如果说过去两年AI生图模型最大的痛点是什么,恐怕很多设计师都会把票投给“提笔忘字”。画面再精美,一旦涉及到海报里的标题、示意图里的标注,绝大多数模型给出的都是类似外星文的“鬼画符”。
但在2026年1月14日,这个局面被打破了。智谱AI联合华为,直接甩出了一个王炸——GLM-Image。
这不仅仅是一个新的开源模型,更是一次技术底座的肌肉秀。它是首个完全基于国产算力(华为昇腾Atlas 800T A2芯片)和国产框架(昇思MindSpore)跑通全流程的SOTA级多模态模型。
不用英伟达的卡,能不能训练出国际一流的大模型?GLM-Image就是那个肯定的答案。

不只是画得好,更是“脑子好”
我们先来拆解一下这个模型的“大脑”。
目前的生图模型大多在做选择题:要么选Transformer架构,理解能力强但细节容易崩;要么选Diffusion架构,画质细腻但听不懂复杂人话。
GLM-Image选择了一挑二。它采用了一种极具创新性的“混合动力”架构,总参数量达到了160亿(16B):
前半段是“大脑”: 90亿参数的自回归模型。它继承了GLM-4语言模型的基因,负责听懂你那些复杂的Prompt,规划画面的布局,决定哪里该放人,哪里该写字。
后半段是“画师”: 70亿参数的扩散解码器。它负责把大脑的构思落实到像素上,抠细节、调光影,并且专门引入了一个针对文字编码的模块,死磕汉字生成的准确率。
这种左右互搏的结果就是,它既能理解“在这个海报的右上角写上‘茶悦’两个字”这种精确指令,又能保证画出来的字是一笔一划的方块字,而不是一团乱麻。
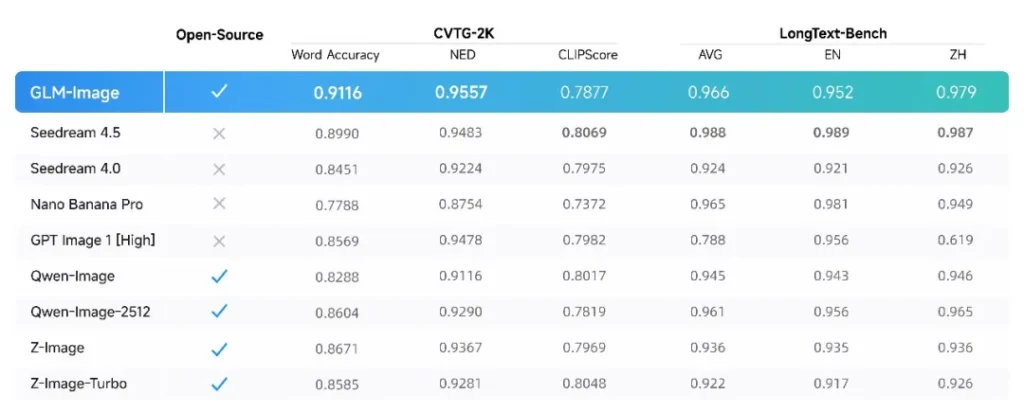
专治“AI文盲症”
在权威的CVTG-2K测试中,GLM-Image的成绩相当吓人。它的归一化编辑距离(NED)达到了0.9557,平均单词准确率超过了91%。
这是什么概念?意味着在复杂的视觉文本生成任务上,它已经是开源模型里的第一名。
对于做电商设计、科普插画、PPT配图的朋友来说,这简直是救命稻草。以前生成一张海报,为了改上面的字,你得在PS里修半天;现在,GLM-Image能直接生成带正确文案的成品,不管是长文本渲染还是复杂的版式设计,它都能拿捏得住。
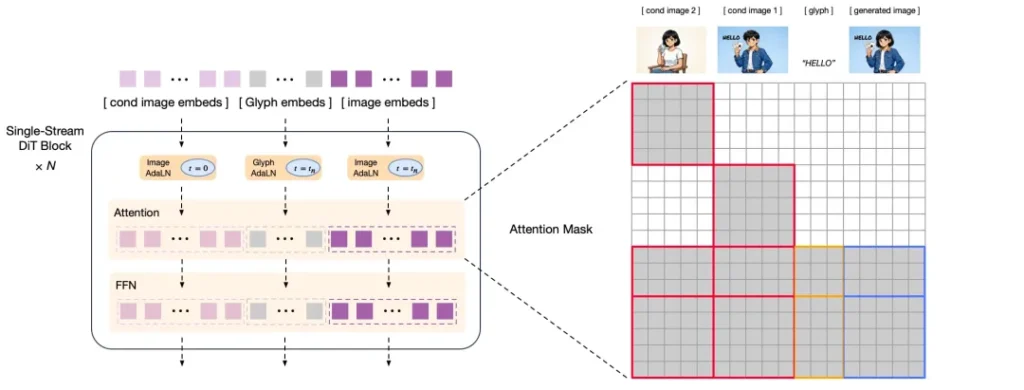
全栈国产化的里程碑
除了模型本身,GLM-Image最让行业振奋的其实是它的出身。
这不仅仅是智谱发了一个模型,更是华为昇腾生态的一次大考。从数据预处理、模型预训练,到后期的微调,全程没有依赖国外的算力硬件。
这证明了国产AI软硬件体系不再只是“能用”,而是已经具备了训练世界一流大模型的能力。在动态图多级流水、多流并行等技术的加持下,国产显卡并没有拖后腿,反而跑出了高性能。
极低的门槛与诚意
最后聊聊落地。智谱这次不仅开源了代码和权重,商业化诚意也给得很足。
通过API调用,生成一张图的成本仅为0.1元。相比于动辄几毛甚至更贵的竞品,这个价格基本就是要把高质量生图变成像水电一样的基础服务。而且,它原生支持从1024到2048的任意分辨率生成,不需要重新训练,拿来就能用。

目前,GLM-Image已经在GitHub和Hugging Face上开源。对于开发者和企业来说,这意味着你现在就可以在国产硬件上,部署一套懂中文、能写字、画质顶级的生图系统。
GLM-Image的出现,或许标志着国产AI大模型正式进入了“里子面子全都要”的新阶段。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


