就在2026年的第一个月,具身智能圈子里发生了一件足以让很多技术团队重新审视路线图的事。
长期以来,美国的Physical Intelligence公司凭借Pi0系列模型,稳稳占据着具身智能领域的“铁王座”。但在1月12日更新的RoboChallenge Table30榜单上,一个来自中国的名字——千寻智能(Spirit AI),凭借Spirit v1.5模型,硬生生把这个基准线给“撞”开了。
综合得分66.09,任务成功率50.33%。这两个数字看似冰冷,却意味着它是全球首个在真机实测中击败基准模型Pi0.5的国产模型,更是首个将复杂任务成功率拉升到50%以上的分水岭级产品。
这一仗赢得并不轻松,因为RoboChallenge不是那种可以在模拟器里跑分的“纸面考场”。

真刀真枪的“修罗场”
为了理解Spirit v1.5的含金量,我们得先看看RoboChallenge在考什么。
这个评测平台由Dexmal、Hugging Face和北京智源等机构联合发起,它的核心逻辑极其残酷:真机实测。没有完美的仿真物理引擎,没有上帝视角。模型必须控制真实的单臂或双臂机器人,去完成“Table30”任务集里的30项日常操作——从插花、做三明治到贴胶带。
在真实世界里,光照会变,物体会被遮挡,刚体接触会有不可预测的滑移。Pi0.5此前的得分是61.84,成功率42.67%,这已经是很多团队眼中的天花板。而Spirit v1.5不仅跨过了这个天花板,还把成功率拉开了一个身位。
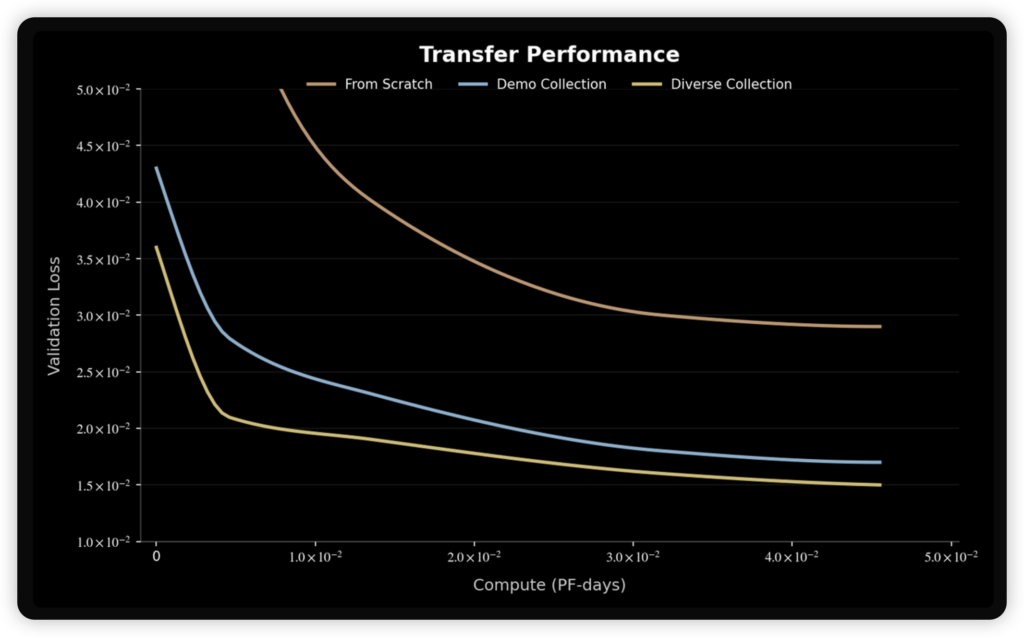
技术复盘:为什么“脏”数据反而更强?
如果只是堆算力、堆参数,Spirit v1.5恐怕很难实现这种超越。千寻智能这次之所以能赢,核心在于他们对“数据”的理解发生了一个本质的转变。
在这个行业里,大家习惯把机器人当成“温室里的花朵”。为了训练模型,传统做法是采集极其干净的实验室数据:严格控制环境,操作员按照写好的脚本,完美地演示一遍动作。这种数据喂出来的模型,确实学得快,但一出实验室就容易“水土不服”。
Spirit v1.5走了一条野路子。
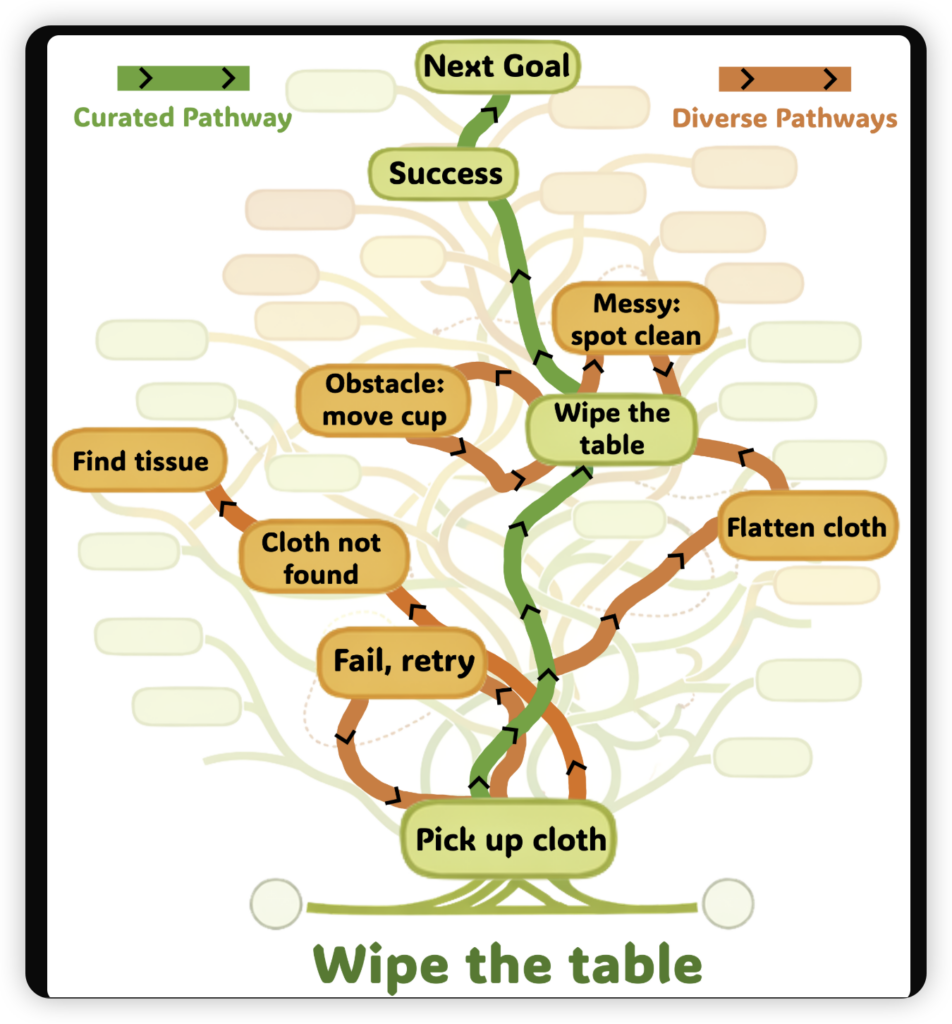
团队放弃了那种精雕细琢的脚本,转而采用一种“多样化”采集范式。他们只给操作员一个高层次的目标(比如“把厨房收拾干净”),至于怎么收拾、中间是不是手滑了一下、是不是把抹布掉地上了又捡起来,全都不管。
这就产生了一堆包含失败、纠正和自然停顿的“脏数据”。
但恰恰是这些不完美的数据,教会了模型真正的物理常识。模型不再是在背诵动作,而是在学习如何应对意外,如何处理遮挡,如何在长时序任务中自我修正。内部实验数据显示,用这种新范式训练出来的模型,在学习全新任务时,所需的迭代次数直接减少了40%。
这就像学骑自行车,在平坦塑胶跑道上练一百遍,不如在坑洼泥地里摔几次学得扎实。
走出实验室:宁德时代的“小墨”
如果说榜单是期末考试,那进工厂就是毕业工作。
Spirit v1.5并没有停留在GitHub的代码库里。搭载该模型的人形机器人“小墨”,已经跑到了宁德时代的电池PACK生产线上“打工”。
这不是作秀式的巡逻,而是去干高压测试插头插接这种精细活。在电池产线的高危环境下,任何一次失误都可能导致安全事故。官方数据显示,Spirit v1.5在这里跑出了超过99%的插接成功率,效率是人工的三倍。

这种工业级的稳定性,才是对“50.33%榜单成功率”最好的注脚。它证明了那些在“脏数据”里摸爬滚打学来的本事,确实能扛得住现实世界的拷打。
开源背后的阳谋
更值得玩味的是,千寻智能选择了把Spirit v1.5的权重和核心代码全部开源。
这不仅仅是一种技术自信。在RoboChallenge榜单上,我们看到排名前列的几乎都是开源模型(包括第三名的国产模型WALL-OSS)。这释放了一个信号:具身智能正在经历大语言模型两年前经历过的阶段——开源正在成为推动技术进化的核心引擎。
通过开源,Spirit AI不仅让全球开发者验证了其成绩的真实性,更无形中制定了新的行业标准。当所有人都在用你的架构、跑你的代码时,你就成了新的基准。
结语
Spirit v1.5的登顶,标志着国产具身智能模型已经走过了“跟着跑”的阶段,正式进入了“领着跑”的核心圈。
但这远不是终点。50%的成功率意味着机器人仍有一半的概率会把三明治做砸。但至少,不管是通过“多样化数据”这种反直觉的技术路线,还是通过开源共建的生态打法,我们已经找到了一条让机器人真正走进物理世界的清晰路径。
这一次,中国模型没有缺席,甚至跑在了最前面。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


