2026年的开年大戏,比我想象中来得更早一些。
就在1月30日,当大家还在讨论GPT-5.2的逻辑推理是否已经触顶时,商汤科技悄无声息地丢出了一枚重磅炸弹:SenseNova-MARS。这不是又一个只会“看图说话”的多模态模型,而是一个能自主思考、会用工具、甚至有点“侦探直觉”的智能体。
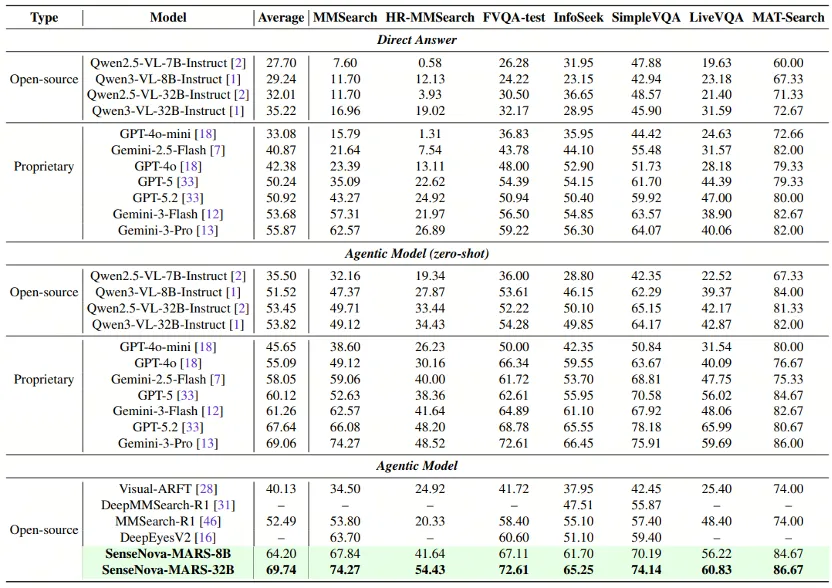
最让圈内人咋舌的不是它的技术架构,而是那个刺眼的分数——在多模态搜索与推理的综合平均分上,它拿下了69.74分。
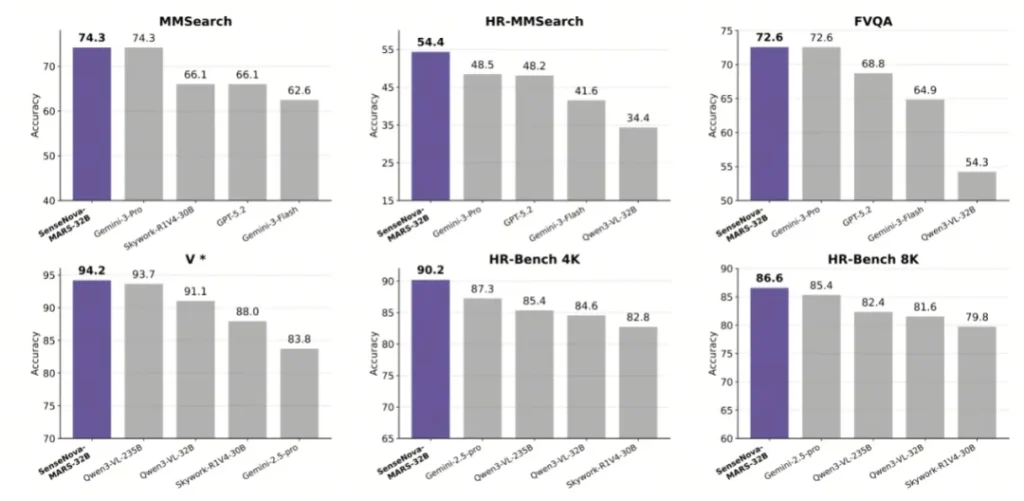
这个数字意味着什么?意味着它在纸面实力上,压过了谷歌的Gemini-3-Pro(69.06分),也超过了OpenAI的GPT-5.2(67.64分)。而且,它还是开源的。
不止是“看”,它学会了“查”
过去我们玩多模态模型(VLM),流程通常是这样的:你扔给AI一张图,问它“这是哪?”,AI依靠训练时记住的知识库,运气好能蒙对,运气不好就开始一本正经地胡说八道。
SenseNova-MARS的逻辑完全不同。它更像是一个随身携带了放大镜和百科全书的福尔摩斯。
商汤这次主打的概念叫“自主规划”与“多工具协作”。简单来说,当这个模型面对一个复杂问题时,它不再是靠“猜”,而是靠“查”。它能像人类一样,把一个大问题拆解成几个步骤:
- 观察:看到图里的物体。
- 规划:思考需要什么信息才能回答问题。
- 行动:调用工具去获取信息(比如切割图片、搜索网络)。
- 反馈:根据搜到的结果修正答案。
举个很现实的例子:给它一张F1赛车手的照片,问“这个车手所在的车队成立于哪一年?”。
普通模型可能会盯着赛车服上的模糊Logo发呆。但SenseNova-MARS会先调用图像裁剪工具,把那个只占画面不到5%的微小Logo切出来放大;识别清楚后,立刻启动图文搜索,去网上查这个Logo对应的品牌;确认品牌是某某车队后,再进行二次搜索查询该车队的成立年份。
这套“识别-查询-计算”的连招,就是它得分比GPT-5.2高的秘诀。特别是在HR-MMSearch(高清细节搜索)这项被誉为“AI界奥林匹克”的测试中,它拿到了54.43分,远超那些虽然参数巨大但只会“单次直觉推理”的闭源模型。
怎么练出“直觉”的?
要把AI训练成这样并不容易。这就好比教一个学生,光让他背书(预训练)是不够的,你得让他去实习,去解决实际问题。
商汤团队这次采用了一种双阶段的训练策略,非常有意思:
第一阶段叫“打基础”。他们利用自动化引擎合成了一大堆逻辑严密的高难度案例,像是给AI编了一套《侦探入门指南》,强制它学习基础的工具使用逻辑。
第二阶段叫“练实战”。这是拉开差距的关键。他们引入了强化学习,配合一种名为BN-GSPO的算法。这就好比把AI扔进模拟实战演练,做对了给奖励,做错了没糖吃。久而久之,模型就培养出了一种“工具使用直觉”。它不再是机械地调用工具,而是知道在什么情况下该搜图,什么情况下该搜字,甚至知道什么时候该停下来思考。
给开发者的一份大礼
对于我们在AI圈摸爬滚打的人来说,SenseNova-MARS最吸引人的点在于它的开源。
商汤这次非常实在,直接放出了8B(80亿参数)和32B(320亿参数)两个版本。
- 8B版本:轻量级,适合显存有限的开发者,甚至有望在高端边缘设备上跑起来。
- 32B版本:满血版,那个吊打GPT-5.2的成绩就是它跑出来的,适合需要极致推理能力的科研或商业项目。

这意味着,不管是做商业情报分析(自动从峰会照片里扒竞品信息),还是做复杂的学术图表验证,我们现在都有了一个SOTA(当前最优)级别的开源底座可用。模型权重、训练代码、甚至合成数据集,全都在Hugging Face和GitHub上公开了。
结语
SenseNova-MARS的出现,某种程度上标志着多模态AI正在从“感知时代”跨入“行动时代”。
以前我们惊叹于AI能“看懂”一张图,现在我们开始要求AI能“搞定”图里的事。虽然69.74分距离满分还有很长的路要走,但在开源领域,商汤确实把天花板向上狠狠顶了一截。
如果你手头有显卡,不妨去下载那个32B的版本跑跑看。说不定,你电脑里现在就住着一个比GPT-5.2还要精明的“数字侦探”。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站


