一、模型简介
阿里云万相2.1(Wan 2.1) 是通义万相系列的最新多模态视频生成大模型,于2025年1月发布,同年2月25日全面开源。该模型支持文生视频(T2V)和图生视频(I2V),并首次实现中文与英文文本效果动态融合,适用于广告、教育、影视等多领域。
核心亮点
- 多模态能力:支持文本/图像输入生成480P及以上分辨率视频,且可生成动态字幕或特效。
- 创新架构:采用超长上下文训练和参数共享机制,降低训练成本。
- 开源免费:提供两种参数版本(14B、1.3B)的完整代码与权重。
- 高性能表现:在Vbench评测中以86.22%总分超越Sora、Luma、Pika等竞品。
二、安装与本地部署
硬件要求
- T2V-1.3B(1.3亿参数):普通个人电脑可运行,4分钟生成5秒480P视频。
- T2V-14B(140亿参数):需高性能GPU(如NVIDIA A100),支持复杂场景和720P分辨率。
部署步骤
- 从开源平台下载模型:
git clone https://github.com/Wan-Video/Wan2.1.git cd Wan2.1 - 安装依赖:
# Ensure torch >= 2.4.0 pip install -r requirements.txt
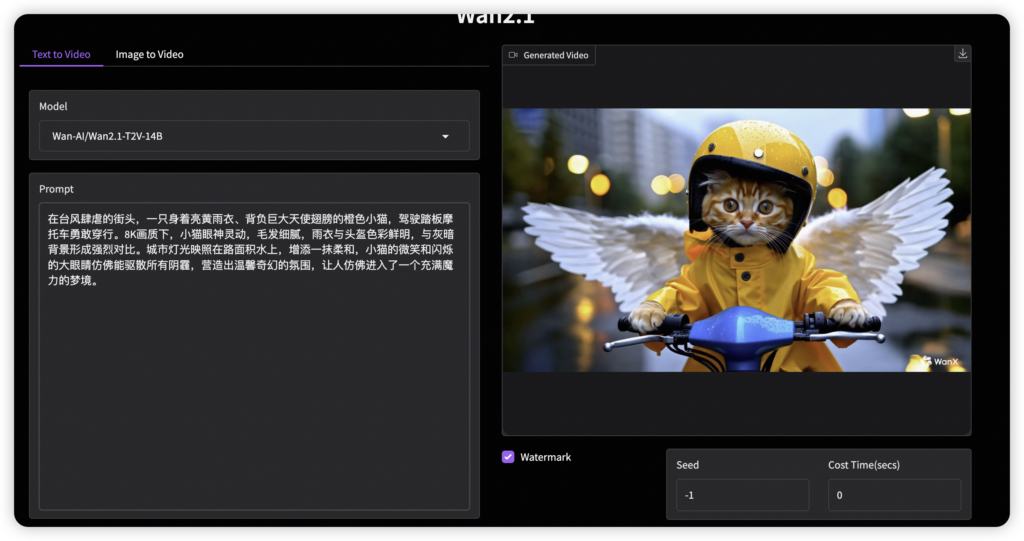
三、项目地址与在线体验
四、与竞品对比
| 特性 | 万相2.1 | Sora(OpenAI) | Pika / Luma |
|---|---|---|---|
| 开源协议 | Apache 2.0 | 闭源 / 付费订阅 | 闭源 |
| 分辨率支持 | 最高720P | 480P(订阅版限制) | 480P-1080P(部分收费) |
| 多语言支持 | 中英双语动态字幕 | 英文为主 | 英文为主 |
| 生成速度 | 1.3B版:4分钟/5秒 | 约10分钟/5秒 | 相似或略慢 |
| 权威评测得分 | Vbench总分86.22% | 未公开 | 未公开 |
万相2.1在复杂运动生成(如流体模拟)、物理建模准确性以及文本-视频关联性方面展示出技术优势。
五、未来展望
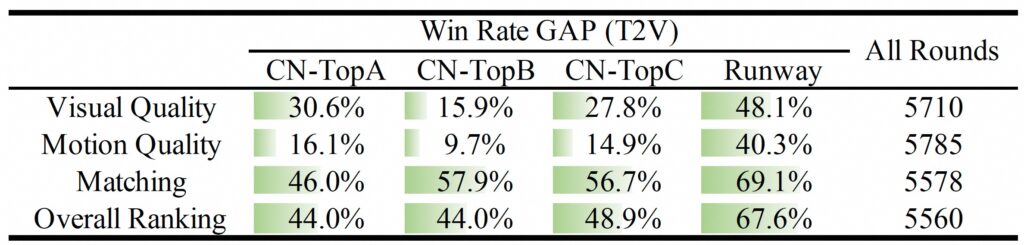
- 文本到视频评估 通过人工评估,提示扩展后生成的结果优于闭源和开源模型的结果。
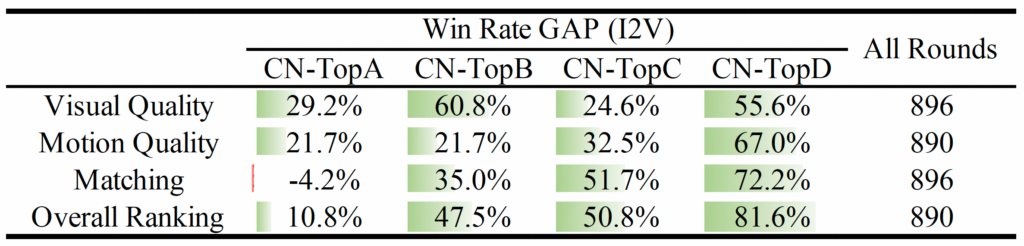
- 图像到视频评估 我们还进行了广泛的手动评估,以评估 Image-to-Video 模型的性能,结果如下表所示。结果清楚地表明,Wan2.1 的性能优于闭源和开源模型。
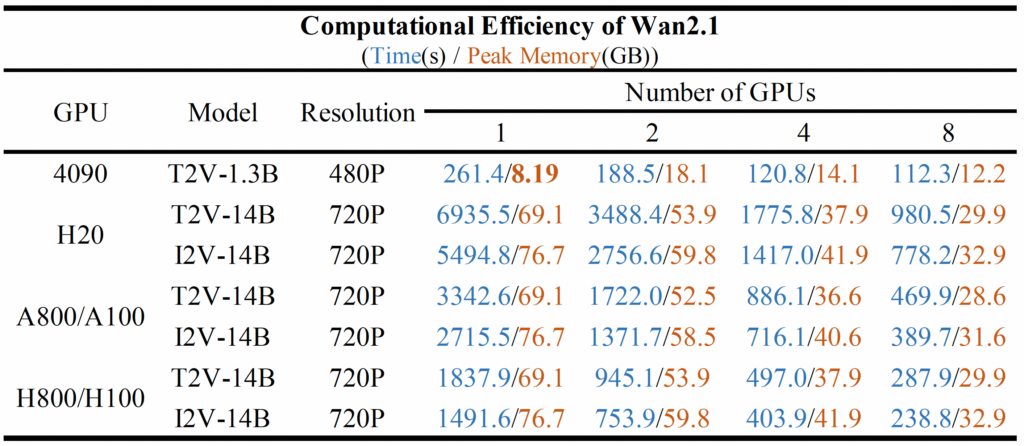
- 不同 GPU 上的计算效率 我们在下表中测试了不同 Wan2.1 模型在不同 GPU 上的计算效率。结果以以下格式显示:总时间 (s) / 峰值 GPU 内存 (GB)。
-
-
此表中显示的测试的参数设置如下: (1) 对于使用 8 个 GPU 的 1.3B 模型,设置 和 ; (2) 对于 1 个 GPU 上的 14B 型号,请使用 ; (3) 对于单个 4090 GPU 上的 1.3B 型号,设置 ; (4) 对于所有测试,都没有应用提示扩展,这意味着没有启用。--ring_size 8--ulysses_size 1--offload_model True--offload_model True --t5_cpu--use_prompt_extend
####💡注意:T2V-14B 比 I2V-14B 慢,因为前者采样 50 步,而后者使用 40 步。
六、未来展望
阿里云计划于2025年第二季度开放训练数据集、视频编辑与转音频功能,并持续投入AI基础设施以巩固行业领先地位。对于开发者而言,其开源策略将加速AI视频生态的创新,尤其在低成本教育工具、文化遗产数字化等领域潜力显著。


文章评论