朋友们,AI圈又地震了!但这次,不是谁家又砸了百亿参数搞出个“性能怪兽”,而是腾讯悄悄放出了一个“效率刺客”——混元-A13B。
当我看到它的部署要求时,我揉了揉眼睛,以为自己看错了:最低仅需一张RTX 3090就能跑起来! 🤯
是的,你没听错。那个我们以为只有在大型数据中心才能一窥究竟的千亿级大模型技术,现在,可能就要在你家的台式机里安家了。这已经不是“技术普惠”了,这简直是把AI的“王座”直接搬到了大众面前!

🧠 大脑很“大”,干活却很“省”:MoE架构的魔法
首先,别被“A13B”这个名字骗了。它的全称是Hunyuan-Agents-13B,但它的“大脑”总容量高达800亿参数。那13B又是怎么回事?
这就是它最核心的魔法——混合专家系统(MoE)架构。
你可以把它想象成一个顶级的专家顾问团。当你问一个关于“写代码”的问题时,模型不会让所有800个专家(总参数)都挤在一起七嘴八舌,而是只唤醒最擅长编程、算法的那13个专家(激活参数)来为你服务。

结果就是: 你享受到了千亿级模型的智慧,却只付出了百亿级模型的计算开销。性能拉满,能耗暴降,腾讯这手“四两拨千斤”玩得实在漂亮!
🚀 不止于省,它还有“快慢脑”双核驱动
如果说MoE架构是它的省钱天赋,那“动态推理模式”就是它的秘密武器。混元-A13B内置了两种思考模式:
- ⚡ 快思考模式: 像你的直觉。处理“今天天气怎么样?”、“帮我写首五言绝句”这类简单任务,秒速响应,干净利落。
- 🐌 慢思考模式: 像深思熟虑的推理。当你抛出“分析这份财报并给出投资建议”这种复杂指令时,只需加上
think触发词,它就会启动反思、回溯等深度计算,一步步拆解问题,给出逻辑严谨的答案。
这种设计,让模型既有“闪电侠”的速度,又有“福尔摩斯”的头脑,懂得把算力花在刀刃上。
🛠️ 性能怪兽:不光能聊,还能干活!
光说不练假把式。混元-A13B的实战能力也让人印象深刻:
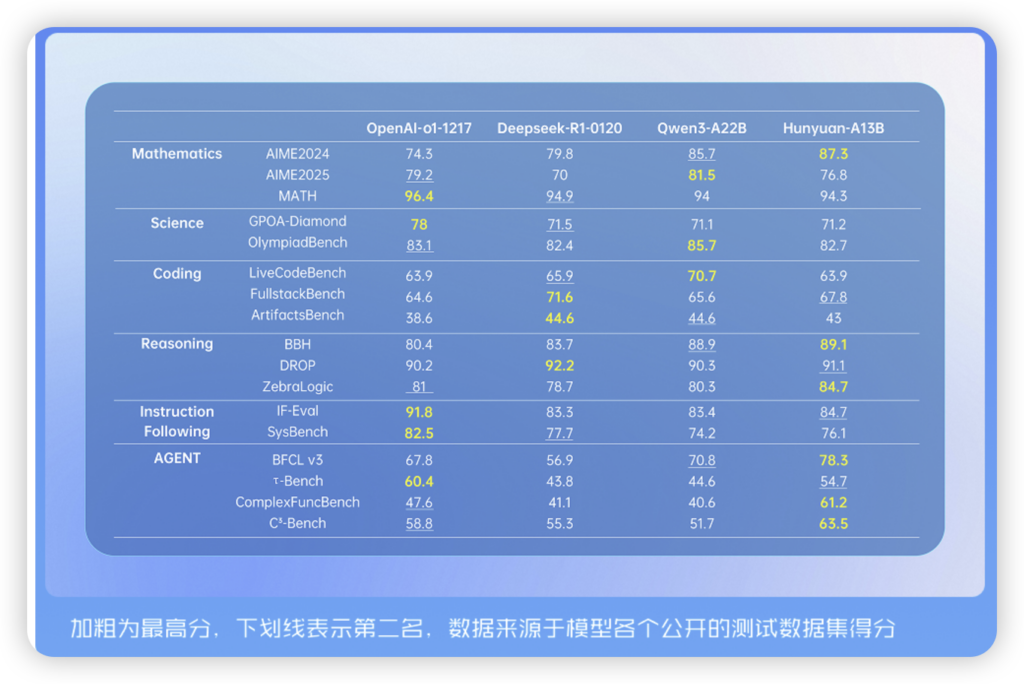
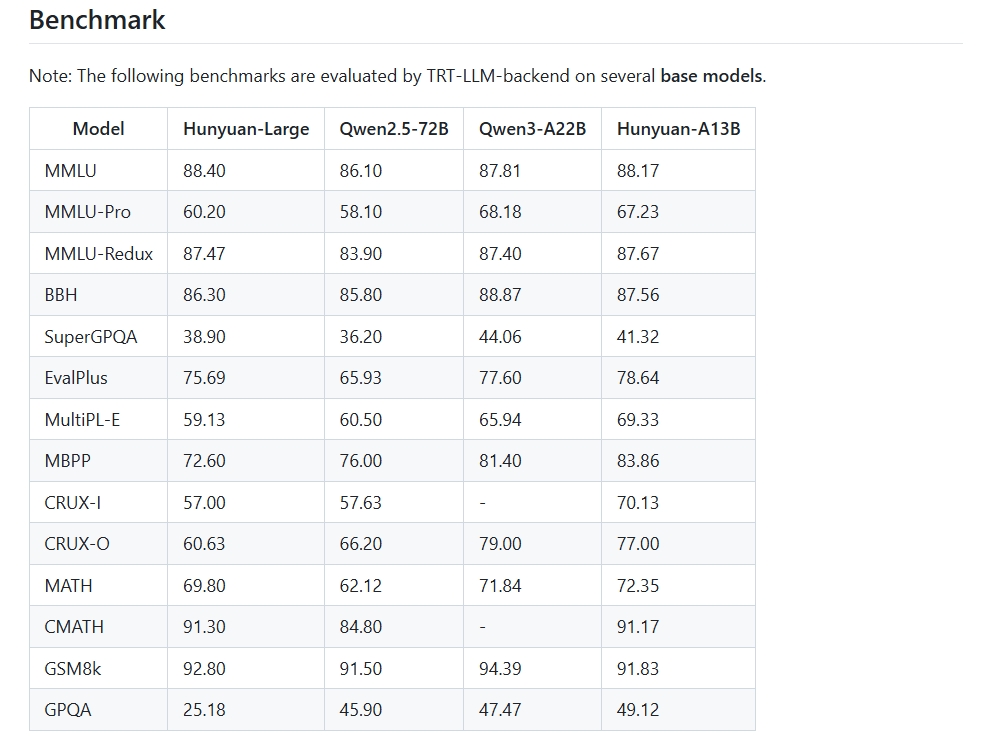
- 超长记忆力: 原生支持256K上下文窗口!这意味着你可以把一本厚厚的书、一份超长的财报直接丢给它,它能从头看到尾,不忘事、不跑偏。在长文理解测试里,它几乎是仅次于Gemini 2.5 Pro的存在。
- 最强打工人(Agent): 它的工具调用能力在业内评测中拿了第一。什么意思?就是你对它说:“帮我规划一个五天四夜的成都旅行攻略,要包含景点、美食和住宿预估。” 它能自己去调用地图、天气、酒店预订等工具,然后给你生成一份完整的、可执行的方案。
- 基准测试屠榜: 在数学、科学、逻辑等硬核推理任务上,它甚至超越了DeepSeek-R1、Qwen3-A22B等一众强敌。
🌍 这次,腾讯要和所有开发者交个朋友
最关键的一点来了:它开源了!
- 代码、模型权重全部上架GitHub和Hugging Face。
- 配套开源了两大“考官”级评测集:ArtifactsBench(代码能力)和C3-Bench(Agent能力),大家可以公开、公平地检验它的实力。
- 部署门槛极低,个人开发者、小团队都能轻松“上车”,在自己的设备上玩转高性能AI。
我的看法
混元-A13B的发布,可能预示着一个新时代的到来。大模型竞赛不再仅仅是参数量的“军备竞赛”,更是效率和应用落地的较量。它用事实证明,高性能AI不必永远“高高在上”,也可以飞入寻常百姓家。
对于我们这些AI爱好者和开发者来说,这无疑是年度最激动人心的消息之一。一个便宜、强大、还好用的开源模型,能激发出多少创新的火花?我简直不敢想!
好了,不说了,我要去GitHub上给它点Star,然后准备清理一下我的3090,迎接新伙伴了!
快速传送门:
- GitHub仓库:
https://github.com/Tencent-Hunyuan- Hugging Face主页:
https://huggingface.co/tencent
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站



文章评论