如果说2024年是AI视频的“开眼看世界”,那么2026年开春,字节跳动刚刚发布的 Seedance 2.0,可能真的要把摄影机和剪辑软件送进博物馆了。
这两天科技圈最炸裂的消息,莫过于字节旗下的“即梦”平台正式上线了这款新模型。在实测了一整天后,我得出一个结论:这不仅仅是画质的提升,而是AI终于听懂了什么叫“叙事”。
以前我们玩AI视频,像是在买彩票,“抽卡”全看运气;而Seedance 2.0给我的感觉,是我终于坐上了导演椅。
不止是生成,而是“精准复刻”
市面上大多数模型(包括Sora和可灵)的核心逻辑还是“脑补”。你给一段文字,它还你一段视频,但细节往往不可控。
Seedance 2.0最狠的一招叫做 “多模态参考”。
这东西有多夸张?它允许你一次性甩给它 12个参考文件。你可以上传9张图片定角色和画风,3段视频定运镜和动态,再加3段音频定节奏。
想象一下这个场景:你有一张自己设计的动漫角色图,又找了一段真人舞蹈的视频。在过去,让二次元角色跳出真人的舞步需要复杂的动作捕捉和渲染。现在?你在提示词里“@”一下图片和视频,Seedance 2.0就能直接把真人的动作“移植”到动漫角色身上,连裙摆的物理飘动都符合重力逻辑。
这不是“生成”,这是工业级的“复刻”。

真正解决“声画游离”的顽疾
玩过AI视频的朋友都知道,最让人出戏的往往不是画面,而是声音。以前的流程是先生成无声视频,再找AI配音,最后手动对口型,结果往往是“嘴动嘴的,声发声的”,塑料感极强。
Seedance 2.0底层架构换成了 双分支扩散变换器 (Dual-branch DiT)。别被技术名词吓到,简单说就是它有“两只手”,一只手画画,一只手谱曲,而且是同时进行。
这就实现了真正的 原生音画同步。我在测试中输入了一段对话音频,生成的人物口型竟然能做到毫秒级匹配,就连背景里的风声、脚步声都能卡在正确的画面节奏上。那种“AI配音感”大幅削弱,临场感瞬间拉满。
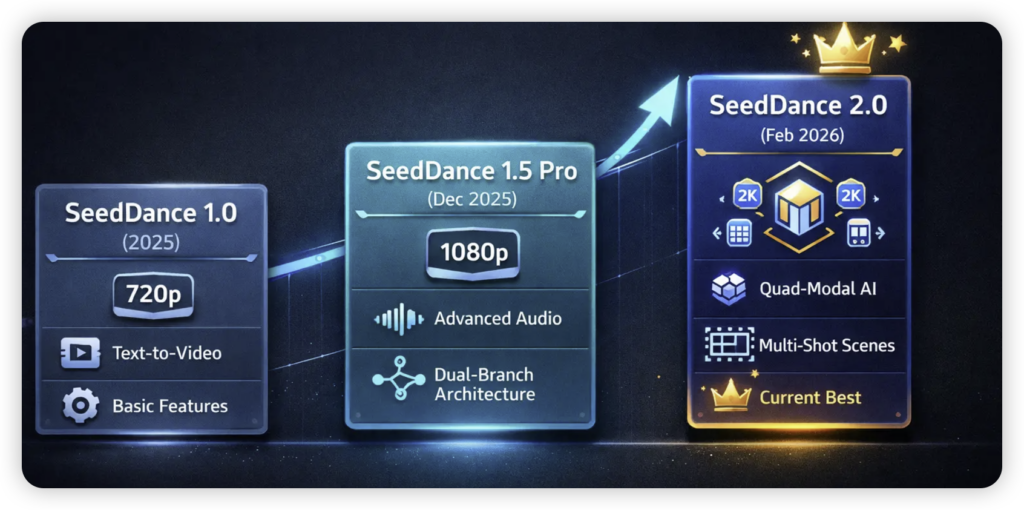
告别“PPT转场”,这才是电影感
很多AI视频模型只能生成单镜头,一旦涉及多镜头切换,角色长相就变了(俗称“脸崩”),场景也接不上。
Seedance 2.0显然是冲着影视制作去的。它能理解什么叫“全景接中景再接特写”。你只需要描述情节,它会自动拆解分镜。
最让我惊讶的是它的 一致性控制。在一段长达15秒的视频里,无论镜头怎么推拉摇移,角色的衣服纹理、面部特征甚至光影逻辑都保持得非常稳定。对于做短剧、做广告的人来说,这意味着以前需要几周、几十人团队磨出来的片子,现在可能只需要一个人、一下午、几块钱的算力成本。
还有局限吗?当然有
吹了这么多,咱们也得客观看看它的短板。
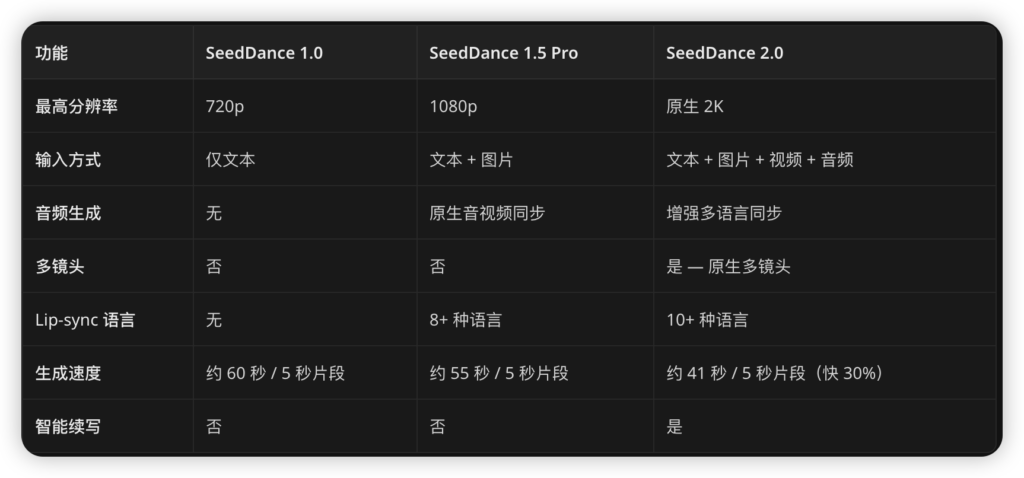
虽然官方宣称生成速度提升了10倍,但在生成高质量、多参考文件的2K视频时,等待时间依然不算短,而且积分消耗确实肉疼。另外,虽然它在大的物理规律上表现出色,但在处理画面中细小的文字或极端复杂的动态元素时,偶尔还是会翻车。
当然,如果你想用它复活某个不可描述的知名人物,劝你趁早打消念头,字节的审核机制依然严得像铁桶一样。
写在最后
如果要用一句话总结Seedance 2.0,我会说:它把AI视频从“技术炫技”拉回了“内容创作”。
以前我们比拼的是谁的模型生成的浪花更真实,现在竞争的维度变了——当制作门槛被无限拉低,短剧的制作成本从几千块降到几块钱时,真正值钱的不再是你会不会剪辑,而是你脑子里有没有那个绝妙的故事。
Sora还在模拟物理世界,可灵在死磕运动控制,而Seedance 2.0已经把导筒递到了你手里。
如果你是创作者,现在也许是入局的最好时刻;如果你是传统影视后期,嗯……或许该去看看“即梦”的说明书了。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


