模型介绍
Qwen2.5-VL 是阿里云通义千问系列模型中的重要成员,专注于 多模态理解 领域。"VL" 代表 Vision-Language (视觉-语言),表明该模型的核心能力在于理解和处理图像信息,并结合语言进行交互。"chat" 则意味着它具备 对话能力,可以像聊天机器人一样与用户进行多轮对话,解答关于图像内容的问题,执行与图像相关的任务。"v1" 表示这是该模型的第一个公开版本,预示着阿里云在该领域持续投入和迭代的决心。
核心能力
Qwen2.5-VL 模型的核心优势在于其强大的 视觉理解和多模态交互能力,主要体现在以下几个方面:
-
精准的图像描述和理解
模型能够准确地分析图像内容,识别图像中的物体、场景、人物、动作等各种元素,并生成自然流畅的中文描述。它不仅仅停留在简单的物体识别,更能理解图像的 深层含义和上下文。 -
多轮对话交互
Qwen2.5-VL 具备强大的对话能力,可以与用户进行 多轮、自然的对话。用户可以就图像内容提出各种问题,模型能够理解上下文语境,给出准确、有逻辑的回答。例如,用户可以先上传一张图片,然后连续追问图片中的细节、关联信息、甚至进行创意性对话。 -
丰富的视觉任务支持
除了基础的图像描述和问答,Qwen2.5-VL 还支持多种更复杂的视觉任务,例如:- 图像标注 (Image Captioning): 自动生成图像的详细描述文本。
- 视觉问答 (Visual Question Answering, VQA): 回答用户关于图像内容的各种问题。
- 图像推理 (Visual Reasoning): 进行基于图像内容的逻辑推理和判断。
- 场景识别 (Scene Recognition): 识别图像所属的场景类型,例如室内、户外、自然风光等。
- 物体检测 (Object Detection): 识别图像中特定物体的类别和位置。
- 图像编辑指示 (Image Editing Instructions): 理解用户对图像编辑的指令,并指导图像编辑工具进行操作(这项能力可能更偏向未来发展方向)。
- 以及更多... 随着模型的持续迭代,支持的视觉任务类型会更加丰富。
-
优秀的中文语言能力
作为阿里云通义千问系列的一员,Qwen2.5-VL 继承了优秀的中文自然语言处理能力,能够流畅、自然地进行中文对话,更精准地理解中文语境和文化 nuances。 -
强大的技术背景
Qwen2.5-VL 模型基于阿里云强大的 AI 技术积累和基础设施构建,在模型训练、优化、部署等方面都拥有坚实的技术保障。
适用场景
Qwen2.5-VL 模型凭借其强大的视觉理解和对话能力,可以应用于非常广泛的场景,包括但不限于:
- 智能客服: 在电商、客服等场景中,用户可以通过上传图片来描述问题,例如商品瑕疵、操作疑问等,模型可以理解图片内容并提供更精准的解答。
- 内容创作: 辅助内容创作者进行图像素材的选择、图像描述的生成、以及基于图像内容的创意发散。
- 教育学习: 在在线教育领域,可以用于图像相关的知识问答、辅助教学、视觉素材的讲解等。
- 智能家居: 结合智能家居设备,用户可以通过语音或文字上传图片,让智能助手理解场景并执行相应的操作。
- 信息检索: 用户可以通过上传图片进行信息检索,例如识别植物、动物、地标建筑等,获取相关的知识和信息。
- 电商购物: 用户可以上传商品图片进行搜索,或者咨询商品细节,提升购物体验。
- 无障碍辅助: 帮助视觉障碍人士理解周围环境的图像信息。
- 工业质检: 在工业生产线上,用于图像质检,自动识别产品缺陷。
- 安防监控: 辅助安防监控系统进行图像分析,例如异常事件检测、目标追踪等(需考虑数据安全和隐私问题)。
- 科研探索: 为计算机视觉、自然语言处理等领域的研究人员提供强大的工具,加速科研探索。
在线体验地址
目前,阿里云可能尚未提供 Qwen2.5-VL 模型的独立在线体验网站。但是,您可以尝试以下几种方式来体验类似的多模态能力,并关注阿里云通义千问的官方渠道,以获取最新的体验入口信息:
测试图片:

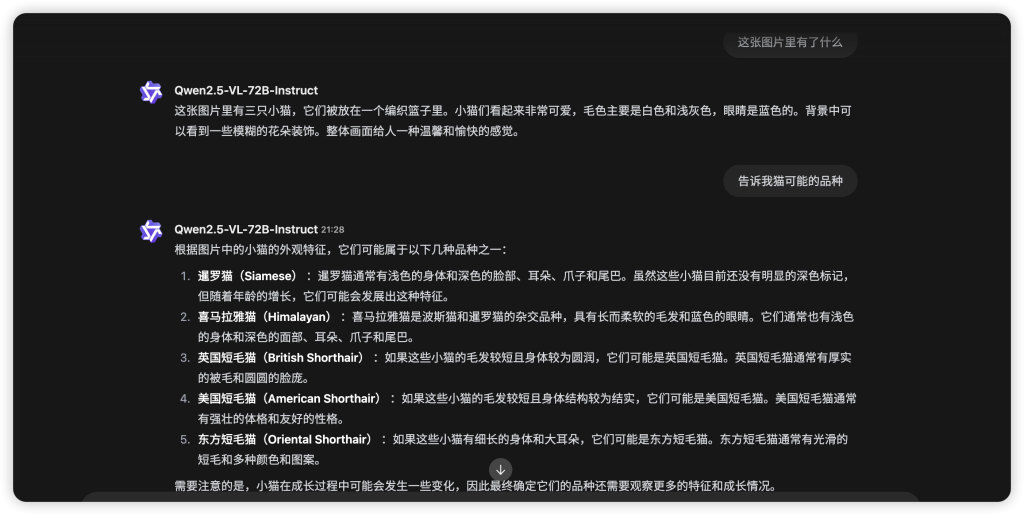
-
通义千问官方网站或App: 访问 体验入口 或下载通义千问 App,查看是否有图像识别或多模态对话的相关功能入口。即使当前版本没有完全对应 Qwen2.5-VL,也可能会有类似的多模态体验功能供您尝试,让您初步感受通义千问系列模型的能力。
-
阿里云产品体验中心: 访问阿里云官方网站,查找 "产品体验中心" 或 "免费试用" 等入口,看是否有提供通义千问或其他 AI 模型的体验机会。阿里云经常会推出新的产品和功能试用活动。
-
关注阿里云官方账号: 关注阿里云官方微信公众号、微博、技术社区等渠道,及时获取最新的产品发布、功能更新和体验活动信息。一旦 Qwen2.5-VL 模型开放体验,官方渠道通常会第一时间发布通知和入口。
请注意,由于模型是新发布的,在线体验入口可能还在准备中或逐步开放。建议您密切关注阿里云官方信息,以获取最准确的体验方式。
API 对接使用
要对接使用 Qwen2.5-VL 模型的 API,您通常需要遵循以下步骤(具体步骤可能会根据阿里云官方文档有所调整,请务必参考最新的官方指南):
-
注册阿里云账号并开通服务: 如果还没有阿里云账号,您需要先注册一个账号。然后,在阿里云控制台中,找到 "人工智能" 或 "机器学习" 相关的服务(例如 "灵骏智算平台"、"PAI 灵骏智能平台" 等),开通相应的服务。根据阿里云的服务目录更新,具体的服务名称可能会有调整。
-
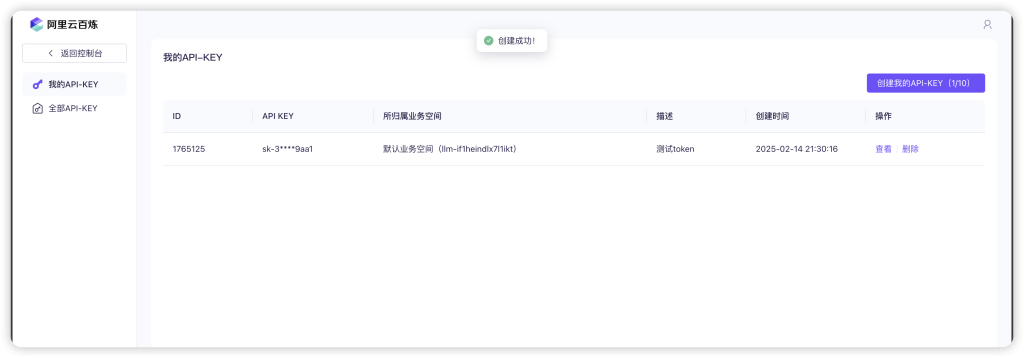
创建 AccessKey: 在阿里云控制台中,创建您的 AccessKey ID 和 AccessKey Secret。这是您进行 API 鉴权的重要凭证,请妥善保管。
-
查找 API 文档: 访问阿里云的 API 文档中心(通常在阿里云官网的 "开发者中心" 或 "文档中心" 栏目下),搜索 "通义千问" 或 "qwen-vl-chat" 等关键词,找到 Qwen2.5-VL 模型的 API 文档。仔细阅读 API 文档,了解 API 的请求方式、参数、返回结果、鉴权方式等详细信息。
-
安装和配置 SDK(可选): 阿里云通常会提供各种编程语言的 SDK(Software Development Kit),例如 Python SDK、Java SDK 等。使用 SDK 可以简化 API 的调用过程。您可以根据您的开发语言选择合适的 SDK 并进行安装和配置。配置过程中通常需要用到您之前创建的 AccessKey 信息。
-
编写代码调用 API: 根据 API 文档和 SDK 的指引,编写代码来调用 Qwen2.5-VL 模型的 API。代码中需要:
- 构造 API 请求: 根据 API 文档的要求,构建请求 URL、请求头、请求参数等。对于图像识别 API,通常需要将图像数据(例如,图片的 URL 或 Base64 编码)作为请求参数发送给 API。
- 进行 API 鉴权: 使用您的 AccessKey 信息进行 API 鉴权,确保请求的合法性。SDK 通常会自动处理鉴权过程。
- 发送 API 请求: 使用 HTTP 库或 SDK 的方法发送 API 请求到阿里云的服务器。
- 处理 API 响应: 接收 API 返回的 JSON 格式的响应数据,解析响应结果,提取模型返回的图像描述、答案等信息。
- 错误处理: 在代码中加入错误处理机制,处理 API 调用可能出现的各种异常情况(例如,网络错误、鉴权失败、API 调用超限等)。
-
测试和优化: 完成代码编写后,进行充分的测试,确保 API 调用能够正常工作,并且能够满足您的应用需求。根据实际情况进行性能优化和错误处理完善。
示例代码(Python 伪代码,仅供参考,实际代码请参考阿里云官方API文档和SDK示例):
import os
from openai import OpenAI
client = OpenAI(
api_key="你的密钥",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-vl-max-latest",
messages=[
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}],
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"
},
},
{"type": "text", "text": "图中描绘的是什么景象?"},
],
},
],
)
print(completion.choices[0].message.content)
重要提示: API 对接涉及阿里云账号开通、鉴权配置、API 文档查阅、代码编写等多个步骤,建议您务必仔细阅读阿里云官方提供的 API 文档和开发者指南,并参考官方 SDK 示例代码,确保正确、安全地对接和使用 API。示例代码仅为演示 API 调用的大致流程,不能直接用于生产环境。请务必根据最新的阿里云官方文档进行开发。
本地部署方式
项目地址:项目地址:
本地部署的主要步骤:
- 选择自己合适的模型: 大型语言模型和多模态模型通常拥有数十亿甚至数百亿的参数,模型文件体积非常庞大,对计算资源(CPU、GPU、内存)和存储空间的要求极高,所以需要根据自己的自身情况 选择对应的模型大小。
提供的基础模型数据量大小,寻找适合自己电脑的模型大小:
更多模型:
-
安装python基础环境: 很多主流的大模型都需要安装自己的基础环境 根据文档上面的说明 构建需要的依赖
-
docker一键部署: 如果只是尝鲜这里推荐使用docker一行命令就可以搞定运行 体验在家部署视觉大模型的乐趣和趣味。
docker run --gpus all --ipc=host --network=host --rm --name qwen2.5 -it qwenllm/qwenvl:2.5-cu121 bash需要注意的: 需要更好的体验 建议开启GPU加速功能 可能驱动缺失无法正常使用GPU加速功能 需要安装驱动和必要的依赖库
总结
阿里云 Qwen2.5-VL 模型是一个非常强大的多模态视觉语言模型,具有广阔的应用前景。虽然本地部署目前不太现实,但通过云端 API 对接,您仍然可以充分利用其强大的能力来构建各种创新的应用。建议您密切关注阿里云官方的最新动态,以便及时获取模型的在线体验入口、API 文档、以及未来可能推出的各种部署方案。


文章评论