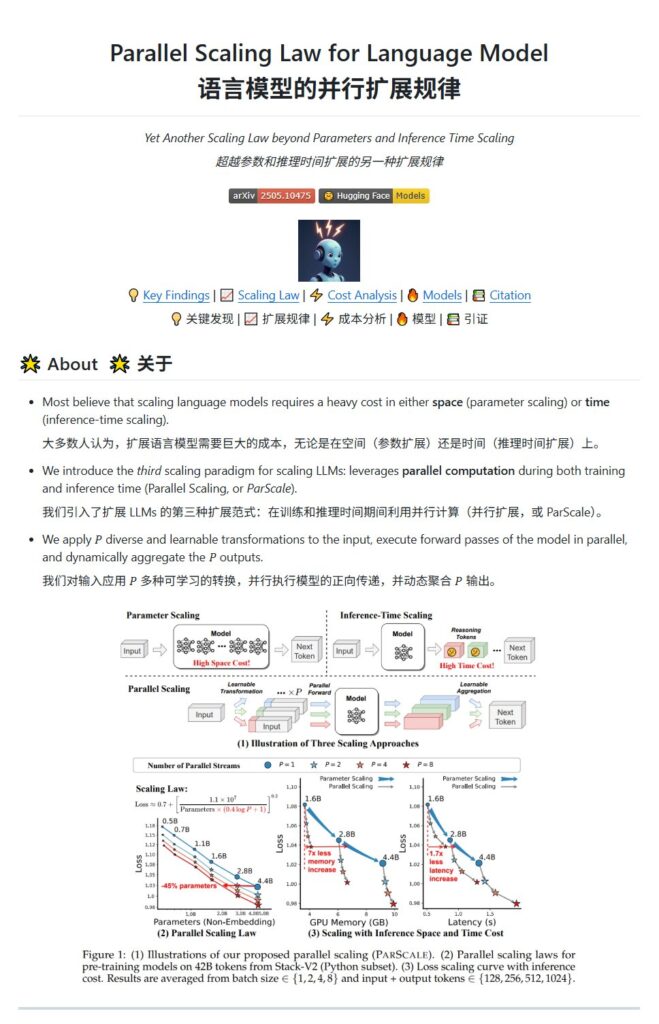
传统上,提升模型能力主要依靠两种方式:一是增加参数量(模型变大),二是增加推理计算深度(比如多次迭代或思维链)。ParScale则引入了“第三种扩展范式”——并行计算扩展。它不是简单地把模型做得更大,而是通过在模型内部运行多个“并行推理流”,并将它们的结果巧妙地结合起来,从而模拟出更大模型的强大能力。
这项技术的名称“ParScale”就直接体现了其核心思想:Parallel Scaling,即并行扩展。
“P”的秘密:并行推理流
ParScale模型名称中的P(例如ParScale-1.8B-P8)代表了模型在推理时启动的并行推理流(Parallel Streams)数量。P=1代表传统的单流推理(即基线模型),而P=8则意味着模型同时运行8个并行的计算路径。
那么,这8个并行流是简单地对同一个输入进行8次重复计算吗?当然不是。ParScale的核心创新在于:
- 差异化输入变换: 在将输入送入模型之前,ParScale会对输入应用P种不同的、可学习的变换。这些变换可以是给输入附加独特的学习前缀,或者对输入表示进行微调。这样一来,每个并行流接收到的输入版本都是略有差异的,这使得各流能够从输入中提取出不同的、互补的信息。
- 共享参数并行计算: P个经过差异化变换的输入随后会并行地通过共享的核心模型参数进行前向计算。这意味着你不需要P个独立的大模型,而是只有一个基础模型,其参数被所有并行流复用。这大大节省了参数存储所需的显存。
- 动态聚合输出: 每个并行流都会产生一个输出结果。ParScale会使用一个动态聚合机制(例如基于MLP计算权重的加权求和或注意力融合)来智能地合并这P个输出,生成最终的增强结果。这个聚合过程是动态可学习的,能够根据当前输入和各流输出的特点,最优地整合信息。
整个过程就像是让多个具备不同视角(通过差异化变换获得)的专家(共享同一大脑,即核心模型参数)同时思考同一个问题,然后通过一个智能仲裁者(动态聚合机制)综合他们的意见得出最终结论。

O(log P)扩展定律:并行计算的威力
Qwen团队通过理论研究和大规模实验发现了一个令人振奋的新扩展定律:使用P个并行流进行推理,其效果近似于将模型的参数数量增加了 O(log P) 倍。
这个定律非常重要。log P是一个增长比较缓慢的函数(例如,P=8时,log₂8=3)。这意味着,通过并行计算带来的性能提升,可以在参数量只做对数级别“等效增加”的情况下实现。例如,Qwen团队的论文中推测(并有数据支撑),一个30B参数的模型,如果运行8个并行流(P=8),其效果可以媲美一个42.5B参数的传统模型。虽然从30B到42.5B参数量增加并不巨大,但在更大模型尺度下,这个相对增益会更加可观。从另一个角度看,为了达到42.5B模型的性能,你可能只需要一个30B的基础模型加上ParScale的P8并行能力,这比直接训练和部署一个42.5B模型要高效得多。
性能验证与权衡
Qwen团队在1.8B参数的ParScale系列模型(P1到P8)以及更大规模模型上进行了广泛测试。结果表明,ParScale方法在多项基准测试中取得了显著性能提升,尤其在数学推理(如GSM8K,P8相比P1提升约34%)和综合知识(如MMLU,P8相比P1提升约23%)等需要深度理解和推理的任务上表现突出。
ParScale的优势在于其效率提升:与通过直接增加参数达到同等性能的方法相比,ParScale在内存增加量上可减少高达22倍,延迟增加量可减少高达6倍(在batch size=1时)。此外,它支持动态调整P值,并可通过两阶段训练策略降低训练成本。
然而,任何技术都有权衡。ParScale引入并行流确实会增加总的计算量(每个token生成需要进行P次前向计算)和激活值所需的显存(虽然参数显存共享,但激活值需要存储P份)。这使得模型对GPU的计算能力和显存带宽提出了更高的要求。在显存带宽相对有限的消费级显卡上,其推理速度可能相比P=1基线模型有所下降;而在拥有高带宽和强计算能力的专业卡(如H100)上,这种影响则小得多。
总结与展望
Qwen的ParScale技术为大语言模型的扩展提供了一个全新的、计算驱动的维度。它打破了模型能力提升主要依赖参数量增长的传统思维,展示了通过并行计算也能有效增强模型智能的可能性。尤其对于资源有限的场景,ParScale提供了一种在控制参数量和显存成本的同时,提升模型性能的新路径。
虽然带来了计算和带宽的新要求,ParScale无疑是模型效率研究领域的一大创新。它提示我们,未来AI模型的发展,可能不仅仅是“更大”的比拼,更是如何在现有或有限硬件资源下,通过更智能的架构和计算方法,释放模型的更大潜力。ParScale的理念和实践,有望推动大模型向着更高效、更灵活、更易于部署的方向发展。
相关模型(如ParScale-1.8B系列)和代码已在Hugging Face和GitHub上开源,供社区研究和使用。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论